 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou are caught stealing my winning lottery ticket! Making a lottery ticket claim its ownership
Oct 30, 2021
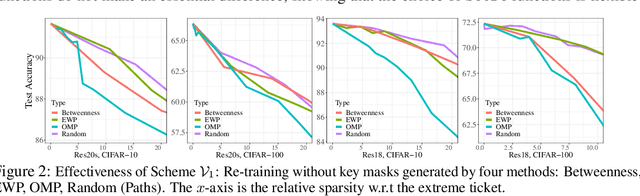


Despite tremendous success in many application scenarios, the training and inference costs of using deep learning are also rapidly increasing over time. The lottery ticket hypothesis (LTH) emerges as a promising framework to leverage a special sparse subnetwork (i.e., winning ticket) instead of a full model for both training and inference, that can lower both costs without sacrificing the performance. The main resource bottleneck of LTH is however the extraordinary cost to find the sparse mask of the winning ticket. That makes the found winning ticket become a valuable asset to the owners, highlighting the necessity of protecting its copyright. Our setting adds a new dimension to the recently soaring interest in protecting against the intellectual property (IP) infringement of deep models and verifying their ownerships, since they take owners' massive/unique resources to develop or train. While existing methods explored encrypted weights or predictions, we investigate a unique way to leverage sparse topological information to perform lottery verification, by developing several graph-based signatures that can be embedded as credentials. By further combining trigger set-based methods, our proposal can work in both white-box and black-box verification scenarios. Through extensive experiments, we demonstrate the effectiveness of lottery verification in diverse models (ResNet-20, ResNet-18, ResNet-50) on CIFAR-10 and CIFAR-100. Specifically, our verification is shown to be robust to removal attacks such as model fine-tuning and pruning, as well as several ambiguity attacks. Our codes are available at https://github.com/VITA-Group/NO-stealing-LTH.
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
Oct 30, 2021
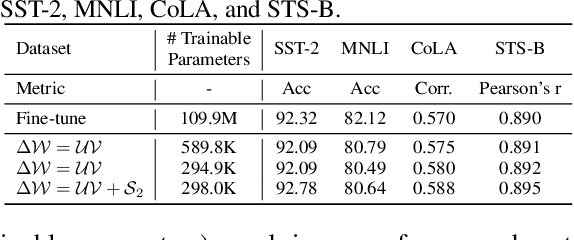
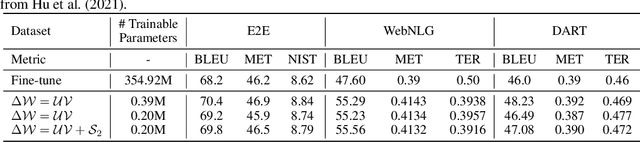
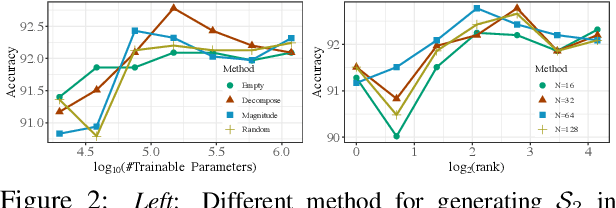
Gigantic pre-trained models have become central to natural language processing (NLP), serving as the starting point for fine-tuning towards a range of downstream tasks. However, two pain points persist for this paradigm: (a) as the pre-trained models grow bigger (e.g., 175B parameters for GPT-3), even the fine-tuning process can be time-consuming and computationally expensive; (b) the fine-tuned model has the same size as its starting point by default, which is neither sensible due to its more specialized functionality, nor practical since many fine-tuned models will be deployed in resource-constrained environments. To address these pain points, we propose a framework for resource- and parameter-efficient fine-tuning by leveraging the sparsity prior in both weight updates and the final model weights. Our proposed framework, dubbed Dually Sparsity-Embedded Efficient Tuning (DSEE), aims to achieve two key objectives: (i) parameter efficient fine-tuning - by enforcing sparsity-aware weight updates on top of the pre-trained weights; and (ii) resource-efficient inference - by encouraging a sparse weight structure towards the final fine-tuned model. We leverage sparsity in these two directions by exploiting both unstructured and structured sparse patterns in pre-trained language models via magnitude-based pruning and $\ell_1$ sparse regularization. Extensive experiments and in-depth investigations, with diverse network backbones (i.e., BERT, GPT-2, and DeBERTa) on dozens of datasets, consistently demonstrate highly impressive parameter-/training-/inference-efficiency, while maintaining competitive downstream transfer performance. For instance, our DSEE-BERT obtains about $35\%$ inference FLOPs savings with <1% trainable parameters and comparable performance to conventional fine-tuning. Codes are available in https://github.com/VITA-Group/DSEE.
Delayed Propagation Transformer: A Universal Computation Engine towards Practical Control in Cyber-Physical Systems
Oct 29, 2021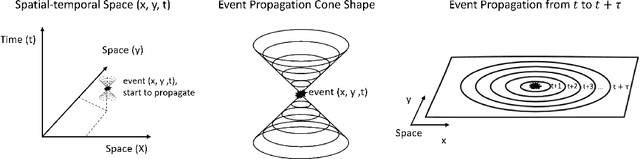
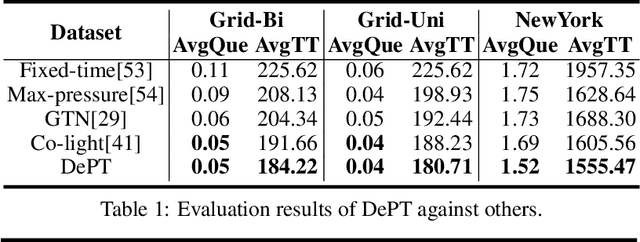
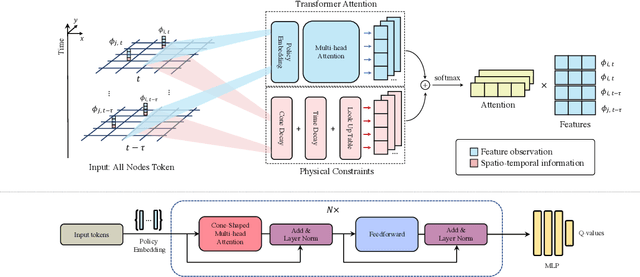
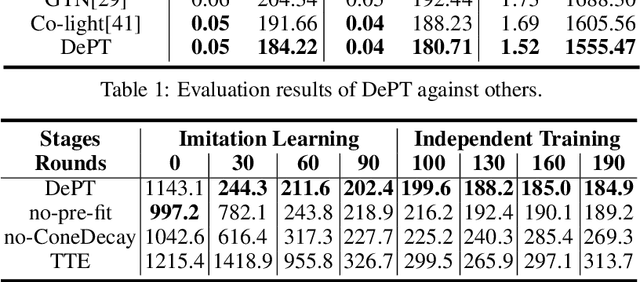
Multi-agent control is a central theme in the Cyber-Physical Systems (CPS). However, current control methods either receive non-Markovian states due to insufficient sensing and decentralized design, or suffer from poor convergence. This paper presents the Delayed Propagation Transformer (DePT), a new transformer-based model that specializes in the global modeling of CPS while taking into account the immutable constraints from the physical world. DePT induces a cone-shaped spatial-temporal attention prior, which injects the information propagation and aggregation principles and enables a global view. With physical constraint inductive bias baked into its design, our DePT is ready to plug and play for a broad class of multi-agent systems. The experimental results on one of the most challenging CPS -- network-scale traffic signal control system in the open world -- show that our model outperformed the state-of-the-art expert methods on synthetic and real-world datasets. Our codes are released at: https://github.com/VITA-Group/DePT.
Hyperparameter Tuning is All You Need for LISTA
Oct 29, 2021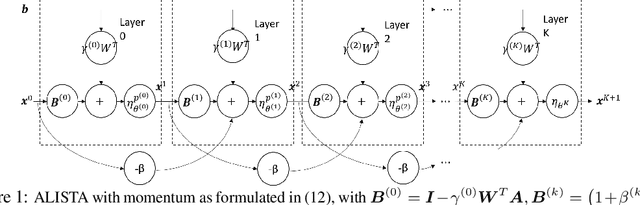
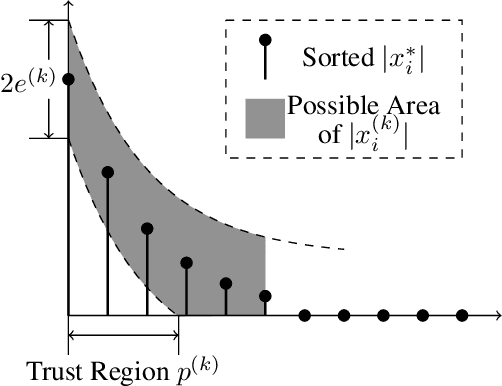
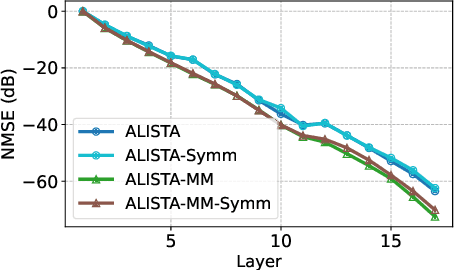
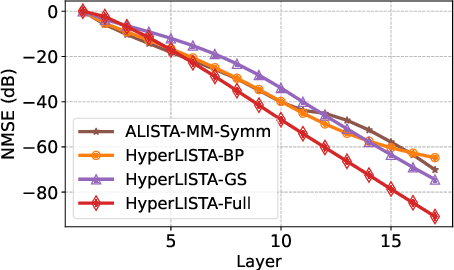
Learned Iterative Shrinkage-Thresholding Algorithm (LISTA) introduces the concept of unrolling an iterative algorithm and training it like a neural network. It has had great success on sparse recovery. In this paper, we show that adding momentum to intermediate variables in the LISTA network achieves a better convergence rate and, in particular, the network with instance-optimal parameters is superlinearly convergent. Moreover, our new theoretical results lead to a practical approach of automatically and adaptively calculating the parameters of a LISTA network layer based on its previous layers. Perhaps most surprisingly, such an adaptive-parameter procedure reduces the training of LISTA to tuning only three hyperparameters from data: a new record set in the context of the recent advances on trimming down LISTA complexity. We call this new ultra-light weight network HyperLISTA. Compared to state-of-the-art LISTA models, HyperLISTA achieves almost the same performance on seen data distributions and performs better when tested on unseen distributions (specifically, those with different sparsity levels and nonzero magnitudes). Code is available: https://github.com/VITA-Group/HyperLISTA.
AugMax: Adversarial Composition of Random Augmentations for Robust Training
Oct 26, 2021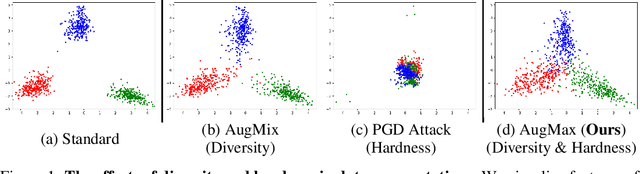
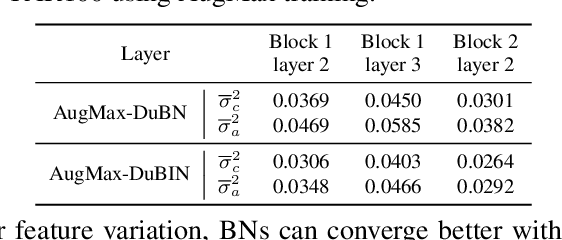
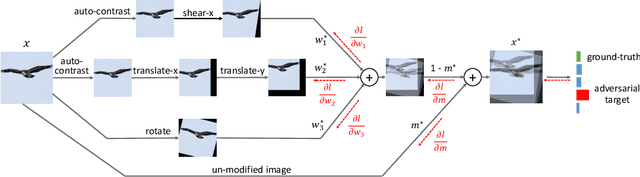
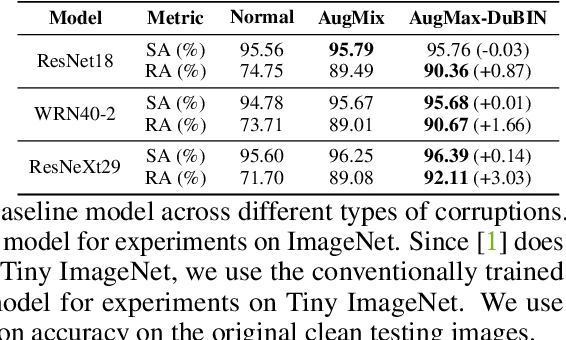
Data augmentation is a simple yet effective way to improve the robustness of deep neural networks (DNNs). Diversity and hardness are two complementary dimensions of data augmentation to achieve robustness. For example, AugMix explores random compositions of a diverse set of augmentations to enhance broader coverage, while adversarial training generates adversarially hard samples to spot the weakness. Motivated by this, we propose a data augmentation framework, termed AugMax, to unify the two aspects of diversity and hardness. AugMax first randomly samples multiple augmentation operators and then learns an adversarial mixture of the selected operators. Being a stronger form of data augmentation, AugMax leads to a significantly augmented input distribution which makes model training more challenging. To solve this problem, we further design a disentangled normalization module, termed DuBIN (Dual-Batch-and-Instance Normalization), that disentangles the instance-wise feature heterogeneity arising from AugMax. Experiments show that AugMax-DuBIN leads to significantly improved out-of-distribution robustness, outperforming prior arts by 3.03%, 3.49%, 1.82% and 0.71% on CIFAR10-C, CIFAR100-C, Tiny ImageNet-C and ImageNet-C. Codes and pretrained models are available: https://github.com/VITA-Group/AugMax.
Towards Lifelong Learning of Multilingual Text-To-Speech Synthesis
Oct 09, 2021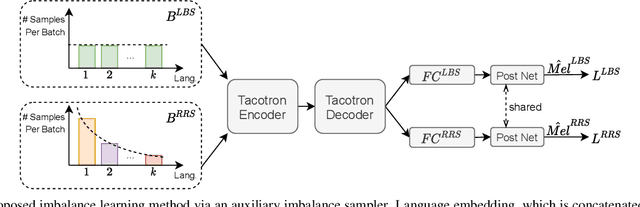
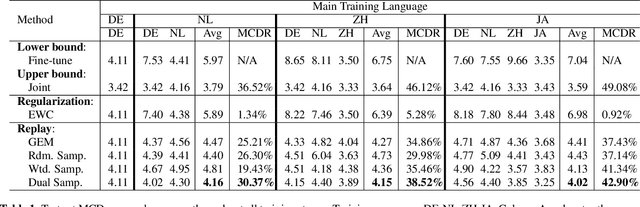
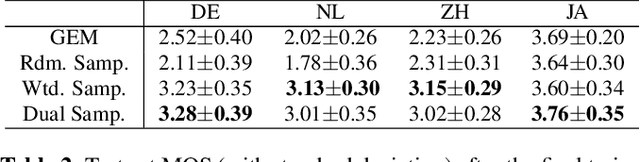
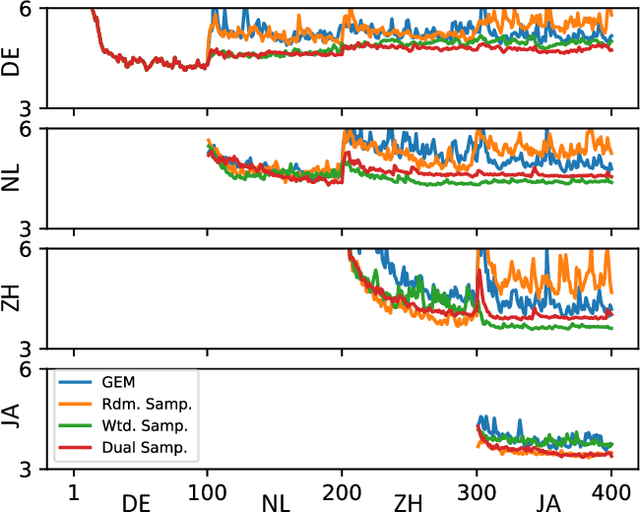
This work presents a lifelong learning approach to train a multilingual Text-To-Speech (TTS) system, where each language was seen as an individual task and was learned sequentially and continually. It does not require pooled data from all languages altogether, and thus alleviates the storage and computation burden. One of the challenges of lifelong learning methods is "catastrophic forgetting": in TTS scenario it means that model performance quickly degrades on previous languages when adapted to a new language. We approach this problem via a data-replay-based lifelong learning method. We formulate the replay process as a supervised learning problem, and propose a simple yet effective dual-sampler framework to tackle the heavily language-imbalanced training samples. Through objective and subjective evaluations, we show that this supervised learning formulation outperforms other gradient-based and regularization-based lifelong learning methods, achieving 43% Mel-Cepstral Distortion reduction compared to a fine-tuning baseline.
Universality of Deep Neural Network Lottery Tickets: A Renormalization Group Perspective
Oct 07, 2021
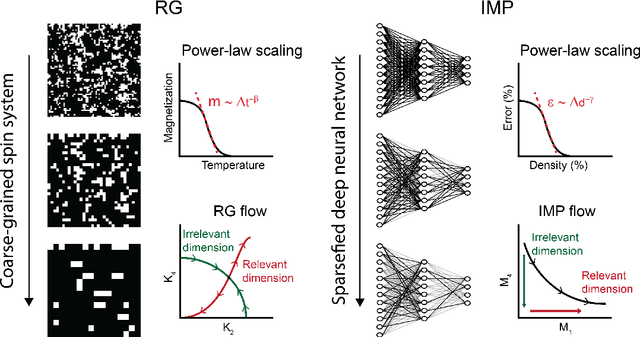
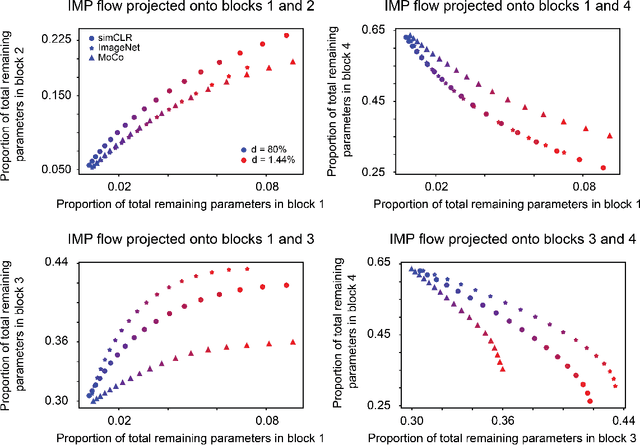
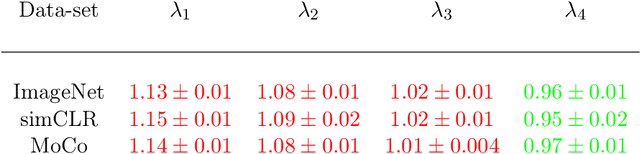
Foundational work on the Lottery Ticket Hypothesis has suggested an exciting corollary: winning tickets found in the context of one task can be transferred to similar tasks, possibly even across different architectures. While this has become of broad practical and theoretical interest, to date, there exists no detailed understanding of why winning ticket universality exists, or any way of knowing \textit{a priori} whether a given ticket can be transferred to a given task. To address these outstanding open questions, we make use of renormalization group theory, one of the most successful tools in theoretical physics. We find that iterative magnitude pruning, the method used for discovering winning tickets, is a renormalization group scheme. This opens the door to a wealth of existing numerical and theoretical tools, some of which we leverage here to examine winning ticket universality in large scale lottery ticket experiments, as well as sheds new light on the success iterative magnitude pruning has found in the field of sparse machine learning.
Skeleton-Graph: Long-Term 3D Motion Prediction From 2D Observations Using Deep Spatio-Temporal Graph CNNs
Sep 27, 2021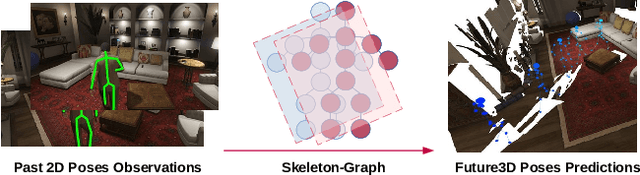
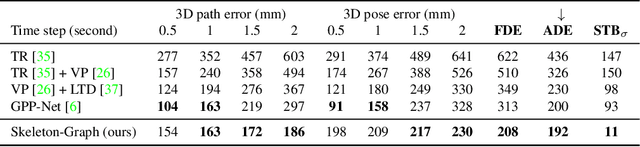
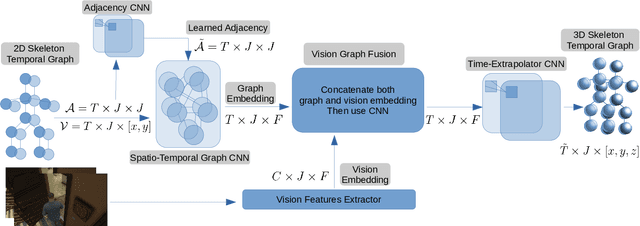
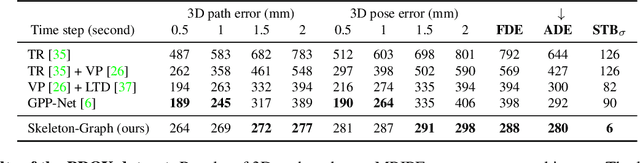
Several applications such as autonomous driving, augmented reality and virtual reality require a precise prediction of the 3D human pose. Recently, a new problem was introduced in the field to predict the 3D human poses from observed 2D poses. We propose Skeleton-Graph, a deep spatio-temporal graph CNN model that predicts the future 3D skeleton poses in a single pass from the 2D ones. Unlike prior works, Skeleton-Graph focuses on modeling the interaction between the skeleton joints by exploiting their spatial configuration. This is being achieved by formulating the problem as a graph structure while learning a suitable graph adjacency kernel. By the design, Skeleton-Graph predicts the future 3D poses without divergence in the long-term, unlike prior works. We also introduce a new metric that measures the divergence of predictions in the long term. Our results show an FDE improvement of at least 27% and an ADE of 4% on both the GTA-IM and PROX datasets respectively in comparison with prior works. Also, we are 88% and 93% less divergence on the long-term motion prediction in comparison with prior works on both GTA-IM and PROX datasets. Code is available at https://github.com/abduallahmohamed/Skeleton-Graph.git
GDP: Stabilized Neural Network Pruning via Gates with Differentiable Polarization
Sep 08, 2021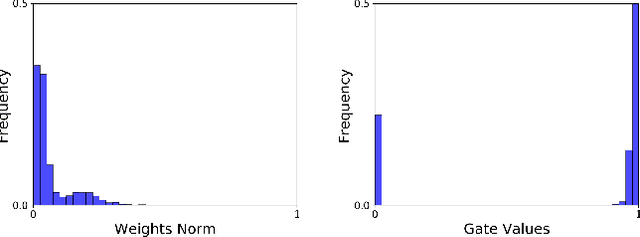

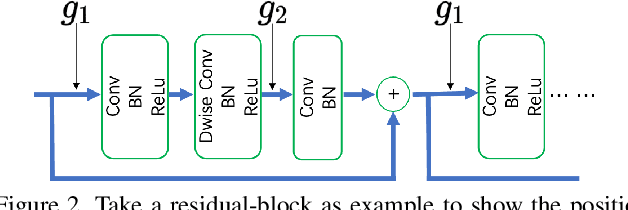
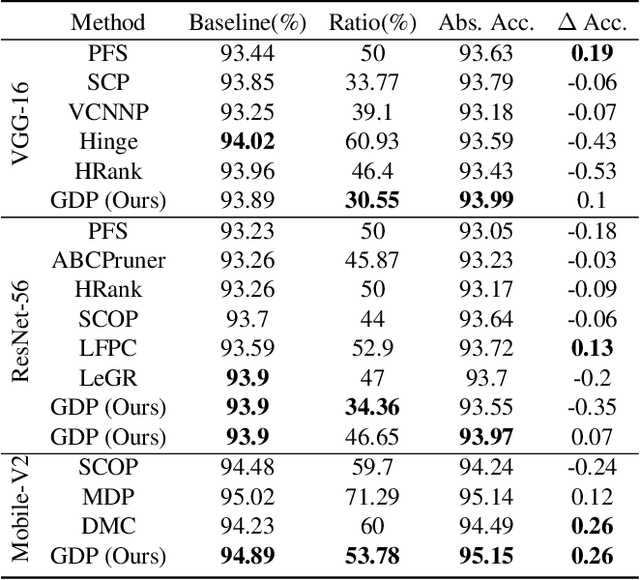
Model compression techniques are recently gaining explosive attention for obtaining efficient AI models for various real-time applications. Channel pruning is one important compression strategy and is widely used in slimming various DNNs. Previous gate-based or importance-based pruning methods aim to remove channels whose importance is smallest. However, it remains unclear what criteria the channel importance should be measured on, leading to various channel selection heuristics. Some other sampling-based pruning methods deploy sampling strategies to train sub-nets, which often causes the training instability and the compressed model's degraded performance. In view of the research gaps, we present a new module named Gates with Differentiable Polarization (GDP), inspired by principled optimization ideas. GDP can be plugged before convolutional layers without bells and whistles, to control the on-and-off of each channel or whole layer block. During the training process, the polarization effect will drive a subset of gates to smoothly decrease to exact zero, while other gates gradually stay away from zero by a large margin. When training terminates, those zero-gated channels can be painlessly removed, while other non-zero gates can be absorbed into the succeeding convolution kernel, causing completely no interruption to training nor damage to the trained model. Experiments conducted over CIFAR-10 and ImageNet datasets show that the proposed GDP algorithm achieves the state-of-the-art performance on various benchmark DNNs at a broad range of pruning ratios. We also apply GDP to DeepLabV3Plus-ResNet50 on the challenging Pascal VOC segmentation task, whose test performance sees no drop (even slightly improved) with over 60% FLOPs saving.
Font Completion and Manipulation by Cycling Between Multi-Modality Representations
Aug 30, 2021

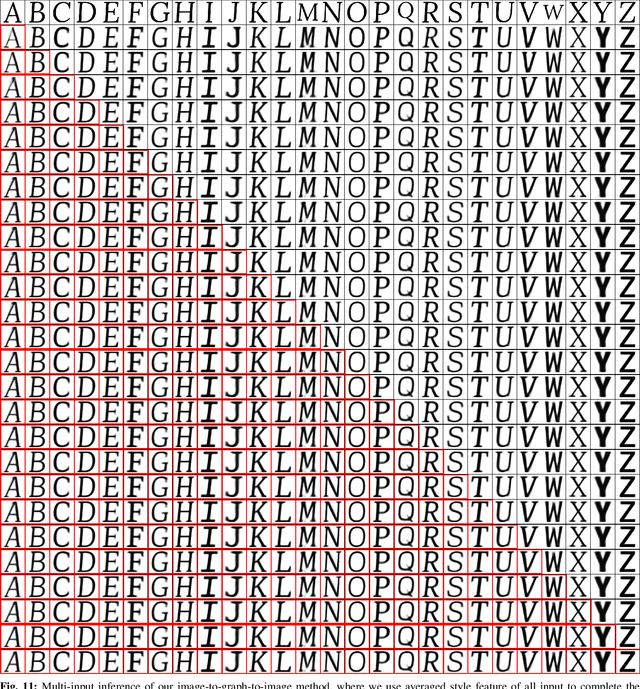

Generating font glyphs of consistent style from one or a few reference glyphs, i.e., font completion, is an important task in topographical design. As the problem is more well-defined than general image style transfer tasks, thus it has received interest from both vision and machine learning communities. Existing approaches address this problem as a direct image-to-image translation task. In this work, we innovate to explore the generation of font glyphs as 2D graphic objects with the graph as an intermediate representation, so that more intrinsic graphic properties of font styles can be captured. Specifically, we formulate a cross-modality cycled image-to-image model structure with a graph constructor between an image encoder and an image renderer. The novel graph constructor maps a glyph's latent code to its graph representation that matches expert knowledge, which is trained to help the translation task. Our model generates improved results than both image-to-image baseline and previous state-of-the-art methods for glyph completion. Furthermore, the graph representation output by our model also provides an intuitive interface for users to do local editing and manipulation. Our proposed cross-modality cycled representation learning has the potential to be applied to other domains with prior knowledge from different data modalities. Our code is available at https://github.com/VITA-Group/Font_Completion_Graph.