 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Weighting Approach in Kernel Bayes' Rule
Feb 05, 2022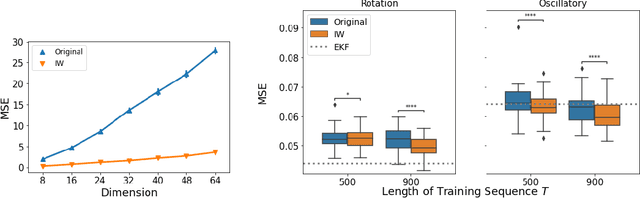
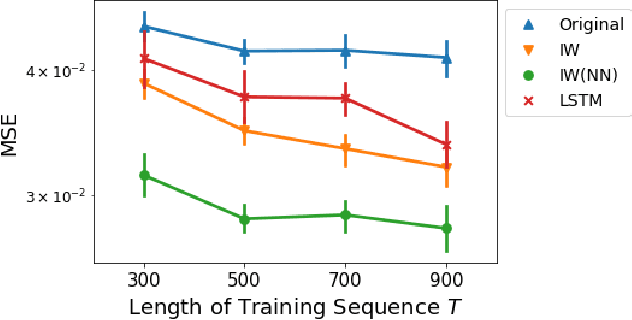
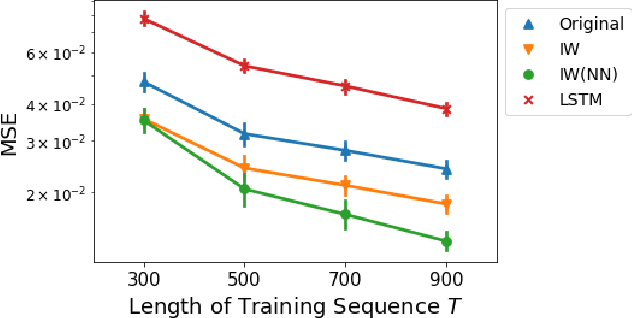
We study a nonparametric approach to Bayesian computation via feature means, where the expectation of prior features is updated to yield expected posterior features, based on regression from kernel or neural net features of the observations. All quantities involved in the Bayesian update are learned from observed data, making the method entirely model-free. The resulting algorithm is a novel instance of a kernel Bayes' rule (KBR). Our approach is based on importance weighting, which results in superior numerical stability to the existing approach to KBR, which requires operator inversion. We show the convergence of the estimator using a novel consistency analysis on the importance weighting estimator in the infinity norm. We evaluate our KBR on challenging synthetic benchmarks, including a filtering problem with a state-space model involving high dimensional image observations. The proposed method yields uniformly better empirical performance than the existing KBR, and competitive performance with other competing methods.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021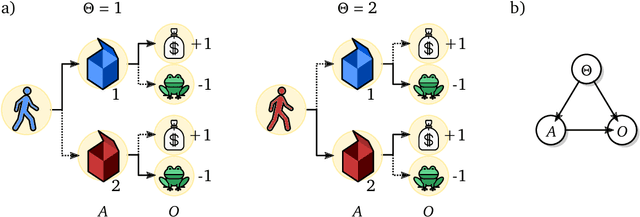
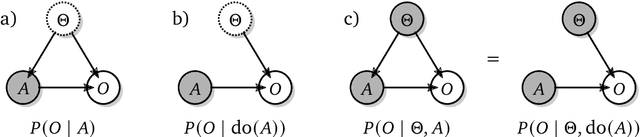
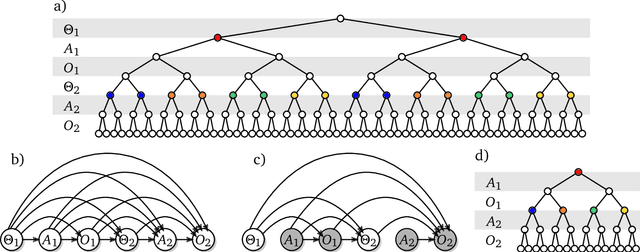
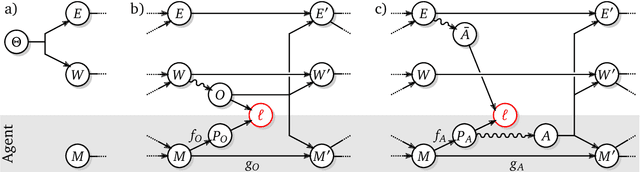
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Introducing Symmetries to Black Box Meta Reinforcement Learning
Sep 22, 2021

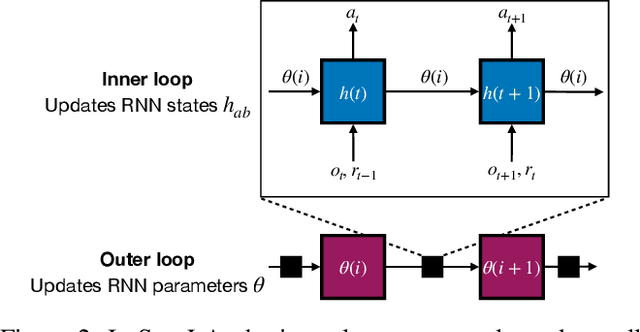
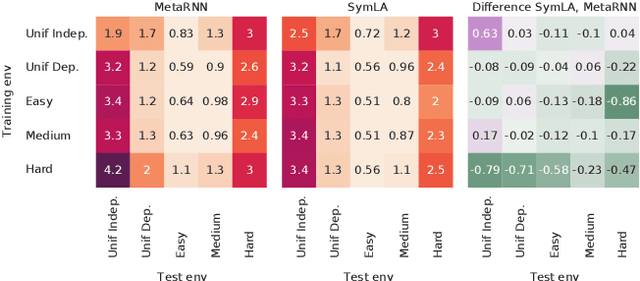
Meta reinforcement learning (RL) attempts to discover new RL algorithms automatically from environment interaction. In so-called black-box approaches, the policy and the learning algorithm are jointly represented by a single neural network. These methods are very flexible, but they tend to underperform in terms of generalisation to new, unseen environments. In this paper, we explore the role of symmetries in meta-generalisation. We show that a recent successful meta RL approach that meta-learns an objective for backpropagation-based learning exhibits certain symmetries (specifically the reuse of the learning rule, and invariance to input and output permutations) that are not present in typical black-box meta RL systems. We hypothesise that these symmetries can play an important role in meta-generalisation. Building off recent work in black-box supervised meta learning, we develop a black-box meta RL system that exhibits these same symmetries. We show through careful experimentation that incorporating these symmetries can lead to algorithms with a greater ability to generalise to unseen action & observation spaces, tasks, and environments.
Active Offline Policy Selection
Jun 18, 2021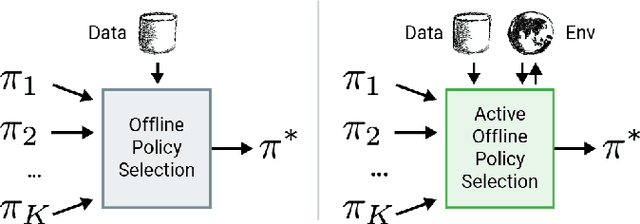
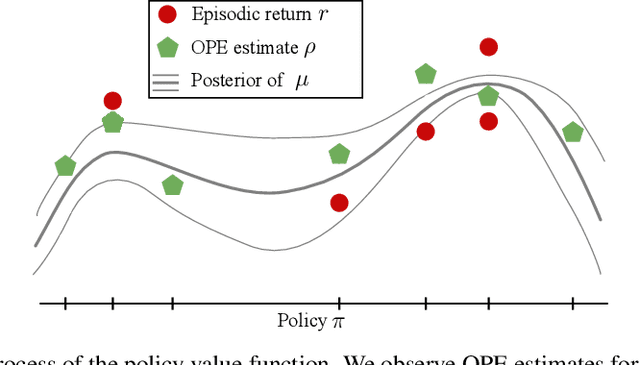
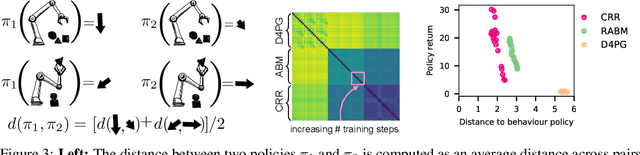

This paper addresses the problem of policy selection in domains with abundant logged data, but with a very restricted interaction budget. Solving this problem would enable safe evaluation and deployment of offline reinforcement learning policies in industry, robotics, and healthcare domain among others. Several off-policy evaluation (OPE) techniques have been proposed to assess the value of policies using only logged data. However, there is still a big gap between the evaluation by OPE and the full online evaluation in the real environment. To reduce this gap, we introduce a novel \emph{active offline policy selection} problem formulation, which combined logged data and limited online interactions to identify the best policy. We rely on the advances in OPE to warm start the evaluation. We build upon Bayesian optimization to iteratively decide which policies to evaluate in order to utilize the limited environment interactions wisely. Many candidate policies could be proposed, thus, we focus on making our approach scalable and introduce a kernel function to model similarity between policies. We use several benchmark environments to show that the proposed approach improves upon state-of-the-art OPE estimates and fully online policy evaluation with limited budget. Additionally, we show that each component of the proposed method is important, it works well with various number and quality of OPE estimates and even with a large number of candidate policies.
On Instrumental Variable Regression for Deep Offline Policy Evaluation
May 21, 2021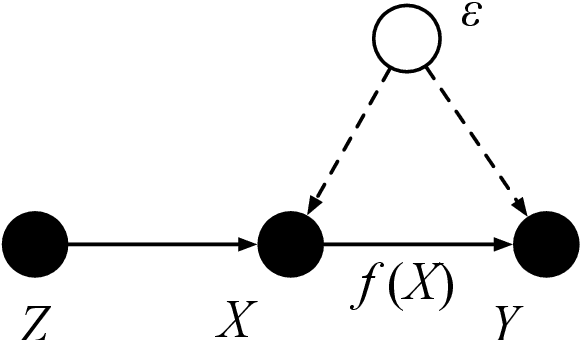
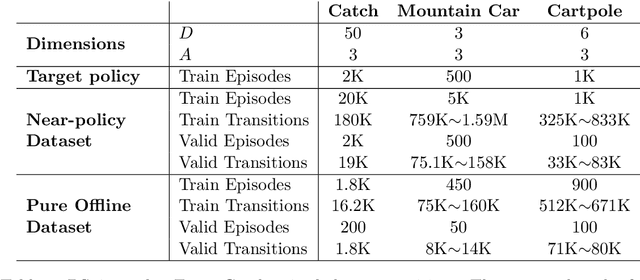
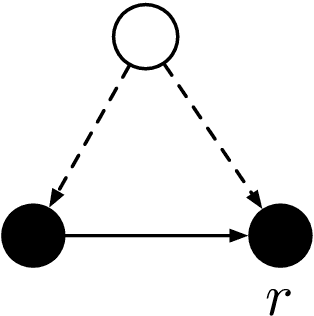
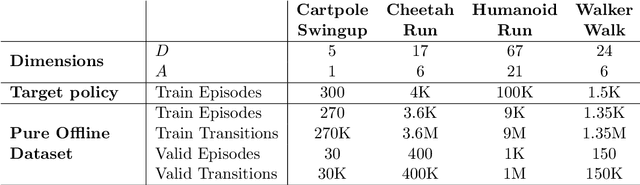
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Q-function estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as model-based techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE. We open-source all our code and datasets at https://github.com/liyuan9988/IVOPEwithACME.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021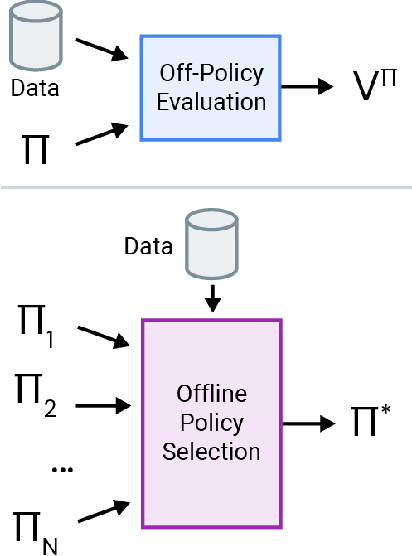
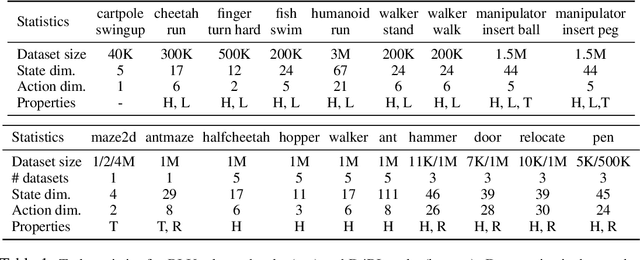
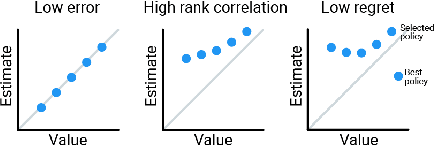
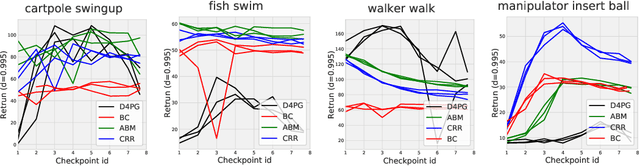
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Regularized Behavior Value Estimation
Mar 17, 2021
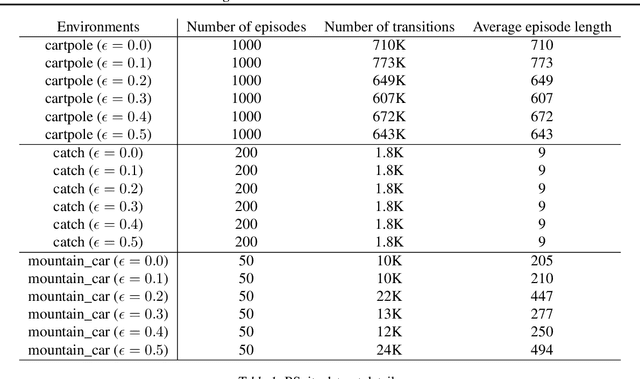
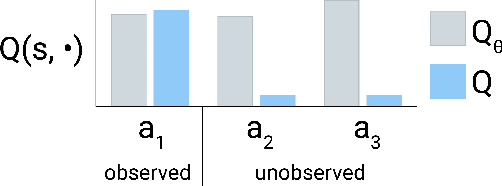
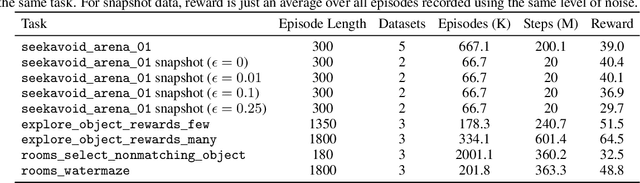
Offline reinforcement learning restricts the learning process to rely only on logged-data without access to an environment. While this enables real-world applications, it also poses unique challenges. One important challenge is dealing with errors caused by the overestimation of values for state-action pairs not well-covered by the training data. Due to bootstrapping, these errors get amplified during training and can lead to divergence, thereby crippling learning. To overcome this challenge, we introduce Regularized Behavior Value Estimation (R-BVE). Unlike most approaches, which use policy improvement during training, R-BVE estimates the value of the behavior policy during training and only performs policy improvement at deployment time. Further, R-BVE uses a ranking regularisation term that favours actions in the dataset that lead to successful outcomes. We provide ample empirical evidence of R-BVE's effectiveness, including state-of-the-art performance on the RL Unplugged ATARI dataset. We also test R-BVE on new datasets, from bsuite and a challenging DeepMind Lab task, and show that R-BVE outperforms other state-of-the-art discrete control offline RL methods.
Myocardial Segmentation of Cardiac MRI Sequences with Temporal Consistency for Coronary Artery Disease Diagnosis
Dec 29, 2020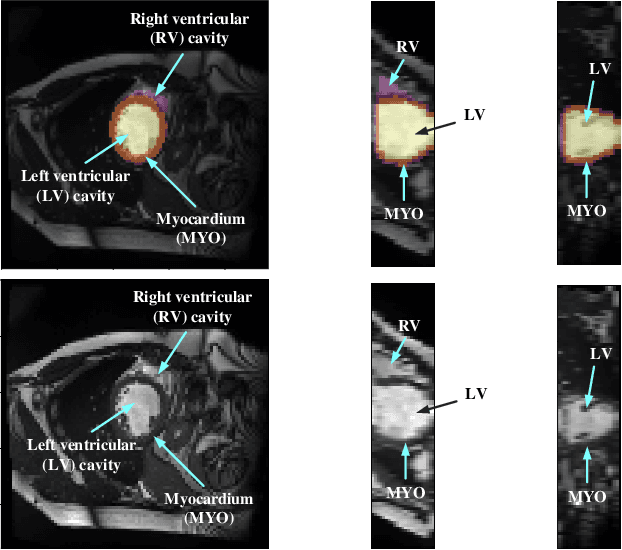
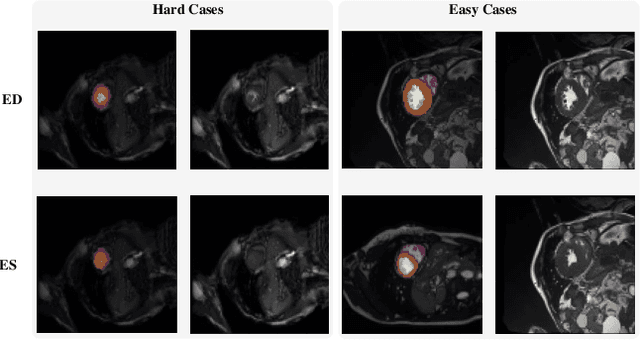
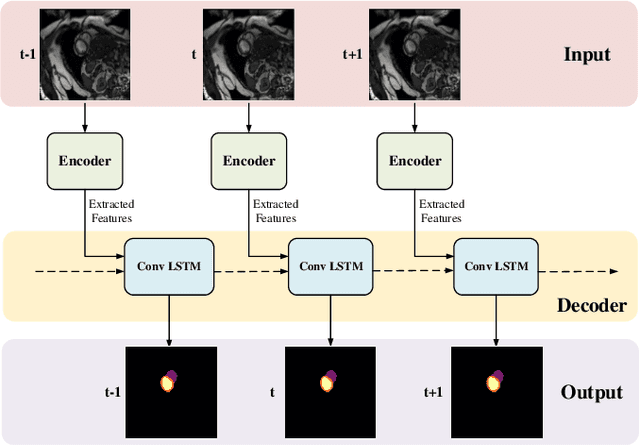
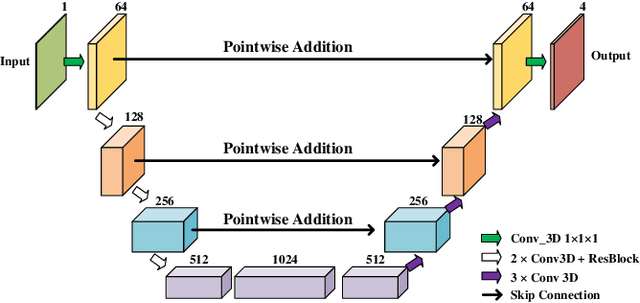
Coronary artery disease (CAD) is the most common cause of death globally, and its diagnosis is usually based on manual myocardial segmentation of Magnetic Resonance Imaging (MRI) sequences. As the manual segmentation is tedious, time-consuming and with low applicability, automatic myocardial segmentation using machine learning techniques has been widely explored recently. However, almost all the existing methods treat the input MRI sequences independently, which fails to capture the temporal information between sequences, e.g., the shape and location information of the myocardium in sequences along time. In this paper, we propose a myocardial segmentation framework for sequence of cardiac MRI (CMR) scanning images of left ventricular cavity, right ventricular cavity, and myocardium. Specifically, we propose to combine conventional networks and recurrent networks to incorporate temporal information between sequences to ensure temporal consistent. We evaluated our framework on the Automated Cardiac Diagnosis Challenge (ACDC) dataset. Experiment results demonstrate that our framework can improve the segmentation accuracy by up to 2% in Dice coefficient.
Synth2Aug: Cross-domain speaker recognition with TTS synthesized speech
Nov 24, 2020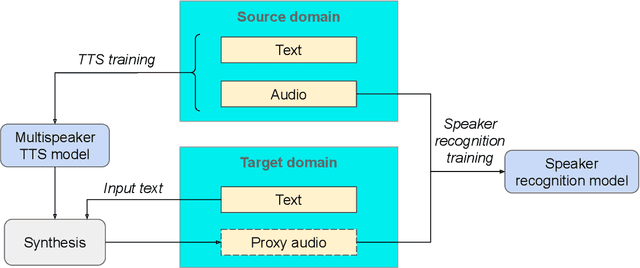
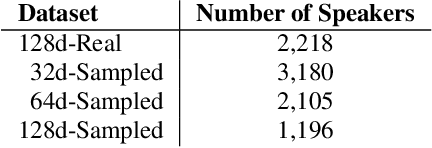
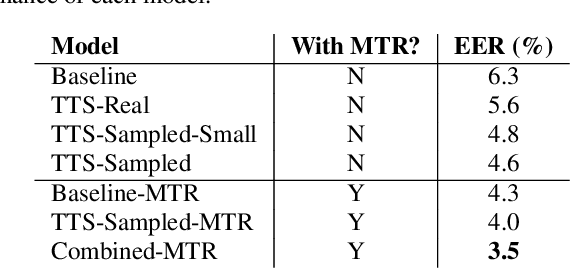
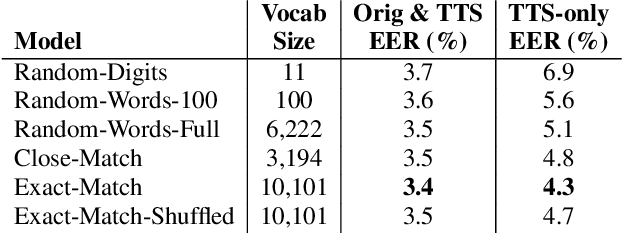
In recent years, Text-To-Speech (TTS) has been used as a data augmentation technique for speech recognition to help complement inadequacies in the training data. Correspondingly, we investigate the use of a multi-speaker TTS system to synthesize speech in support of speaker recognition. In this study we focus the analysis on tasks where a relatively small number of speakers is available for training. We observe on our datasets that TTS synthesized speech improves cross-domain speaker recognition performance and can be combined effectively with multi-style training. Additionally, we explore the effectiveness of different types of text transcripts used for TTS synthesis. Results suggest that matching the textual content of the target domain is a good practice, and if that is not feasible, a transcript with a sufficiently large vocabulary is recommended.
Towards transformation-resilient provenance detection of digital media
Nov 14, 2020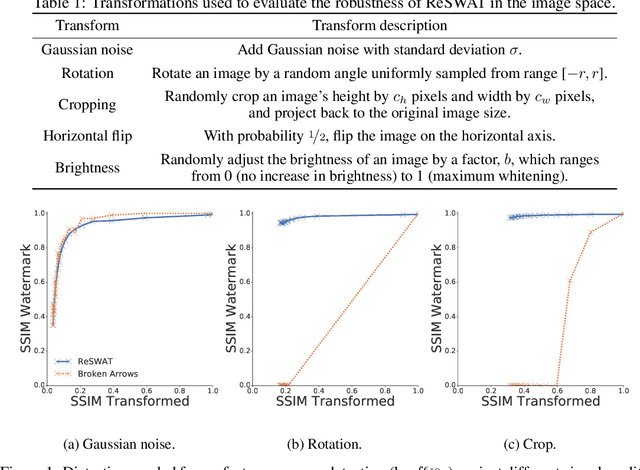
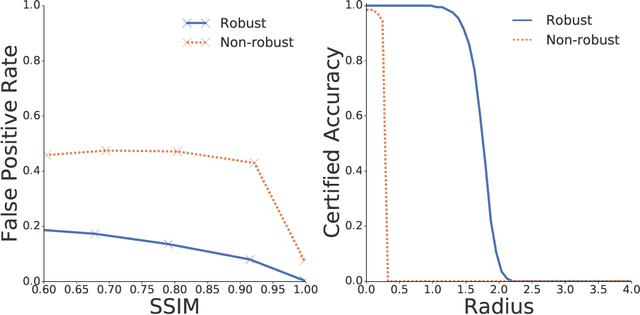

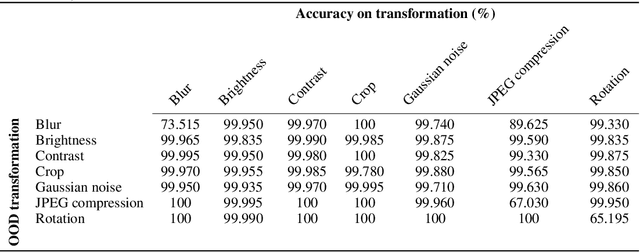
Advancements in deep generative models have made it possible to synthesize images, videos and audio signals that are difficult to distinguish from natural signals, creating opportunities for potential abuse of these capabilities. This motivates the problem of tracking the provenance of signals, i.e., being able to determine the original source of a signal. Watermarking the signal at the time of signal creation is a potential solution, but current techniques are brittle and watermark detection mechanisms can easily be bypassed by applying post-processing transformations (cropping images, shifting pitch in the audio etc.). In this paper, we introduce ReSWAT (Resilient Signal Watermarking via Adversarial Training), a framework for learning transformation-resilient watermark detectors that are able to detect a watermark even after a signal has been through several post-processing transformations. Our detection method can be applied to domains with continuous data representations such as images, videos or sound signals. Experiments on watermarking image and audio signals show that our method can reliably detect the provenance of a signal, even if it has been through several post-processing transformations, and improve upon related work in this setting. Furthermore, we show that for specific kinds of transformations (perturbations bounded in the L2 norm), we can even get formal guarantees on the ability of our model to detect the watermark. We provide qualitative examples of watermarked image and audio samples in https://drive.google.com/open?id=1-yZ0WIGNu2Iez7UpXBjtjVgZu3jJjFga.