 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Dec 29, 2025One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
Evaluating Gemini in an arena for learning
May 30, 2025



Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024



Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Doing the right thing for the right reason: Evaluating artificial moral cognition by probing cost insensitivity
May 29, 2023


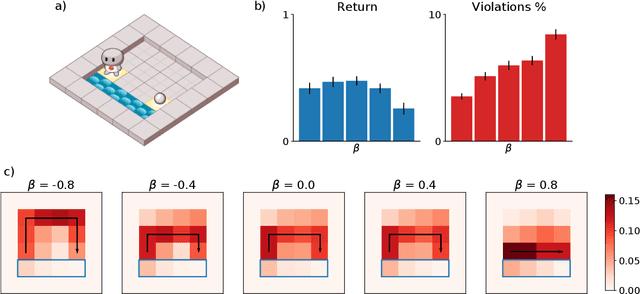
Is it possible to evaluate the moral cognition of complex artificial agents? In this work, we take a look at one aspect of morality: `doing the right thing for the right reasons.' We propose a behavior-based analysis of artificial moral cognition which could also be applied to humans to facilitate like-for-like comparison. Morally-motivated behavior should persist despite mounting cost; by measuring an agent's sensitivity to this cost, we gain deeper insight into underlying motivations. We apply this evaluation to a particular set of deep reinforcement learning agents, trained by memory-based meta-reinforcement learning. Our results indicate that agents trained with a reward function that includes other-regarding preferences perform helping behavior in a way that is less sensitive to increasing cost than agents trained with more self-interested preferences.
Beyond Bayes-optimality: meta-learning what you know you don't know
Oct 12, 2022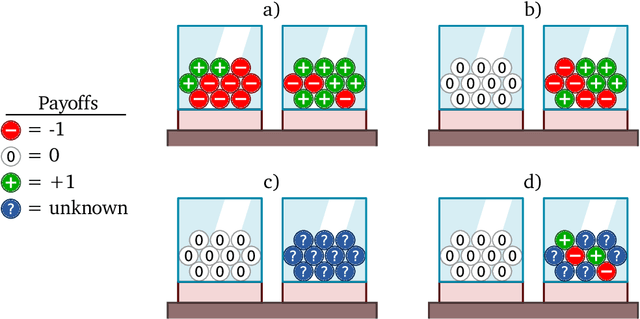



Meta-training agents with memory has been shown to culminate in Bayes-optimal agents, which casts Bayes-optimality as the implicit solution to a numerical optimization problem rather than an explicit modeling assumption. Bayes-optimal agents are risk-neutral, since they solely attune to the expected return, and ambiguity-neutral, since they act in new situations as if the uncertainty were known. This is in contrast to risk-sensitive agents, which additionally exploit the higher-order moments of the return, and ambiguity-sensitive agents, which act differently when recognizing situations in which they lack knowledge. Humans are also known to be averse to ambiguity and sensitive to risk in ways that aren't Bayes-optimal, indicating that such sensitivity can confer advantages, especially in safety-critical situations. How can we extend the meta-learning protocol to generate risk- and ambiguity-sensitive agents? The goal of this work is to fill this gap in the literature by showing that risk- and ambiguity-sensitivity also emerge as the result of an optimization problem using modified meta-training algorithms, which manipulate the experience-generation process of the learner. We empirically test our proposed meta-training algorithms on agents exposed to foundational classes of decision-making experiments and demonstrate that they become sensitive to risk and ambiguity.
Your Policy Regularizer is Secretly an Adversary
Apr 01, 2022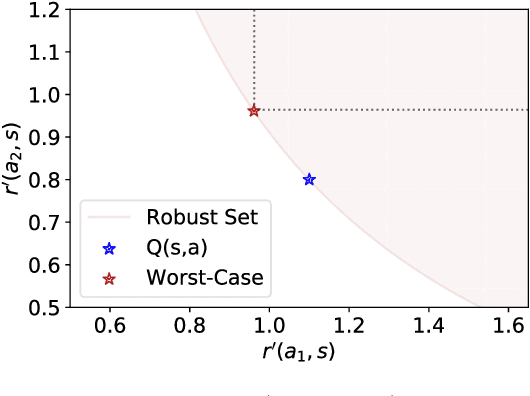

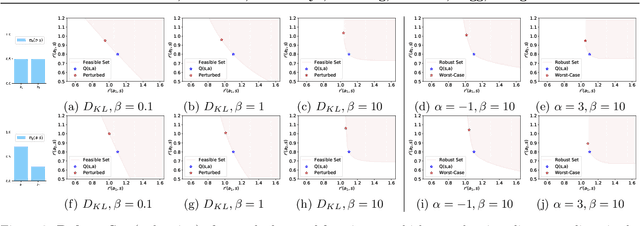

Policy regularization methods such as maximum entropy regularization are widely used in reinforcement learning to improve the robustness of a learned policy. In this paper, we show how this robustness arises from hedging against worst-case perturbations of the reward function, which are chosen from a limited set by an imagined adversary. Using convex duality, we characterize this robust set of adversarial reward perturbations under KL and alpha-divergence regularization, which includes Shannon and Tsallis entropy regularization as special cases. Importantly, generalization guarantees can be given within this robust set. We provide detailed discussion of the worst-case reward perturbations, and present intuitive empirical examples to illustrate this robustness and its relationship with generalization. Finally, we discuss how our analysis complements and extends previous results on adversarial reward robustness and path consistency optimality conditions.
Model-Free Risk-Sensitive Reinforcement Learning
Nov 04, 2021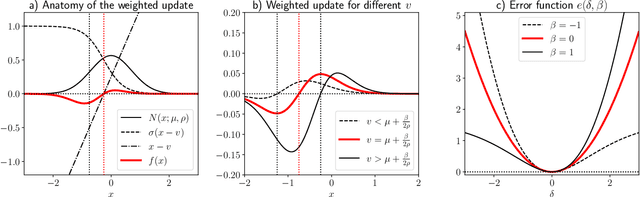
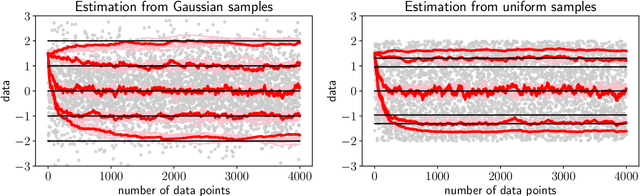

We extend temporal-difference (TD) learning in order to obtain risk-sensitive, model-free reinforcement learning algorithms. This extension can be regarded as modification of the Rescorla-Wagner rule, where the (sigmoidal) stimulus is taken to be either the event of over- or underestimating the TD target. As a result, one obtains a stochastic approximation rule for estimating the free energy from i.i.d. samples generated by a Gaussian distribution with unknown mean and variance. Since the Gaussian free energy is known to be a certainty-equivalent sensitive to the mean and the variance, the learning rule has applications in risk-sensitive decision-making.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021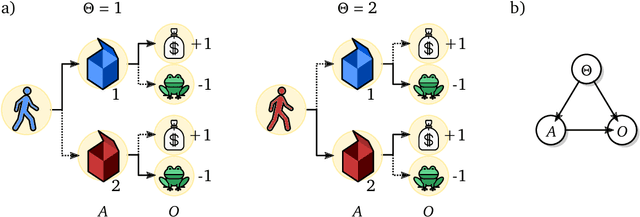
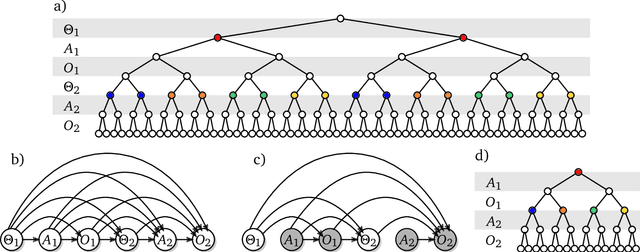
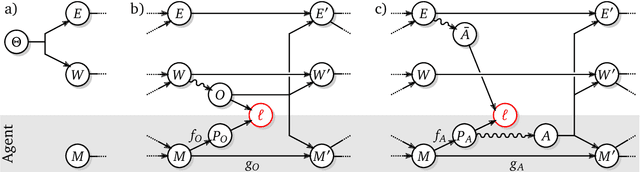
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Causal Analysis of Agent Behavior for AI Safety
Mar 05, 2021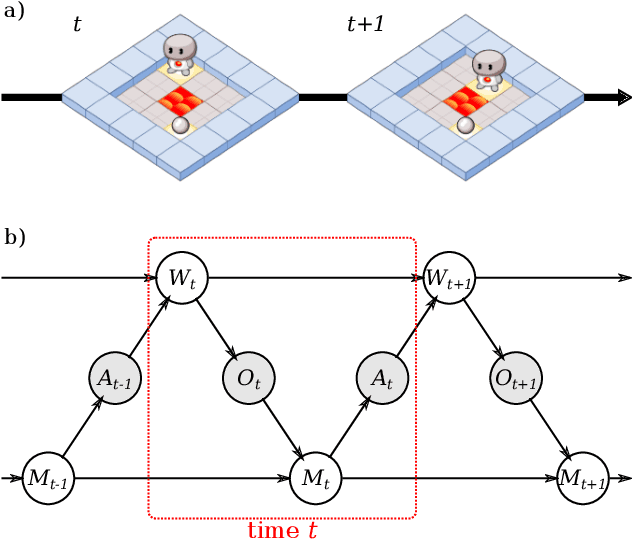
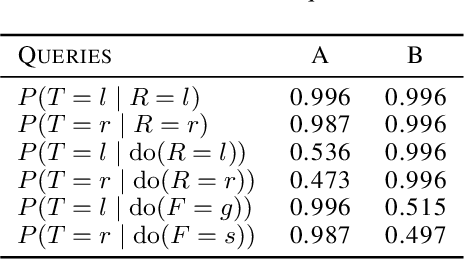
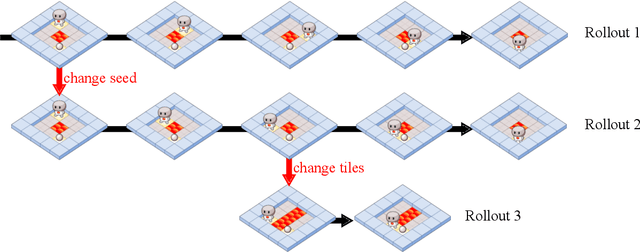
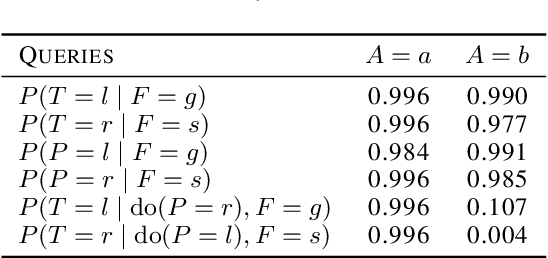
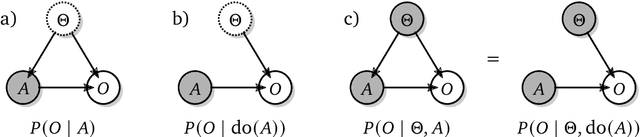
As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Human-interpretable model explainability on high-dimensional data
Oct 14, 2020
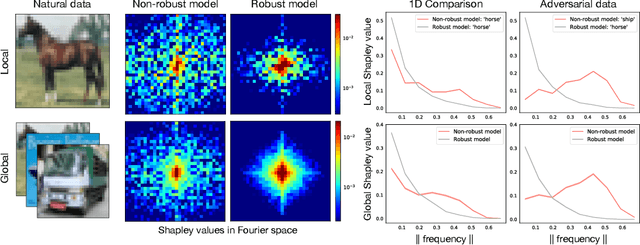
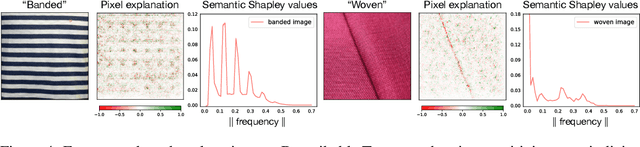
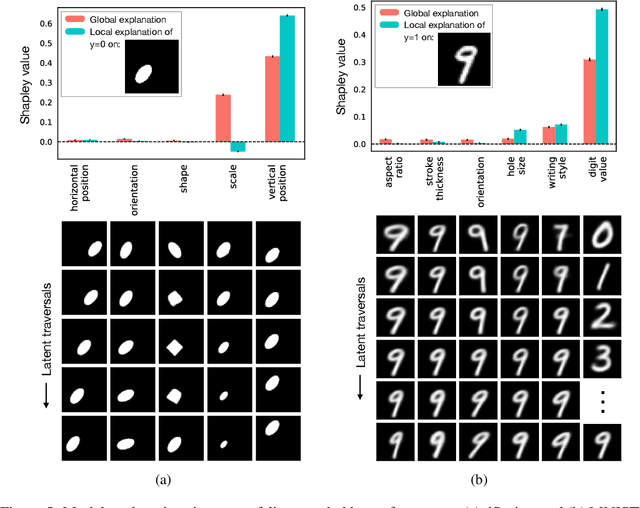
The importance of explainability in machine learning continues to grow, as both neural-network architectures and the data they model become increasingly complex. Unique challenges arise when a model's input features become high dimensional: on one hand, principled model-agnostic approaches to explainability become too computationally expensive; on the other, more efficient explainability algorithms lack natural interpretations for general users. In this work, we introduce a framework for human-interpretable explainability on high-dimensional data, consisting of two modules. First, we apply a semantically meaningful latent representation, both to reduce the raw dimensionality of the data, and to ensure its human interpretability. These latent features can be learnt, e.g. explicitly as disentangled representations or implicitly through image-to-image translation, or they can be based on any computable quantities the user chooses. Second, we adapt the Shapley paradigm for model-agnostic explainability to operate on these latent features. This leads to interpretable model explanations that are both theoretically controlled and computationally tractable. We benchmark our approach on synthetic data and demonstrate its effectiveness on several image-classification tasks.