 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecAgent: Efficient Mobile GUI Agent with Semantic Context
Mar 09, 2026Mobile Graphical User Interface (GUI) agents powered by multimodal large language models have demonstrated promising capabilities in automating complex smartphone tasks. However, existing approaches face two critical limitations: the scarcity of high-quality multilingual datasets, particularly for non-English ecosystems, and inefficient history representation methods. To address these challenges, we present SecAgent, an efficient mobile GUI agent at 3B scale. We first construct a human-verified Chinese mobile GUI dataset with 18k grounding samples and 121k navigation steps across 44 applications, along with a Chinese navigation benchmark featuring multi-choice action annotations. Building upon this dataset, we propose a semantic context mechanism that distills history screenshots and actions into concise, natural language summaries, significantly reducing computational costs while preserving task-relevant information. Through supervised and reinforcement fine-tuning, SecAgent outperforms similar-scale baselines and achieves performance comparable to 7B-8B models on our and public navigation benchmarks. We will open-source the training dataset, benchmark, model, and code to advance research in multilingual mobile GUI automation.
AndroidLens: Long-latency Evaluation with Nested Sub-targets for Android GUI Agents
Dec 24, 2025Graphical user interface (GUI) agents can substantially improve productivity by automating frequently executed long-latency tasks on mobile devices. However, existing evaluation benchmarks are still constrained to limited applications, simple tasks, and coarse-grained metrics. To address this, we introduce AndroidLens, a challenging evaluation framework for mobile GUI agents, comprising 571 long-latency tasks in both Chinese and English environments, each requiring an average of more than 26 steps to complete. The framework features: (1) tasks derived from real-world user scenarios across 38 domains, covering complex types such as multi-constraint, multi-goal, and domain-specific tasks; (2) static evaluation that preserves real-world anomalies and allows multiple valid paths to reduce bias; and (3) dynamic evaluation that employs a milestone-based scheme for fine-grained progress measurement via Average Task Progress (ATP). Our evaluation indicates that even the best models reach only a 12.7% task success rate and 50.47% ATP. We also underscore key challenges in real-world environments, including environmental anomalies, adaptive exploration, and long-term memory retention.
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
Aug 27, 2025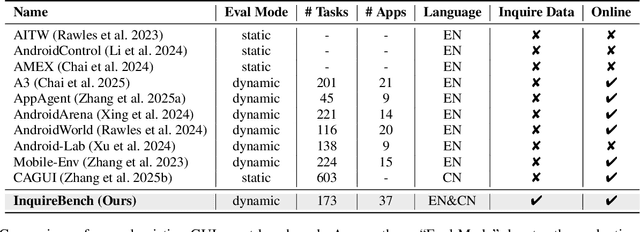
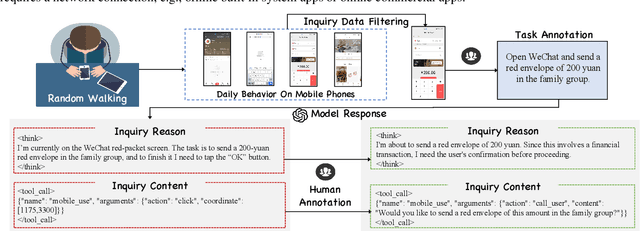

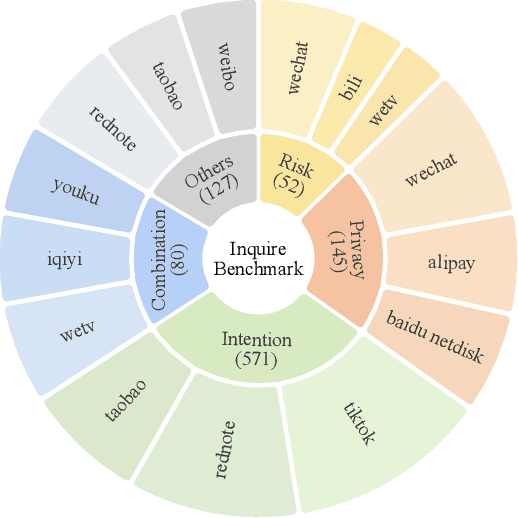
Recent advances in Vision-Language Models (VLMs) have enabled mobile agents to perceive and interact with real-world mobile environments based on human instructions. However, the current fully autonomous paradigm poses potential safety risks when model understanding or reasoning capabilities are insufficient. To address this challenge, we first introduce \textbf{InquireBench}, a comprehensive benchmark specifically designed to evaluate mobile agents' capabilities in safe interaction and proactive inquiry with users, encompassing 5 categories and 22 sub-categories, where most existing VLM-based agents demonstrate near-zero performance. In this paper, we aim to develop an interactive system that actively seeks human confirmation at critical decision points. To achieve this, we propose \textbf{InquireMobile}, a novel model inspired by reinforcement learning, featuring a two-stage training strategy and an interactive pre-action reasoning mechanism. Finally, our model achieves an 46.8% improvement in inquiry success rate and the best overall success rate among existing baselines on InquireBench. We will open-source all datasets, models, and evaluation codes to facilitate development in both academia and industry.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 16, 2022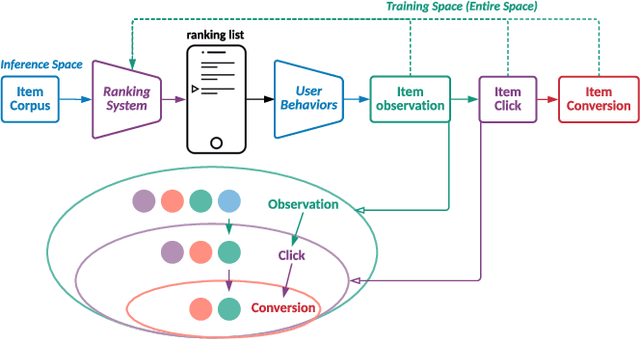

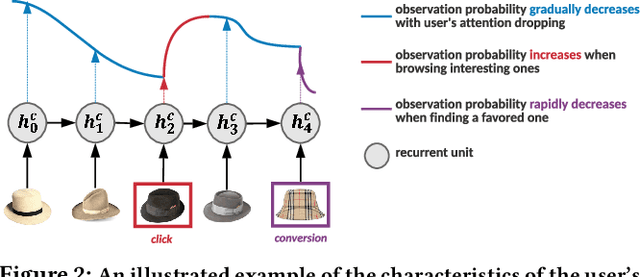
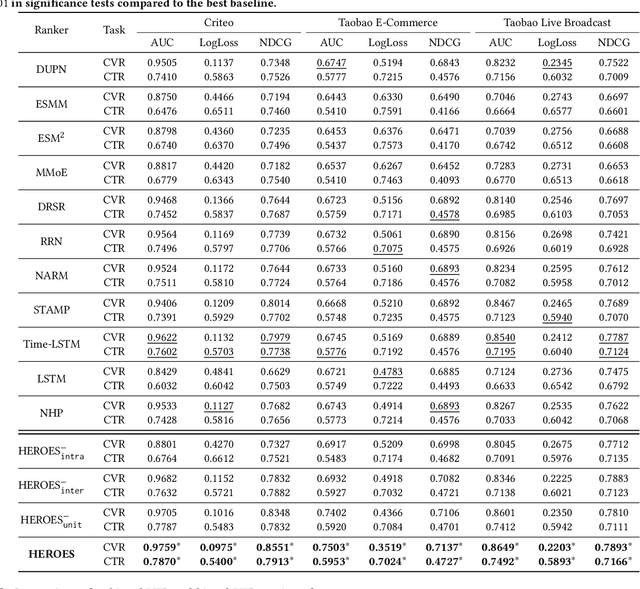
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.