 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
Sep 09, 2025Many robotic manipulation tasks require sensing and responding to force signals such as torque to assess whether the task has been successfully completed and to enable closed-loop control. However, current Vision-Language-Action (VLA) models lack the ability to integrate such subtle physical feedback. In this work, we explore Torque-aware VLA models, aiming to bridge this gap by systematically studying the design space for incorporating torque signals into existing VLA architectures. We identify and evaluate several strategies, leading to three key findings. First, introducing torque adapters into the decoder consistently outperforms inserting them into the encoder.Third, inspired by joint prediction and planning paradigms in autonomous driving, we propose predicting torque as an auxiliary output, which further improves performance. This strategy encourages the model to build a physically grounded internal representation of interaction dynamics. Extensive quantitative and qualitative experiments across contact-rich manipulation benchmarks validate our findings.
Scalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025



The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
Xinyu AI Search: Enhanced Relevance and Comprehensive Results with Rich Answer Presentations
May 28, 2025Traditional search engines struggle to synthesize fragmented information for complex queries, while generative AI search engines face challenges in relevance, comprehensiveness, and presentation. To address these limitations, we introduce Xinyu AI Search, a novel system that incorporates a query-decomposition graph to dynamically break down complex queries into sub-queries, enabling stepwise retrieval and generation. Our retrieval pipeline enhances diversity through multi-source aggregation and query expansion, while filtering and re-ranking strategies optimize passage relevance. Additionally, Xinyu AI Search introduces a novel approach for fine-grained, precise built-in citation and innovates in result presentation by integrating timeline visualization and textual-visual choreography. Evaluated on recent real-world queries, Xinyu AI Search outperforms eight existing technologies in human assessments, excelling in relevance, comprehensiveness, and insightfulness. Ablation studies validate the necessity of its key sub-modules. Our work presents the first comprehensive framework for generative AI search engines, bridging retrieval, generation, and user-centric presentation.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025



Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
FTII-Bench: A Comprehensive Multimodal Benchmark for Flow Text with Image Insertion
Oct 16, 2024



Benefiting from the revolutionary advances in large language models (LLMs) and foundational vision models, large vision-language models (LVLMs) have also made significant progress. However, current benchmarks focus on tasks that evaluating only a single aspect of LVLM capabilities (e.g., recognition, detection, understanding). These tasks fail to fully demonstrate LVLMs' potential in complex application scenarios. To comprehensively assess the performance of existing LVLMs, we propose a more challenging task called the Flow Text with Image Insertion task (FTII). This task requires LVLMs to simultaneously possess outstanding abilities in image comprehension, instruction understanding, and long-text interpretation. Specifically, given several text paragraphs and a set of candidate images, as the text paragraphs accumulate, the LVLMs are required to select the most suitable image from the candidates to insert after the corresponding paragraph. Constructing a benchmark for such a task is highly challenging, particularly in determining the sequence of flowing text and images. To address this challenge, we turn to professional news reports, which naturally contain a gold standard for image-text sequences. Based on this, we introduce the Flow Text with Image Insertion Benchmark (FTII-Bench), which includes 318 high-quality Chinese image-text news articles and 307 high-quality English image-text news articles, covering 10 different news domains. Using these 625 high-quality articles, we construct problems of two different types with multiple levels of difficulty. Furthermore, we establish two different evaluation pipelines based on the CLIP model and existing LVLMs. We evaluate 9 open-source and 2 closed-source LVLMs as well as 2 CLIP-based models. Results indicate that even the most advanced models (e.g., GPT-4o) face significant challenges when tackling the FTII task.
MM-CamObj: A Comprehensive Multimodal Dataset for Camouflaged Object Scenarios
Sep 24, 2024



Large visual-language models (LVLMs) have achieved great success in multiple applications. However, they still encounter challenges in complex scenes, especially those involving camouflaged objects. This is primarily due to the lack of samples related to camouflaged scenes in the training dataset. To mitigate this issue, we construct the MM-CamObj dataset for the first time, comprising two subsets: CamObj-Align and CamObj-Instruct. Specifically, CamObj-Align contains 11,363 image-text pairs, and it is designed for VL alignment and injecting rich knowledge of camouflaged scenes into LVLMs. CamObj-Instruct is collected for fine-tuning the LVLMs with improved instruction-following capabilities, and it includes 11,363 images and 68,849 conversations with diverse instructions. Based on the MM-CamObj dataset, we propose the CamObj-Llava, an LVLM specifically designed for addressing tasks in camouflaged scenes. To facilitate our model's effective acquisition of knowledge about camouflaged objects and scenes, we introduce a curriculum learning strategy with six distinct modes. Additionally, we construct the CamObj-Bench to evaluate the existing LVLMs' capabilities of understanding, recognition, localization and count in camouflage scenes. This benchmark includes 600 images and 7 tasks, with a total of 9,449 questions. Extensive experiments are conducted on the CamObj-Bench with CamObj-Llava, 8 existing open-source and 3 closed-source LVLMs. Surprisingly, the results indicate that our model achieves a 25.84% improvement in 4 out of 7 tasks compared to GPT-4o. Code and datasets will be available at https://github.com/JCruan519/MM-CamObj.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
Similar Scenes arouse Similar Emotions: Parallel Data Augmentation for Stylized Image Captioning
Aug 26, 2021

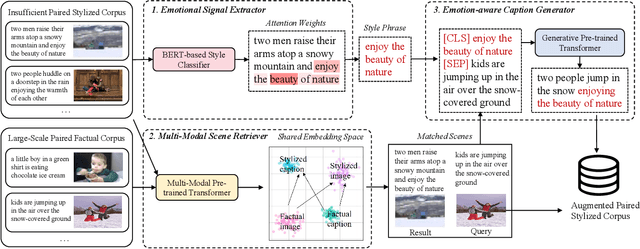
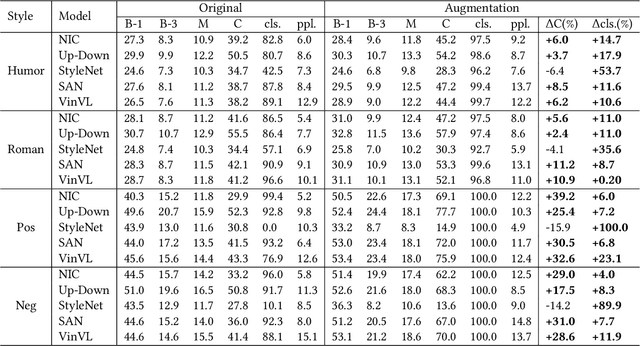
Stylized image captioning systems aim to generate a caption not only semantically related to a given image but also consistent with a given style description. One of the biggest challenges with this task is the lack of sufficient paired stylized data. Many studies focus on unsupervised approaches, without considering from the perspective of data augmentation. We begin with the observation that people may recall similar emotions when they are in similar scenes, and often express similar emotions with similar style phrases, which underpins our data augmentation idea. In this paper, we propose a novel Extract-Retrieve-Generate data augmentation framework to extract style phrases from small-scale stylized sentences and graft them to large-scale factual captions. First, we design the emotional signal extractor to extract style phrases from small-scale stylized sentences. Second, we construct the plugable multi-modal scene retriever to retrieve scenes represented with pairs of an image and its stylized caption, which are similar to the query image or caption in the large-scale factual data. In the end, based on the style phrases of similar scenes and the factual description of the current scene, we build the emotion-aware caption generator to generate fluent and diversified stylized captions for the current scene. Extensive experimental results show that our framework can alleviate the data scarcity problem effectively. It also significantly boosts the performance of several existing image captioning models in both supervised and unsupervised settings, which outperforms the state-of-the-art stylized image captioning methods in terms of both sentence relevance and stylishness by a substantial margin.
Dialogue State Tracking with Multi-Level Fusion of Predicted Dialogue States and Conversations
Jul 12, 2021
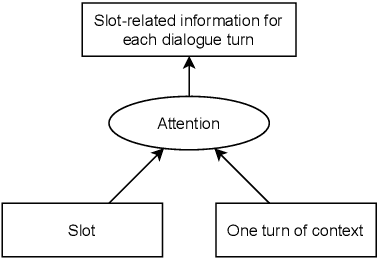
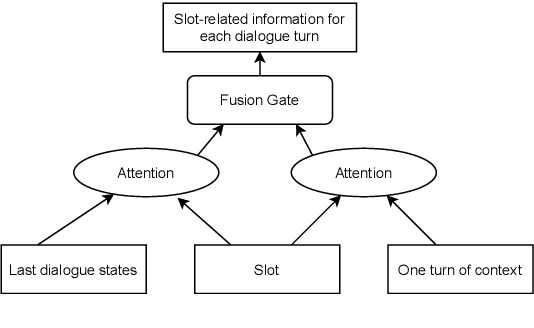
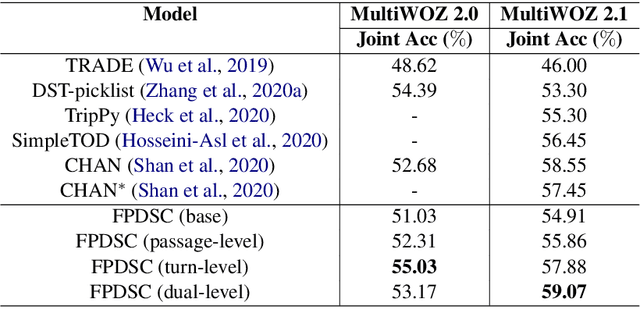
Most recently proposed approaches in dialogue state tracking (DST) leverage the context and the last dialogue states to track current dialogue states, which are often slot-value pairs. Although the context contains the complete dialogue information, the information is usually indirect and even requires reasoning to obtain. The information in the lastly predicted dialogue states is direct, but when there is a prediction error, the dialogue information from this source will be incomplete or erroneous. In this paper, we propose the Dialogue State Tracking with Multi-Level Fusion of Predicted Dialogue States and Conversations network (FPDSC). This model extracts information of each dialogue turn by modeling interactions among each turn utterance, the corresponding last dialogue states, and dialogue slots. Then the representation of each dialogue turn is aggregated by a hierarchical structure to form the passage information, which is utilized in the current turn of DST. Experimental results validate the effectiveness of the fusion network with 55.03% and 59.07% joint accuracy on MultiWOZ 2.0 and MultiWOZ 2.1 datasets, which reaches the state-of-the-art performance. Furthermore, we conduct the deleted-value and related-slot experiments on MultiWOZ 2.1 to evaluate our model.