 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
Mar 19, 2026Video action models are an appealing foundation for Vision--Language--Action systems because they can learn visual dynamics from large-scale video data and transfer this knowledge to downstream robot control. Yet current diffusion-based video predictors are trained with likelihood-surrogate objectives, which encourage globally plausible predictions without explicitly optimizing the precision-critical visual dynamics needed for manipulation. This objective mismatch often leads to subtle errors in object pose, spatial relations, and contact timing that can be amplified by downstream policies. We propose VAMPO, a post-training framework that directly improves visual dynamics in video action models through policy optimization. Our key idea is to formulate multi-step denoising as a sequential decision process and optimize the denoising policy with rewards defined over expert visual dynamics in latent space. To make this optimization practical, we introduce an Euler Hybrid sampler that injects stochasticity only at the first denoising step, enabling tractable low-variance policy-gradient estimation while preserving the coherence of the remaining denoising trajectory. We further combine this design with GRPO and a verifiable non-adversarial reward. Across diverse simulated and real-world manipulation tasks, VAMPO improves task-relevant visual dynamics, leading to better downstream action generation and stronger generalization. The homepage is https://vampo-robot.github.io/VAMPO/.
Fast Catch-Up, Late Switching: Optimal Batch Size Scheduling via Functional Scaling Laws
Feb 15, 2026Batch size scheduling (BSS) plays a critical role in large-scale deep learning training, influencing both optimization dynamics and computational efficiency. Yet, its theoretical foundations remain poorly understood. In this work, we show that the functional scaling law (FSL) framework introduced in Li et al. (2025a) provides a principled lens for analyzing BSS. Specifically, we characterize the optimal BSS under a fixed data budget and show that its structure depends sharply on task difficulty. For easy tasks, optimal schedules keep increasing batch size throughout. In contrast, for hard tasks, the optimal schedule maintains small batch sizes for most of training and switches to large batches only in a late stage. To explain the emergence of late switching, we uncover a dynamical mechanism -- the fast catch-up effect -- which also manifests in large language model (LLM) pretraining. After switching from small to large batches, the loss rapidly aligns with the constant large-batch trajectory. Using FSL, we show that this effect stems from rapid forgetting of accumulated gradient noise, with the catch-up speed determined by task difficulty. Crucially, this effect implies that large batches can be safely deferred to late training without sacrificing performance, while substantially reducing data consumption. Finally, extensive LLM pretraining experiments -- covering both Dense and MoE architectures with up to 1.1B parameters and 1T tokens -- validate our theoretical predictions. Across all settings, late-switch schedules consistently outperform constant-batch and early-switch baselines.
GradPower: Powering Gradients for Faster Language Model Pre-Training
May 30, 2025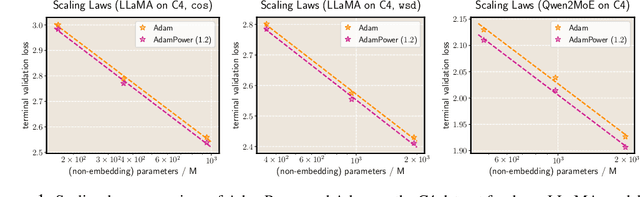
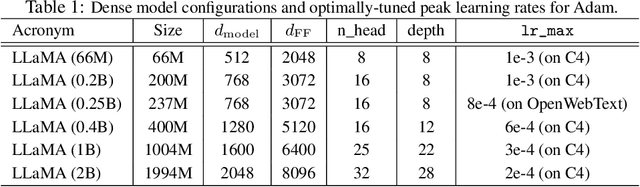
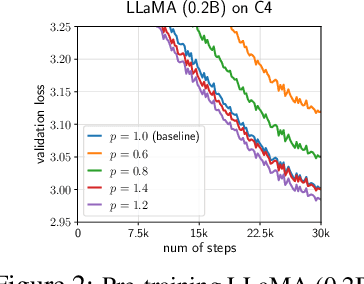
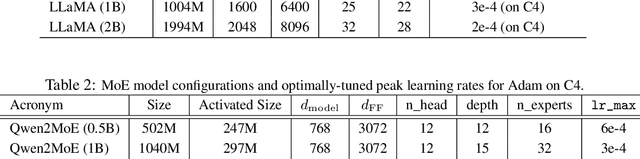
We propose GradPower, a lightweight gradient-transformation technique for accelerating language model pre-training. Given a gradient vector $g=(g_i)_i$, GradPower first applies the elementwise sign-power transformation: $\varphi_p(g)=({\rm sign}(g_i)|g_i|^p)_{i}$ for a fixed $p>0$, and then feeds the transformed gradient into a base optimizer. Notably, GradPower requires only a single-line code change and no modifications to the base optimizer's internal logic, including the hyperparameters. When applied to Adam (termed AdamPower), GradPower consistently achieves lower terminal loss across diverse architectures (LLaMA, Qwen2MoE), parameter scales (66M to 2B), datasets (C4, OpenWebText), and learning-rate schedules (cosine, warmup-stable-decay). The most pronounced gains are observed when training modern mixture-of-experts models with warmup-stable-decay schedules. GradPower also integrates seamlessly with other state-of-the-art optimizers, such as Muon, yielding further improvements. Finally, we provide theoretical analyses that reveal the underlying mechanism of GradPower and highlights the influence of gradient noise.
Simulation-informed deep learning for enhanced SWOT observations of fine-scale ocean dynamics
Mar 27, 2025Oceanic processes at fine scales are crucial yet difficult to observe accurately due to limitations in satellite and in-situ measurements. The Surface Water and Ocean Topography (SWOT) mission provides high-resolution Sea Surface Height (SSH) data, though noise patterns often obscure fine scale structures. Current methods struggle with noisy data or require extensive supervised training, limiting their effectiveness on real-world observations. We introduce SIMPGEN (Simulation-Informed Metric and Prior for Generative Ensemble Networks), an unsupervised adversarial learning framework combining real SWOT observations with simulated reference data. SIMPGEN leverages wavelet-informed neural metrics to distinguish noisy from clean fields, guiding realistic SSH reconstructions. Applied to SWOT data, SIMPGEN effectively removes noise, preserving fine-scale features better than existing neural methods. This robust, unsupervised approach not only improves SWOT SSH data interpretation but also demonstrates strong potential for broader oceanographic applications, including data assimilation and super-resolution.
The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Feb 26, 2025Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly $2\times$ speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 1.1B and datasets of OpenWebText and MiniPile. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined $2\times$ speedup and $2\times$ memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.
How to Defend Against Large-scale Model Poisoning Attacks in Federated Learning: A Vertical Solution
Nov 16, 2024



Federated learning (FL) is vulnerable to model poisoning attacks due to its distributed nature. The current defenses start from all user gradients (model updates) in each communication round and solve for the optimal aggregation gradients (horizontal solution). This horizontal solution will completely fail when facing large-scale (>50%) model poisoning attacks. In this work, based on the key insight that the convergence process of the model is a highly predictable process, we break away from the traditional horizontal solution of defense and innovatively transform the problem of solving the optimal aggregation gradients into a vertical solution problem. We propose VERT, which uses global communication rounds as the vertical axis, trains a predictor using historical gradients information to predict user gradients, and compares the similarity with actual user gradients to precisely and efficiently select the optimal aggregation gradients. In order to reduce the computational complexity of VERT, we design a low dimensional vector projector to project the user gradients to a computationally acceptable length, and then perform subsequent predictor training and prediction tasks. Exhaustive experiments show that VERT is efficient and scalable, exhibiting excellent large-scale (>=80%) model poisoning defense effects under different FL scenarios. In addition, we can design projector with different structures for different model structures to adapt to aggregation servers with different computing power.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
Improving Generalization and Convergence by Enhancing Implicit Regularization
May 31, 2024



In this work, we propose an Implicit Regularization Enhancement (IRE) framework to accelerate the discovery of flat solutions in deep learning, thereby improving generalization and convergence. Specifically, IRE decouples the dynamics of flat and sharp directions, which boosts the sharpness reduction along flat directions while maintaining the training stability in sharp directions. We show that IRE can be practically incorporated with {\em generic base optimizers} without introducing significant computational overload. Experiments show that IRE consistently improves the generalization performance for image classification tasks across a variety of benchmark datasets (CIFAR-10/100, ImageNet) and models (ResNets and ViTs). Surprisingly, IRE also achieves a $2\times$ {\em speed-up} compared to AdamW in the pre-training of Llama models (of sizes ranging from 60M to 229M) on datasets including Wikitext-103, Minipile, and Openwebtext. Moreover, we provide theoretical guarantees, showing that IRE can substantially accelerate the convergence towards flat minima in Sharpness-aware Minimization (SAM).
YOLO based Ocean Eddy Localization with AWS SageMaker
Apr 10, 2024


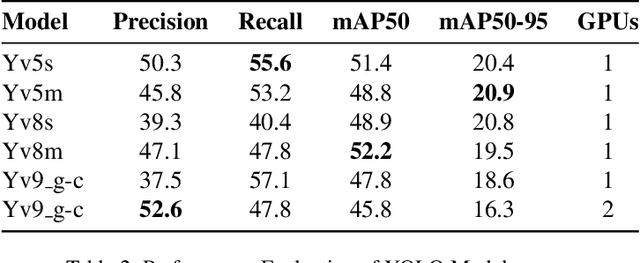
Ocean eddies play a significant role both on the sea surface and beneath it, contributing to the sustainability of marine life dependent on oceanic behaviors. Therefore, it is crucial to investigate ocean eddies to monitor changes in the Earth, particularly in the oceans, and their impact on climate. This study aims to pinpoint ocean eddies using AWS cloud services, specifically SageMaker. The primary objective is to detect small-scale (<20km) ocean eddies from satellite remote images and assess the feasibility of utilizing SageMaker, which offers tools for deploying AI applications. Moreover, this research not only explores the deployment of cloud-based services for remote sensing of Earth data but also evaluates several YOLO (You Only Look Once) models using single and multi-GPU-based services in the cloud. Furthermore, this study underscores the potential of these services, their limitations, challenges related to deployment and resource management, and their user-riendliness for Earth science projects.
Exploring the Integration of Large Language Models into Automatic Speech Recognition Systems: An Empirical Study
Jul 13, 2023



This paper explores the integration of Large Language Models (LLMs) into Automatic Speech Recognition (ASR) systems to improve transcription accuracy. The increasing sophistication of LLMs, with their in-context learning capabilities and instruction-following behavior, has drawn significant attention in the field of Natural Language Processing (NLP). Our primary focus is to investigate the potential of using an LLM's in-context learning capabilities to enhance the performance of ASR systems, which currently face challenges such as ambient noise, speaker accents, and complex linguistic contexts. We designed a study using the Aishell-1 and LibriSpeech datasets, with ChatGPT and GPT-4 serving as benchmarks for LLM capabilities. Unfortunately, our initial experiments did not yield promising results, indicating the complexity of leveraging LLM's in-context learning for ASR applications. Despite further exploration with varied settings and models, the corrected sentences from the LLMs frequently resulted in higher Word Error Rates (WER), demonstrating the limitations of LLMs in speech applications. This paper provides a detailed overview of these experiments, their results, and implications, establishing that using LLMs' in-context learning capabilities to correct potential errors in speech recognition transcriptions is still a challenging task at the current stage.