 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025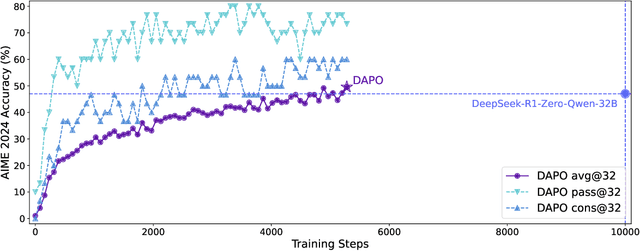

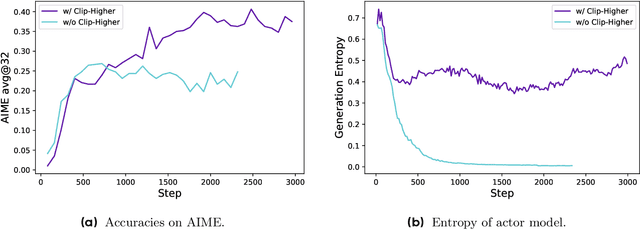

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
TT-GaussOcc: Test-Time Compute for Self-Supervised Occupancy Prediction via Spatio-Temporal Gaussian Splatting
Mar 11, 2025



Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense voxel decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and such models often fail to adapt to varying voxel resolutions or new classes without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-GaussOcc. Our approach incrementally optimizes time-aware 3D Gaussians instantiated from raw sensor streams at runtime, enabling voxelization at arbitrary user-specified resolution. Specifically, TT-GaussOcc operates in a "lift-move-voxel" symphony: we first "lift" surrounding-view semantics obtained from 2D vision foundation models (VLMs) to instantiate Gaussians at non-empty 3D space; Next, we "move" dynamic Gaussians from previous frames along estimated Gaussian scene flow to complete appearance and eliminate trailing artifacts of fast-moving objects, while accumulating static Gaussians to enforce temporal consistency; Finally, we mitigate inherent noises in semantic predictions and scene flow vectors by periodically smoothing neighboring Gaussians during optimization, using proposed trilateral RBF kernels that jointly consider color, semantic, and spatial affinities. The historical static and current dynamic Gaussians are then combined and voxelized to generate occupancy prediction. Extensive experiments on Occ3D and nuCraft with varying voxel resolutions demonstrate that TT-GaussOcc surpasses self-supervised baselines by 46% on mIoU without any offline training, and supports finer voxel resolutions at 2.6 FPS inference speed.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
Muon is Scalable for LLM Training
Feb 24, 2025Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves $\sim\!2\times$ computational efficiency compared to AdamW with compute optimal training. Based on these improvements, we introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. Our model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models. We open-source our distributed Muon implementation that is memory optimal and communication efficient. We also release the pretrained, instruction-tuned, and intermediate checkpoints to support future research.
MaZO: Masked Zeroth-Order Optimization for Multi-Task Fine-Tuning of Large Language Models
Feb 17, 2025



Large language models have demonstrated exceptional capabilities across diverse tasks, but their fine-tuning demands significant memory, posing challenges for resource-constrained environments. Zeroth-order (ZO) optimization provides a memory-efficient alternative by eliminating the need for backpropagation. However, ZO optimization suffers from high gradient variance, and prior research has largely focused on single-task learning, leaving its application to multi-task learning unexplored. Multi-task learning is crucial for leveraging shared knowledge across tasks to improve generalization, yet it introduces unique challenges under ZO settings, such as amplified gradient variance and collinearity. In this paper, we present MaZO, the first framework specifically designed for multi-task LLM fine-tuning under ZO optimization. MaZO tackles these challenges at the parameter level through two key innovations: a weight importance metric to identify critical parameters and a multi-task weight update mask to selectively update these parameters, reducing the dimensionality of the parameter space and mitigating task conflicts. Experiments demonstrate that MaZO achieves state-of-the-art performance, surpassing even multi-task learning methods designed for first-order optimization.
Connector-S: A Survey of Connectors in Multi-modal Large Language Models
Feb 17, 2025



With the rapid advancements in multi-modal large language models (MLLMs), connectors play a pivotal role in bridging diverse modalities and enhancing model performance. However, the design and evolution of connectors have not been comprehensively analyzed, leaving gaps in understanding how these components function and hindering the development of more powerful connectors. In this survey, we systematically review the current progress of connectors in MLLMs and present a structured taxonomy that categorizes connectors into atomic operations (mapping, compression, mixture of experts) and holistic designs (multi-layer, multi-encoder, multi-modal scenarios), highlighting their technical contributions and advancements. Furthermore, we discuss several promising research frontiers and challenges, including high-resolution input, dynamic compression, guide information selection, combination strategy, and interpretability. This survey is intended to serve as a foundational reference and a clear roadmap for researchers, providing valuable insights into the design and optimization of next-generation connectors to enhance the performance and adaptability of MLLMs.
QuZO: Quantized Zeroth-Order Fine-Tuning for Large Language Models
Feb 17, 2025



Language Models (LLMs) are often quantized to lower precision to reduce the memory cost and latency in inference. However, quantization often degrades model performance, thus fine-tuning is required for various down-stream tasks. Traditional fine-tuning methods such as stochastic gradient descent and Adam optimization require backpropagation, which are error-prone in the low-precision settings. To overcome these limitations, we propose the Quantized Zeroth-Order (QuZO) framework, specifically designed for fine-tuning LLMs through low-precision (e.g., 4- or 8-bit) forward passes. Our method can avoid the error-prone low-precision straight-through estimator, and utilizes optimized stochastic rounding to mitigate the increased bias. QuZO simplifies the training process, while achieving results comparable to first-order methods in ${\rm FP}8$ and superior accuracy in ${\rm INT}8$ and ${\rm INT}4$ training. Experiments demonstrate that low-bit training QuZO achieves performance comparable to MeZO optimization on GLUE, Multi-Choice, and Generation tasks, while reducing memory cost by $2.94 \times$ in LLaMA2-7B fine-tuning compared to quantized first-order methods.
Scalable Back-Propagation-Free Training of Optical Physics-Informed Neural Networks
Feb 17, 2025Physics-informed neural networks (PINNs) have shown promise in solving partial differential equations (PDEs), with growing interest in their energy-efficient, real-time training on edge devices. Photonic computing offers a potential solution to achieve this goal because of its ultra-high operation speed. However, the lack of photonic memory and the large device sizes prevent training real-size PINNs on photonic chips. This paper proposes a completely back-propagation-free (BP-free) and highly salable framework for training real-size PINNs on silicon photonic platforms. Our approach involves three key innovations: (1) a sparse-grid Stein derivative estimator to avoid the BP in the loss evaluation of a PINN, (2) a dimension-reduced zeroth-order optimization via tensor-train decomposition to achieve better scalability and convergence in BP-free training, and (3) a scalable on-chip photonic PINN training accelerator design using photonic tensor cores. We validate our numerical methods on both low- and high-dimensional PDE benchmarks. Through circuit simulation based on real device parameters, we further demonstrate the significant performance benefit (e.g., real-time training, huge chip area reduction) of our photonic accelerator.
DCT-Mamba3D: Spectral Decorrelation and Spatial-Spectral Feature Extraction for Hyperspectral Image Classification
Feb 04, 2025



Hyperspectral image classification presents challenges due to spectral redundancy and complex spatial-spectral dependencies. This paper proposes a novel framework, DCT-Mamba3D, for hyperspectral image classification. DCT-Mamba3D incorporates: (1) a 3D spectral-spatial decorrelation module that applies 3D discrete cosine transform basis functions to reduce both spectral and spatial redundancy, enhancing feature clarity across dimensions; (2) a 3D-Mamba module that leverages a bidirectional state-space model to capture intricate spatial-spectral dependencies; and (3) a global residual enhancement module that stabilizes feature representation, improving robustness and convergence. Extensive experiments on benchmark datasets show that our DCT-Mamba3D outperforms the state-of-the-art methods in challenging scenarios such as the same object in different spectra and different objects in the same spectra.
PolaFormer: Polarity-aware Linear Attention for Vision Transformers
Jan 25, 2025Linear attention has emerged as a promising alternative to softmax-based attention, leveraging kernelized feature maps to reduce complexity from quadratic to linear in sequence length. However, the non-negative constraint on feature maps and the relaxed exponential function used in approximation lead to significant information loss compared to the original query-key dot products, resulting in less discriminative attention maps with higher entropy. To address the missing interactions driven by negative values in query-key pairs, we propose a polarity-aware linear attention mechanism that explicitly models both same-signed and opposite-signed query-key interactions, ensuring comprehensive coverage of relational information. Furthermore, to restore the spiky properties of attention maps, we provide a theoretical analysis proving the existence of a class of element-wise functions (with positive first and second derivatives) that can reduce entropy in the attention distribution. For simplicity, and recognizing the distinct contributions of each dimension, we employ a learnable power function for rescaling, allowing strong and weak attention signals to be effectively separated. Extensive experiments demonstrate that the proposed PolaFormer improves performance on various vision tasks, enhancing both expressiveness and efficiency by up to 4.6%.