 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-organ all-in-one parallel compressed sensing magnetic resonance imaging
May 07, 2025Recent advances in deep learning-based parallel compressed sensing magnetic resonance imaging (p-CSMRI) have significantly improved reconstruction quality. However, current p-CSMRI methods often require training separate deep neural network (DNN) for each organ due to anatomical variations, creating a barrier to developing generalized medical image reconstruction systems. To address this, we propose CAPNet (cross-organ all-in-one deep unfolding p-CSMRI network), a unified framework that implements a p-CSMRI iterative algorithm via three specialized modules: auxiliary variable module, prior module, and data consistency module. Recognizing that p-CSMRI systems often employ varying sampling ratios for different organs, resulting in organ-specific artifact patterns, we introduce an artifact generation submodule, which extracts and integrates artifact features into the data consistency module to enhance the discriminative capability of the overall network. For the prior module, we design an organ structure-prompt generation submodule that leverages structural features extracted from the segment anything model (SAM) to create cross-organ prompts. These prompts are strategically incorporated into the prior module through an organ structure-aware Mamba submodule. Comprehensive evaluations on a cross-organ dataset confirm that CAPNet achieves state-of-the-art reconstruction performance across multiple anatomical structures using a single unified model. Our code will be published at https://github.com/shibaoshun/CAPNet.
HeRB: Heterophily-Resolved Structure Balancer for Graph Neural Networks
Apr 24, 2025Recent research has witnessed the remarkable progress of Graph Neural Networks (GNNs) in the realm of graph data representation. However, GNNs still encounter the challenge of structural imbalance. Prior solutions to this problem did not take graph heterophily into account, namely that connected nodes process distinct labels or features, thus resulting in a deficiency in effectiveness. Upon verifying the impact of heterophily on solving the structural imbalance problem, we propose to rectify the heterophily first and then transfer homophilic knowledge. To the end, we devise a method named HeRB (Heterophily-Resolved Structure Balancer) for GNNs. HeRB consists of two innovative components: 1) A heterophily-lessening augmentation module which serves to reduce inter-class edges and increase intra-class edges; 2) A homophilic knowledge transfer mechanism to convey homophilic information from head nodes to tail nodes. Experimental results demonstrate that HeRB achieves superior performance on two homophilic and six heterophilic benchmark datasets, and the ablation studies further validate the efficacy of two proposed components.
Flying through cluttered and dynamic environments with LiDAR
Apr 24, 2025



Navigating unmanned aerial vehicles (UAVs) through cluttered and dynamic environments remains a significant challenge, particularly when dealing with fast-moving or sudden-appearing obstacles. This paper introduces a complete LiDAR-based system designed to enable UAVs to avoid various moving obstacles in complex environments. Benefiting the high computational efficiency of perception and planning, the system can operate in real time using onboard computing resources with low latency. For dynamic environment perception, we have integrated our previous work, M-detector, into the system. M-detector ensures that moving objects of different sizes, colors, and types are reliably detected. For dynamic environment planning, we incorporate dynamic object predictions into the integrated planning and control (IPC) framework, namely DynIPC. This integration allows the UAV to utilize predictions about dynamic obstacles to effectively evade them. We validate our proposed system through both simulations and real-world experiments. In simulation tests, our system outperforms state-of-the-art baselines across several metrics, including success rate, time consumption, average flight time, and maximum velocity. In real-world trials, our system successfully navigates through forests, avoiding moving obstacles along its path.
FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding
Apr 14, 2025



We introduce FUSION, a family of multimodal large language models (MLLMs) with a fully vision-language alignment and integration paradigm. Unlike existing methods that primarily rely on late-stage modality interaction during LLM decoding, our approach achieves deep, dynamic integration throughout the entire processing pipeline. To this end, we propose Text-Guided Unified Vision Encoding, incorporating textual information in vision encoding to achieve pixel-level integration. We further design Context-Aware Recursive Alignment Decoding that recursively aggregates visual features conditioned on textual context during decoding, enabling fine-grained, question-level semantic integration. To guide feature mapping and mitigate modality discrepancies, we develop Dual-Supervised Semantic Mapping Loss. Additionally, we construct a Synthesized Language-Driven Question-Answer (QA) dataset through a new data synthesis method, prioritizing high-quality QA pairs to optimize text-guided feature integration. Building on these foundations, we train FUSION at two scales-3B, 8B-and demonstrate that our full-modality integration approach significantly outperforms existing methods with only 630 vision tokens. Notably, FUSION 3B surpasses Cambrian-1 8B and Florence-VL 8B on most benchmarks. FUSION 3B continues to outperform Cambrian-1 8B even when limited to 300 vision tokens. Our ablation studies show that FUSION outperforms LLaVA-NeXT on over half of the benchmarks under same configuration without dynamic resolution, highlighting the effectiveness of our approach. We release our code, model weights, and dataset. https://github.com/starriver030515/FUSION
Probabilistic QoS Metric Forecasting in Delay-Tolerant Networks Using Conditional Diffusion Models on Latent Dynamics
Apr 09, 2025



Active QoS metric prediction, commonly employed in the maintenance and operation of DTN, could enhance network performance regarding latency, throughput, energy consumption, and dependability. Naturally formulated as a multivariate time series forecasting problem, it attracts substantial research efforts. Traditional mean regression methods for time series forecasting cannot capture the data complexity adequately, resulting in deteriorated performance in operational tasks in DTNs such as routing. This paper formulates the prediction of QoS metrics in DTN as a probabilistic forecasting problem on multivariate time series, where one could quantify the uncertainty of forecasts by characterizing the distribution of these samples. The proposed approach hires diffusion models and incorporates the latent temporal dynamics of non-stationary and multi-mode data into them. Extensive experiments demonstrate the efficacy of the proposed approach by showing that it outperforms the popular probabilistic time series forecasting methods.
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Mar 31, 2025
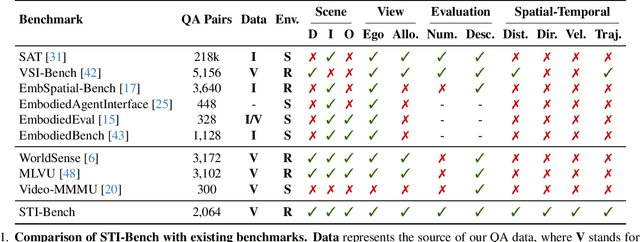

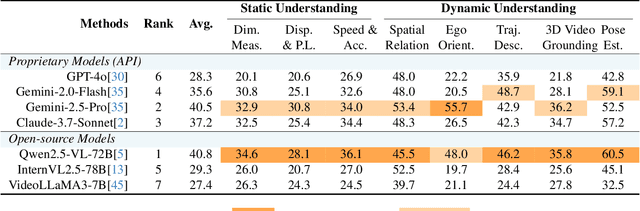
The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models' Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs' spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Mar 27, 2025



In recent years, the rapid development of large reasoning models has resulted in the saturation of existing benchmarks for evaluating mathematical reasoning, highlighting the urgent need for more challenging and rigorous evaluation frameworks. To address this gap, we introduce OlymMATH, a novel Olympiad-level mathematical benchmark, designed to rigorously test the complex reasoning capabilities of LLMs. OlymMATH features 200 meticulously curated problems, each manually verified and available in parallel English and Chinese versions. The problems are systematically organized into two distinct difficulty tiers: (1) AIME-level problems (easy) that establish a baseline for mathematical reasoning assessment, and (2) significantly more challenging problems (hard) designed to push the boundaries of current state-of-the-art models. In our benchmark, these problems span four core mathematical fields, each including a verifiable numerical solution to enable objective, rule-based evaluation. Empirical results underscore the significant challenge presented by OlymMATH, with state-of-the-art models including DeepSeek-R1 and OpenAI's o3-mini demonstrating notably limited accuracy on the hard subset. Furthermore, the benchmark facilitates comprehensive bilingual assessment of mathematical reasoning abilities-a critical dimension that remains largely unaddressed in mainstream mathematical reasoning benchmarks. We release the OlymMATH benchmark at the STILL project: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.
MMCR: Benchmarking Cross-Source Reasoning in Scientific Papers
Mar 21, 2025



Fully comprehending scientific papers by machines reflects a high level of Artificial General Intelligence, requiring the ability to reason across fragmented and heterogeneous sources of information, presenting a complex and practically significant challenge. While Vision-Language Models (VLMs) have made remarkable strides in various tasks, particularly those involving reasoning with evidence source from single image or text page, their ability to use cross-source information for reasoning remains an open problem. This work presents MMCR, a high-difficulty benchmark designed to evaluate VLMs' capacity for reasoning with cross-source information from scientific papers. The benchmark comprises 276 high-quality questions, meticulously annotated by humans across 7 subjects and 10 task types. Experiments with 18 VLMs demonstrate that cross-source reasoning presents a substantial challenge for existing models. Notably, even the top-performing model, GPT-4o, achieved only 48.55% overall accuracy, with only 20% accuracy in multi-table comprehension tasks, while the second-best model, Qwen2.5-VL-72B, reached 39.86% overall accuracy. Furthermore, we investigated the impact of the Chain-of-Thought (CoT) technique on cross-source reasoning and observed a detrimental effect on small models, whereas larger models demonstrated substantially enhanced performance. These results highlight the pressing need to develop VLMs capable of effectively utilizing cross-source information for reasoning.
Memory-enhanced Retrieval Augmentation for Long Video Understanding
Mar 12, 2025Retrieval-augmented generation (RAG) shows strong potential in addressing long-video understanding (LVU) tasks. However, traditional RAG methods remain fundamentally limited due to their dependence on explicit search queries, which are unavailable in many situations. To overcome this challenge, we introduce a novel RAG-based LVU approach inspired by the cognitive memory of human beings, which is called MemVid. Our approach operates with four basics steps: memorizing holistic video information, reasoning about the task's information needs based on the memory, retrieving critical moments based on the information needs, and focusing on the retrieved moments to produce the final answer. To enhance the system's memory-grounded reasoning capabilities and achieve optimal end-to-end performance, we propose a curriculum learning strategy. This approach begins with supervised learning on well-annotated reasoning results, then progressively explores and reinforces more plausible reasoning outcomes through reinforcement learning. We perform extensive evaluations on popular LVU benchmarks, including MLVU, VideoMME and LVBench. In our experiment, MemVid significantly outperforms existing RAG-based methods and popular LVU models, which demonstrate the effectiveness of our approach. Our model and source code will be made publicly available upon acceptance.
An Empirical Study on Eliciting and Improving R1-like Reasoning Models
Mar 06, 2025



In this report, we present the third technical report on the development of slow-thinking models as part of the STILL project. As the technical pathway becomes clearer, scaling RL training has become a central technique for implementing such reasoning models. We systematically experiment with and document the effects of various factors influencing RL training, conducting experiments on both base models and fine-tuned models. Specifically, we demonstrate that our RL training approach consistently improves the Qwen2.5-32B base models, enhancing both response length and test accuracy. Furthermore, we show that even when a model like DeepSeek-R1-Distill-Qwen-1.5B has already achieved a high performance level, it can be further refined through RL training, reaching an accuracy of 39.33% on AIME 2024. Beyond RL training, we also explore the use of tool manipulation, finding that it significantly boosts the reasoning performance of large reasoning models. This approach achieves a remarkable accuracy of 86.67% with greedy search on AIME 2024, underscoring its effectiveness in enhancing model capabilities. We release our resources at the STILL project website: https://github.com/RUCAIBox/Slow_Thinking_with_LLMs.