 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoNRec: Context-Discerning Negative Recommendation with LLMs
Jan 22, 2026Understanding what users like is relatively straightforward; understanding what users dislike, however, remains a challenging and underexplored problem. Research into users' negative preferences has gained increasing importance in modern recommendation systems. Numerous platforms have introduced explicit negative feedback mechanisms and leverage such signals to refine their recommendation models. Beyond traditional business metrics, user experience-driven metrics, such as negative feedback rates, have become critical indicators for evaluating system performance. However, most existing approaches primarily use negative feedback as an auxiliary signal to enhance positive recommendations, paying little attention to directly modeling negative interests, which can be highly valuable in offline applications. Moreover, due to the inherent sparsity of negative feedback data, models often suffer from context understanding biases induced by positive feedback dominance. To address these challenges, we propose the first large language model framework for negative feedback modeling with special designed context-discerning modules. We use semantic ID Representation to replace text-based item descriptions and introduce an item-level alignment task that enhances the LLM's understanding of the semantic context behind negative feedback. Furthermore, we design a Progressive GRPO training paradigm that enables the model to dynamically balance the positive and negative behavioral context utilization. Besides, our investigation further reveals a fundamental misalignment between the conventional next-negative-item prediction objective and users' true negative preferences, which is heavily influenced by the system's recommendation order. To mitigate this, we propose a novel reward function and evaluation metric grounded in multi-day future negative feedback and their collaborative signals.
Multi-Behavior Sequential Modeling with Transition-Aware Graph Attention Network for E-Commerce Recommendation
Jan 21, 2026User interactions on e-commerce platforms are inherently diverse, involving behaviors such as clicking, favoriting, adding to cart, and purchasing. The transitions between these behaviors offer valuable insights into user-item interactions, serving as a key signal for un- derstanding evolving preferences. Consequently, there is growing interest in leveraging multi-behavior data to better capture user intent. Recent studies have explored sequential modeling of multi- behavior data, many relying on transformer-based architectures with polynomial time complexity. While effective, these approaches often incur high computational costs, limiting their applicability in large-scale industrial systems with long user sequences. To address this challenge, we propose the Transition-Aware Graph Attention Network (TGA), a linear-complexity approach for modeling multi-behavior transitions. Unlike traditional trans- formers that treat all behavior pairs equally, TGA constructs a structured sparse graph by identifying informative transitions from three perspectives: (a) item-level transitions, (b) category-level transitions, and (c) neighbor-level transitions. Built upon the structured graph, TGA employs a transition-aware graph Attention mechanism that jointly models user-item interactions and behav- ior transition types, enabling more accurate capture of sequential patterns while maintaining computational efficiency. Experiments show that TGA outperforms all state-of-the-art models while sig- nificantly reducing computational cost. Notably, TGA has been deployed in a large-scale industrial production environment, where it leads to impressive improvements in key business metrics.
Parallel Latent Reasoning for Sequential Recommendation
Jan 06, 2026Capturing complex user preferences from sparse behavioral sequences remains a fundamental challenge in sequential recommendation. Recent latent reasoning methods have shown promise by extending test-time computation through multi-step reasoning, yet they exclusively rely on depth-level scaling along a single trajectory, suffering from diminishing returns as reasoning depth increases. To address this limitation, we propose \textbf{Parallel Latent Reasoning (PLR)}, a novel framework that pioneers width-level computational scaling by exploring multiple diverse reasoning trajectories simultaneously. PLR constructs parallel reasoning streams through learnable trigger tokens in continuous latent space, preserves diversity across streams via global reasoning regularization, and adaptively synthesizes multi-stream outputs through mixture-of-reasoning-streams aggregation. Extensive experiments on three real-world datasets demonstrate that PLR substantially outperforms state-of-the-art baselines while maintaining real-time inference efficiency. Theoretical analysis further validates the effectiveness of parallel reasoning in improving generalization capability. Our work opens new avenues for enhancing reasoning capacity in sequential recommendation beyond existing depth scaling.
AndroidLens: Long-latency Evaluation with Nested Sub-targets for Android GUI Agents
Dec 24, 2025Graphical user interface (GUI) agents can substantially improve productivity by automating frequently executed long-latency tasks on mobile devices. However, existing evaluation benchmarks are still constrained to limited applications, simple tasks, and coarse-grained metrics. To address this, we introduce AndroidLens, a challenging evaluation framework for mobile GUI agents, comprising 571 long-latency tasks in both Chinese and English environments, each requiring an average of more than 26 steps to complete. The framework features: (1) tasks derived from real-world user scenarios across 38 domains, covering complex types such as multi-constraint, multi-goal, and domain-specific tasks; (2) static evaluation that preserves real-world anomalies and allows multiple valid paths to reduce bias; and (3) dynamic evaluation that employs a milestone-based scheme for fine-grained progress measurement via Average Task Progress (ATP). Our evaluation indicates that even the best models reach only a 12.7% task success rate and 50.47% ATP. We also underscore key challenges in real-world environments, including environmental anomalies, adaptive exploration, and long-term memory retention.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
RecGPT-V2 Technical Report
Dec 16, 2025



Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
ChoirRec: Semantic User Grouping via LLMs for Conversion Rate Prediction of Low-Activity Users
Oct 10, 2025Accurately predicting conversion rates (CVR) for low-activity users remains a fundamental challenge in large-scale e-commerce recommender systems.Existing approaches face three critical limitations: (i) reliance on noisy and unreliable behavioral signals; (ii) insufficient user-level information due to the lack of diverse interaction data; and (iii) a systemic training bias toward high-activity users that overshadows the needs of low-activity users.To address these challenges, we propose ChoirRec, a novel framework that leverages the semantic capabilities of Large Language Models (LLMs) to construct semantic user groups and enhance CVR prediction for low-activity users.With a dual-channel architecture designed for robust cross-user knowledge transfer, ChoirRec comprises three components: (i) a Semantic Group Generation module that utilizes LLMs to form reliable, cross-activity user clusters, thereby filtering out noisy signals; (ii) a Group-aware Hierarchical Representation module that enriches sparse user embeddings with informative group-level priors to mitigate data insufficiency; and (iii) a Group-aware Multi-granularity Modual that employs a dual-channel architecture and adaptive fusion mechanism to ensure effective learning and utilization of group knowledge. We conduct extensive offline and online experiments on Taobao, a leading industrial-scale e-commerce platform.ChoirRec improves GAUC by 1.16\% in offline evaluations, while online A/B testing reveals a 7.24\% increase in order volume, highlighting its substantial practical value in real-world applications.
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
Aug 27, 2025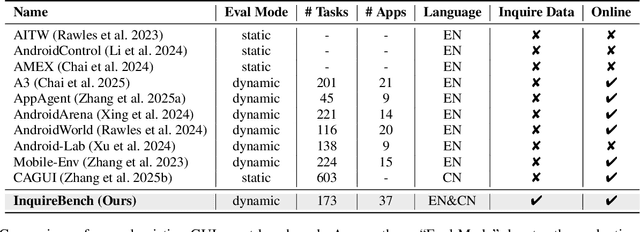
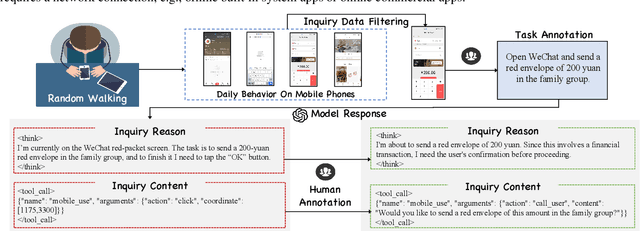

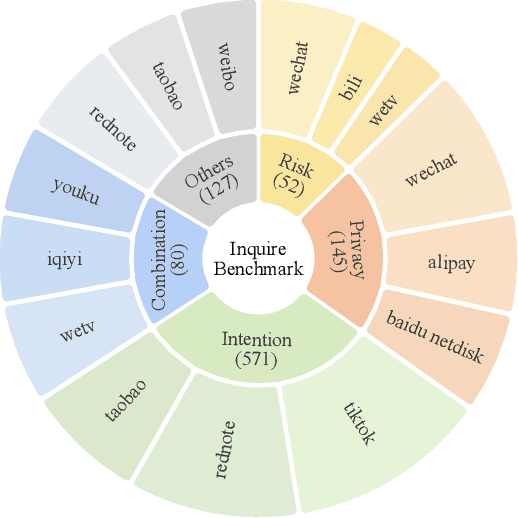
Recent advances in Vision-Language Models (VLMs) have enabled mobile agents to perceive and interact with real-world mobile environments based on human instructions. However, the current fully autonomous paradigm poses potential safety risks when model understanding or reasoning capabilities are insufficient. To address this challenge, we first introduce \textbf{InquireBench}, a comprehensive benchmark specifically designed to evaluate mobile agents' capabilities in safe interaction and proactive inquiry with users, encompassing 5 categories and 22 sub-categories, where most existing VLM-based agents demonstrate near-zero performance. In this paper, we aim to develop an interactive system that actively seeks human confirmation at critical decision points. To achieve this, we propose \textbf{InquireMobile}, a novel model inspired by reinforcement learning, featuring a two-stage training strategy and an interactive pre-action reasoning mechanism. Finally, our model achieves an 46.8% improvement in inquiry success rate and the best overall success rate among existing baselines on InquireBench. We will open-source all datasets, models, and evaluation codes to facilitate development in both academia and industry.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
VulCPE: Context-Aware Cybersecurity Vulnerability Retrieval and Management
May 20, 2025The dynamic landscape of cybersecurity demands precise and scalable solutions for vulnerability management in heterogeneous systems, where configuration-specific vulnerabilities are often misidentified due to inconsistent data in databases like the National Vulnerability Database (NVD). Inaccurate Common Platform Enumeration (CPE) data in NVD further leads to false positives and incomplete vulnerability retrieval. Informed by our systematic analysis of CPE and CVEdeails data, revealing more than 50% vendor name inconsistencies, we propose VulCPE, a framework that standardizes data and models configuration dependencies using a unified CPE schema (uCPE), entity recognition, relation extraction, and graph-based modeling. VulCPE achieves superior retrieval precision (0.766) and coverage (0.926) over existing tools. VulCPE ensures precise, context-aware vulnerability management, enhancing cyber resilience.