 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unrolling of Sparsity-Induced RDO for 3D Point Cloud Attribute Coding
Sep 10, 2025Given encoded 3D point cloud geometry available at the decoder, we study the problem of lossy attribute compression in a multi-resolution B-spline projection framework. A target continuous 3D attribute function is first projected onto a sequence of nested subspaces $\mathcal{F}^{(p)}_{l_0} \subseteq \cdots \subseteq \mathcal{F}^{(p)}_{L}$, where $\mathcal{F}^{(p)}_{l}$ is a family of functions spanned by a B-spline basis function of order $p$ at a chosen scale and its integer shifts. The projected low-pass coefficients $F_l^*$ are computed by variable-complexity unrolling of a rate-distortion (RD) optimization algorithm into a feed-forward network, where the rate term is the sparsity-promoting $\ell_1$-norm. Thus, the projection operation is end-to-end differentiable. For a chosen coarse-to-fine predictor, the coefficients are then adjusted to account for the prediction from a lower-resolution to a higher-resolution, which is also optimized in a data-driven manner.
Lightweight Transformer via Unrolling of Mixed Graph Algorithms for Traffic Forecast
May 19, 2025



To forecast traffic with both spatial and temporal dimensions, we unroll a mixed-graph-based optimization algorithm into a lightweight and interpretable transformer-like neural net. Specifically, we construct two graphs: an undirected graph $\mathcal{G}^u$ capturing spatial correlations across geography, and a directed graph $\mathcal{G}^d$ capturing sequential relationships over time. We formulate a prediction problem for the future samples of signal $\mathbf{x}$, assuming it is "smooth" with respect to both $\mathcal{G}^u$ and $\mathcal{G}^d$, where we design new $\ell_2$ and $\ell_1$-norm variational terms to quantify and promote signal smoothness (low-frequency reconstruction) on a directed graph. We construct an iterative algorithm based on alternating direction method of multipliers (ADMM), and unroll it into a feed-forward network for data-driven parameter learning. We insert graph learning modules for $\mathcal{G}^u$ and $\mathcal{G}^d$, which are akin to the self-attention mechanism in classical transformers. Experiments show that our unrolled networks achieve competitive traffic forecast performance as state-of-the-art prediction schemes, while reducing parameter counts drastically. Our code is available in https://github.com/SingularityUndefined/Unrolling-GSP-STForecast.
Constructing an Interpretable Deep Denoiser by Unrolling Graph Laplacian Regularizer
Sep 10, 2024



An image denoiser can be used for a wide range of restoration problems via the Plug-and-Play (PnP) architecture. In this paper, we propose a general framework to build an interpretable graph-based deep denoiser (GDD) by unrolling a solution to a maximum a posteriori (MAP) problem equipped with a graph Laplacian regularizer (GLR) as signal prior. Leveraging a recent theorem showing that any (pseudo-)linear denoiser $\boldsymbol \Psi$, under mild conditions, can be mapped to a solution of a MAP denoising problem regularized using GLR, we first initialize a graph Laplacian matrix $\mathbf L$ via truncated Taylor Series Expansion (TSE) of $\boldsymbol \Psi^{-1}$. Then, we compute the MAP linear system solution by unrolling iterations of the conjugate gradient (CG) algorithm into a sequence of neural layers as a feed-forward network -- one that is amenable to parameter tuning. The resulting GDD network is "graph-interpretable", low in parameter count, and easy to initialize thanks to $\mathbf L$ derived from a known well-performing denoiser $\boldsymbol \Psi$. Experimental results show that GDD achieves competitive image denoising performance compared to competitors, but employing far fewer parameters, and is more robust to covariate shift.
Interpretable Lightweight Transformer via Unrolling of Learned Graph Smoothness Priors
Jun 06, 2024



We build interpretable and lightweight transformer-like neural networks by unrolling iterative optimization algorithms that minimize graph smoothness priors -- the quadratic graph Laplacian regularizer (GLR) and the $\ell_1$-norm graph total variation (GTV) -- subject to an interpolation constraint. The crucial insight is that a normalized signal-dependent graph learning module amounts to a variant of the basic self-attention mechanism in conventional transformers. Unlike "black-box" transformers that require learning of large key, query and value matrices to compute scaled dot products as affinities and subsequent output embeddings, resulting in huge parameter sets, our unrolled networks employ shallow CNNs to learn low-dimensional features per node to establish pairwise Mahalanobis distances and construct sparse similarity graphs. At each layer, given a learned graph, the target interpolated signal is simply a low-pass filtered output derived from the minimization of an assumed graph smoothness prior, leading to a dramatic reduction in parameter count. Experiments for two image interpolation applications verify the restoration performance, parameter efficiency and robustness to covariate shift of our graph-based unrolled networks compared to conventional transformers.
Volumetric 3D Point Cloud Attribute Compression: Learned polynomial bilateral filter for prediction
Nov 22, 2023We extend a previous study on 3D point cloud attribute compression scheme that uses a volumetric approach: given a target volumetric attribute function $f : \mathbb{R}^3 \mapsto \mathbb{R}$, we quantize and encode parameters $\theta$ that characterize $f$ at the encoder, for reconstruction $f_{\hat{\theta}}(\mathbf(x))$ at known 3D points $\mathbf(x)$ at the decoder. Specifically, parameters $\theta$ are quantized coefficients of B-spline basis vectors $\mathbf{\Phi}_l$ (for order $p \geq 2$) that span the function space $\mathcal{F}_l^{(p)}$ at a particular resolution $l$, which are coded from coarse to fine resolutions for scalability. In this work, we focus on the prediction of finer-grained coefficients given coarser-grained ones by learning parameters of a polynomial bilateral filter (PBF) from data. PBF is a pseudo-linear filter that is signal-dependent with a graph spectral interpretation common in the graph signal processing (GSP) field. We demonstrate PBF's predictive performance over a linear predictor inspired by MPEG standardization over a wide range of point cloud datasets.
Learned Nonlinear Predictor for Critically Sampled 3D Point Cloud Attribute Compression
Nov 22, 2023

We study 3D point cloud attribute compression via a volumetric approach: assuming point cloud geometry is known at both encoder and decoder, parameters $\theta$ of a continuous attribute function $f: \mathbb{R}^3 \mapsto \mathbb{R}$ are quantized to $\hat{\theta}$ and encoded, so that discrete samples $f_{\hat{\theta}}(\mathbf{x}_i)$ can be recovered at known 3D points $\mathbf{x}_i \in \mathbb{R}^3$ at the decoder. Specifically, we consider a nested sequences of function subspaces $\mathcal{F}^{(p)}_{l_0} \subseteq \cdots \subseteq \mathcal{F}^{(p)}_L$, where $\mathcal{F}_l^{(p)}$ is a family of functions spanned by B-spline basis functions of order $p$, $f_l^*$ is the projection of $f$ on $\mathcal{F}_l^{(p)}$ and encoded as low-pass coefficients $F_l^*$, and $g_l^*$ is the residual function in orthogonal subspace $\mathcal{G}_l^{(p)}$ (where $\mathcal{G}_l^{(p)} \oplus \mathcal{F}_l^{(p)} = \mathcal{F}_{l+1}^{(p)}$) and encoded as high-pass coefficients $G_l^*$. In this paper, to improve coding performance over [1], we study predicting $f_{l+1}^*$ at level $l+1$ given $f_l^*$ at level $l$ and encoding of $G_l^*$ for the $p=1$ case (RAHT($1$)). For the prediction, we formalize RAHT(1) linear prediction in MPEG-PCC in a theoretical framework, and propose a new nonlinear predictor using a polynomial of bilateral filter. We derive equations to efficiently compute the critically sampled high-pass coefficients $G_l^*$ amenable to encoding. We optimize parameters in our resulting feed-forward network on a large training set of point clouds by minimizing a rate-distortion Lagrangian. Experimental results show that our improved framework outperformed the MPEG G-PCC predictor by $11$ to $12\%$ in bit rate reduction.
Volumetric Attribute Compression for 3D Point Clouds using Feedforward Network with Geometric Attention
Apr 01, 2023We study 3D point cloud attribute compression using a volumetric approach: given a target volumetric attribute function $f : \mathbb{R}^3 \rightarrow \mathbb{R}$, we quantize and encode parameter vector $\theta$ that characterizes $f$ at the encoder, for reconstruction $f_{\hat{\theta}}(\mathbf{x})$ at known 3D points $\mathbf{x}$'s at the decoder. Extending a previous work Region Adaptive Hierarchical Transform (RAHT) that employs piecewise constant functions to span a nested sequence of function spaces, we propose a feedforward linear network that implements higher-order B-spline bases spanning function spaces without eigen-decomposition. Feedforward network architecture means that the system is amenable to end-to-end neural learning. The key to our network is space-varying convolution, similar to a graph operator, whose weights are computed from the known 3D geometry for normalization. We show that the number of layers in the normalization at the encoder is equivalent to the number of terms in a matrix inverse Taylor series. Experimental results on real-world 3D point clouds show up to 2-3 dB gain over RAHT in energy compaction and 20-30% bitrate reduction.
Hybrid Model-based / Data-driven Graph Transform for Image Coding
Mar 02, 2022
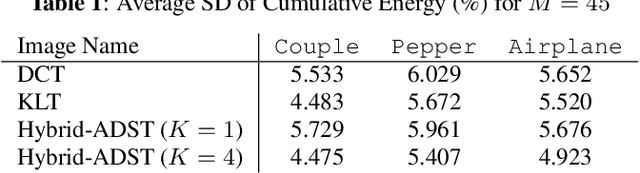
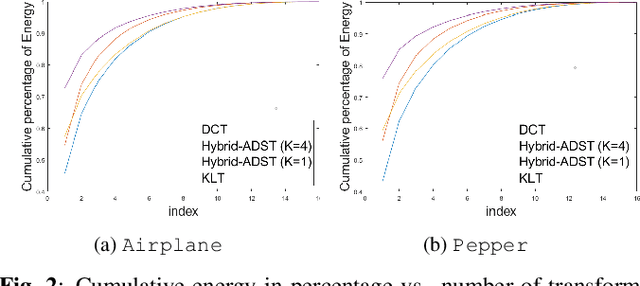

Transform coding to sparsify signal representations remains crucial in an image compression pipeline. While the Karhunen-Lo\`{e}ve transform (KLT) computed from an empirical covariance matrix $\bar{C}$ is theoretically optimal for a stationary process, in practice, collecting sufficient statistics from a non-stationary image to reliably estimate $\bar{C}$ can be difficult. In this paper, to encode an intra-prediction residual block, we pursue a hybrid model-based / data-driven approach: the first $K$ eigenvectors of a transform matrix are derived from a statistical model, e.g., the asymmetric discrete sine transform (ADST), for stability, while the remaining $N-K$ are computed from $\bar{C}$ for performance. The transform computation is posed as a graph learning problem, where we seek a graph Laplacian matrix minimizing a graphical lasso objective inside a convex cone sharing the first $K$ eigenvectors in a Hilbert space of real symmetric matrices. We efficiently solve the problem via augmented Lagrangian relaxation and proximal gradient (PG). Using WebP as a baseline image codec, experimental results show that our hybrid graph transform achieved better energy compaction than default discrete cosine transform (DCT) and better stability than KLT.