 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Representations for Continual Relation Extraction via Adversarial Class Augmentation
Oct 10, 2022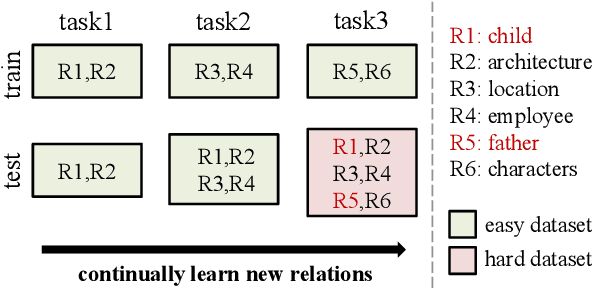
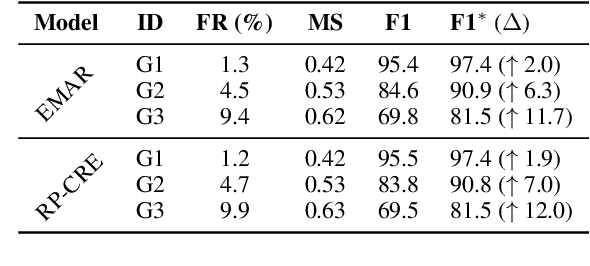

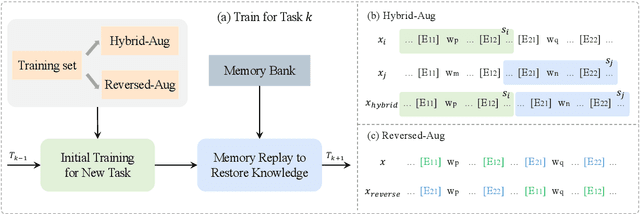
Continual relation extraction (CRE) aims to continually learn new relations from a class-incremental data stream. CRE model usually suffers from catastrophic forgetting problem, i.e., the performance of old relations seriously degrades when the model learns new relations. Most previous work attributes catastrophic forgetting to the corruption of the learned representations as new relations come, with an implicit assumption that the CRE models have adequately learned the old relations. In this paper, through empirical studies we argue that this assumption may not hold, and an important reason for catastrophic forgetting is that the learned representations do not have good robustness against the appearance of analogous relations in the subsequent learning process. To address this issue, we encourage the model to learn more precise and robust representations through a simple yet effective adversarial class augmentation mechanism (ACA), which is easy to implement and model-agnostic. Experimental results show that ACA can consistently improve the performance of state-of-the-art CRE models on two popular benchmarks.
AiM: Taking Answers in Mind to Correct Chinese Cloze Tests in Educational Applications
Aug 26, 2022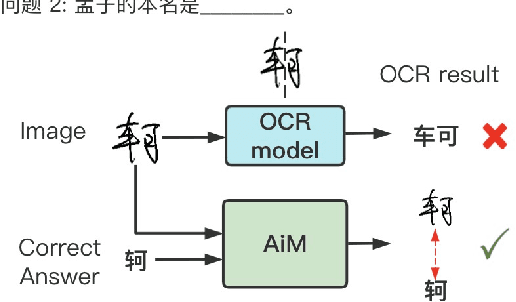
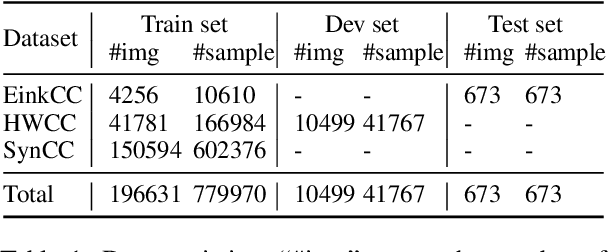
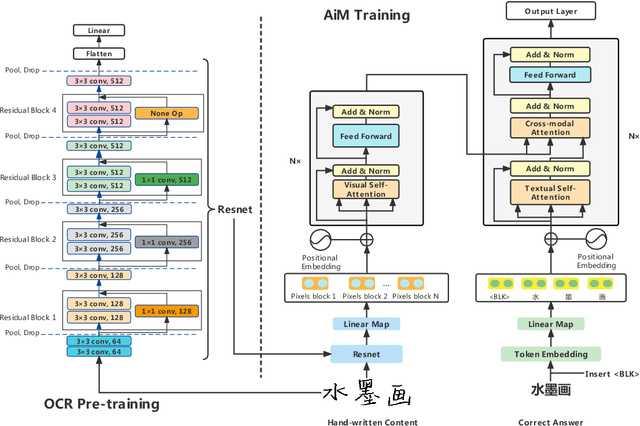
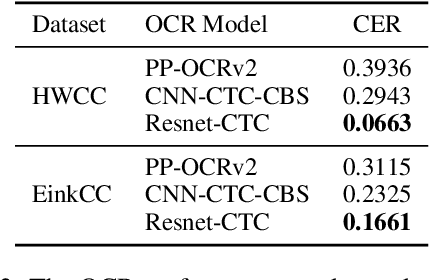
To automatically correct handwritten assignments, the traditional approach is to use an OCR model to recognize characters and compare them to answers. The OCR model easily gets confused on recognizing handwritten Chinese characters, and the textual information of the answers is missing during the model inference. However, teachers always have these answers in mind to review and correct assignments. In this paper, we focus on the Chinese cloze tests correction and propose a multimodal approach (named AiM). The encoded representations of answers interact with the visual information of students' handwriting. Instead of predicting 'right' or 'wrong', we perform the sequence labeling on the answer text to infer which answer character differs from the handwritten content in a fine-grained way. We take samples of OCR datasets as the positive samples for this task, and develop a negative sample augmentation method to scale up the training data. Experimental results show that AiM outperforms OCR-based methods by a large margin. Extensive studies demonstrate the effectiveness of our multimodal approach.
Automatic Context Pattern Generation for Entity Set Expansion
Jul 19, 2022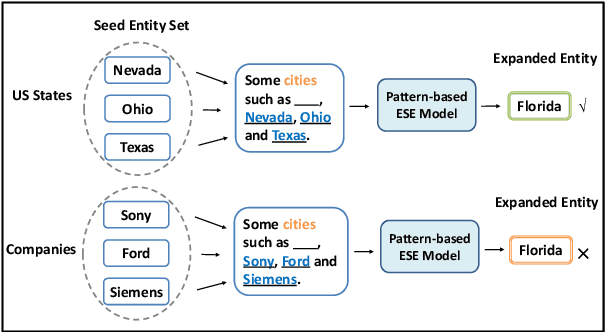

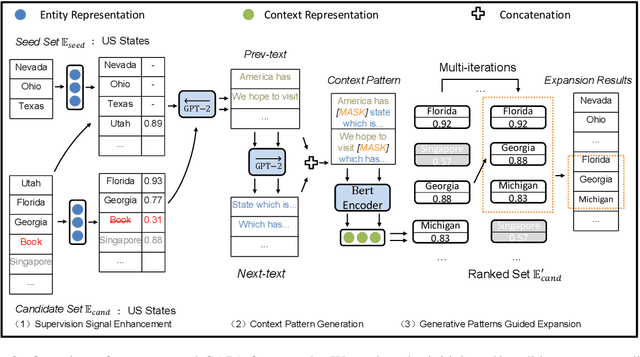
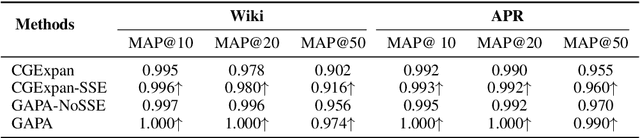
Entity Set Expansion (ESE) is a valuable task that aims to find entities of the target semantic class described by given seed entities. Various NLP and IR downstream applications have benefited from ESE due to its ability to discover knowledge. Although existing bootstrapping methods have achieved great progress, most of them still rely on manually pre-defined context patterns. A non-negligible shortcoming of the pre-defined context patterns is that they cannot be flexibly generalized to all kinds of semantic classes, and we call this phenomenon as "semantic sensitivity". To address this problem, we devise a context pattern generation module that utilizes autoregressive language models (e.g., GPT-2) to automatically generate high-quality context patterns for entities. In addition, we propose the GAPA, a novel ESE framework that leverages the aforementioned GenerAted PAtterns to expand target entities. Extensive experiments and detailed analyses on three widely used datasets demonstrate the effectiveness of our method. All the codes of our experiments will be available for reproducibility.
Contextual Similarity is More Valuable than Character Similarity: Curriculum Learning for Chinese Spell Checking
Jul 17, 2022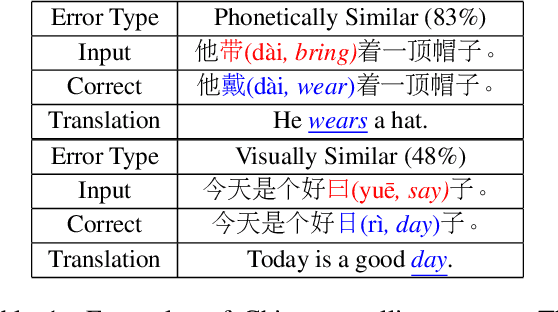
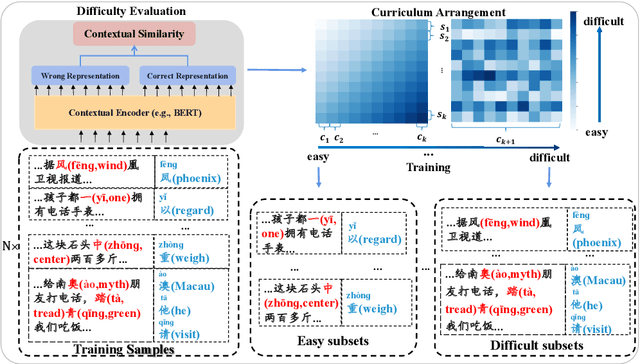
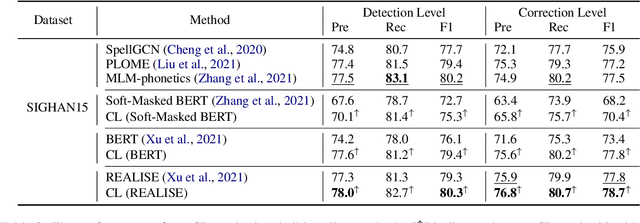
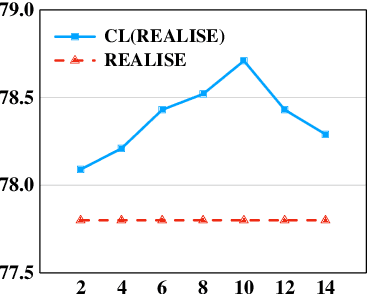
Chinese Spell Checking (CSC) task aims to detect and correct Chinese spelling errors. In recent years, related researches focus on introducing the character similarity from confusion set to enhance the CSC models, ignoring the context of characters that contain richer information. To make better use of contextual similarity, we propose a simple yet effective curriculum learning framework for the CSC task. With the help of our designed model-agnostic framework, existing CSC models will be trained from easy to difficult as humans learn Chinese characters and achieve further performance improvements. Extensive experiments and detailed analyses on widely used SIGHAN datasets show that our method outperforms previous state-of-the-art methods.
CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
May 17, 2022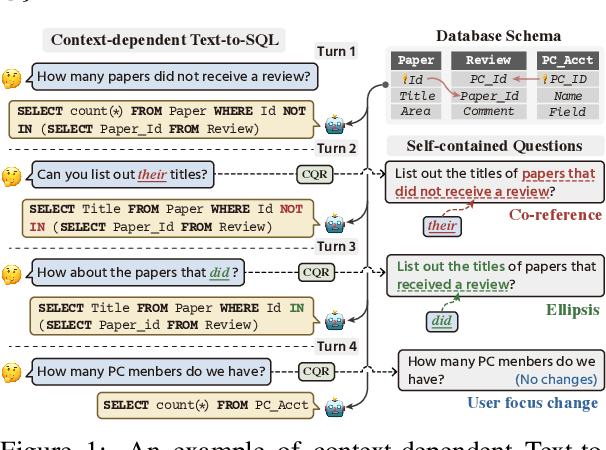

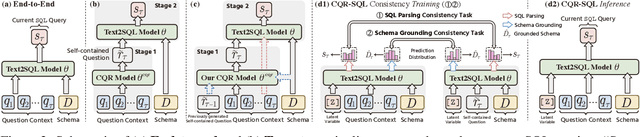
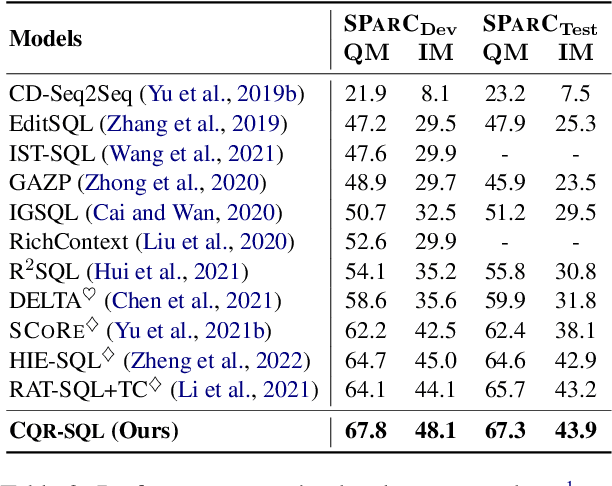
Context-dependent text-to-SQL is the task of translating multi-turn questions into database-related SQL queries. Existing methods typically focus on making full use of history context or previously predicted SQL for currently SQL parsing, while neglecting to explicitly comprehend the schema and conversational dependency, such as co-reference, ellipsis and user focus change. In this paper, we propose CQR-SQL, which uses auxiliary Conversational Question Reformulation (CQR) learning to explicitly exploit schema and decouple contextual dependency for SQL parsing. Specifically, we first present a schema enhanced recursive CQR method to produce domain-relevant self-contained questions. Secondly, we train CQR-SQL models to map the semantics of multi-turn questions and auxiliary self-contained questions into the same latent space through schema grounding consistency task and tree-structured SQL parsing consistency task, which enhances the abilities of SQL parsing by adequately contextual understanding. At the time of writing, our CQR-SQL achieves new state-of-the-art results on two context-dependent text-to-SQL benchmarks SParC and CoSQL.
HPT: Hierarchy-aware Prompt Tuning for Hierarchical Text Classification
Apr 28, 2022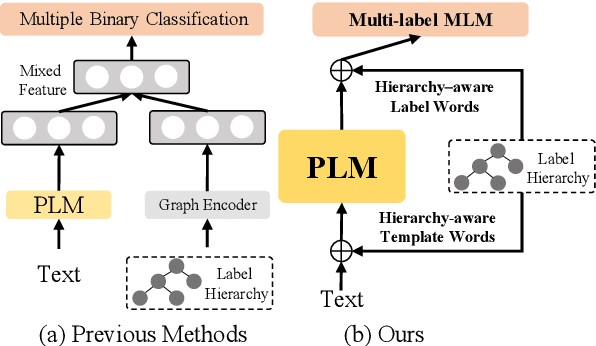
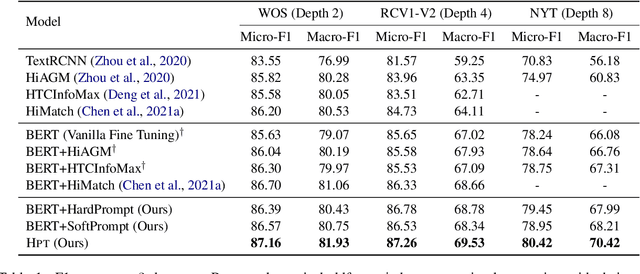
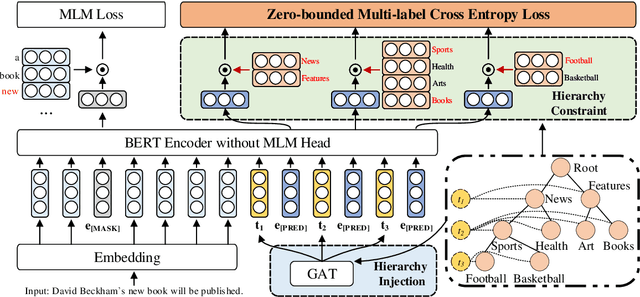
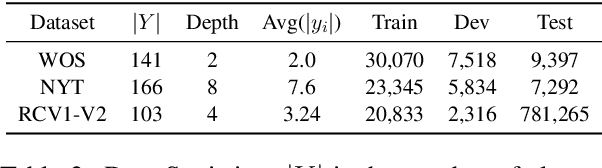
Hierarchical text classification (HTC) is a challenging subtask of multi-label classification due to its complex label hierarchy. Recently, the pretrained language models (PLM) have been widely adopted in HTC through a fine-tuning paradigm. However, in this paradigm, there exists a huge gap between the classification tasks with sophisticated label hierarchy and the masked language model (MLM) pretraining tasks of PLMs and thus the potentials of PLMs can not be fully tapped. To bridge the gap, in this paper, we propose HPT, a Hierarchy-aware Prompt Tuning method to handle HTC from a multi-label MLM perspective. Specifically, we construct dynamic virtual template and label words which take the form of soft prompts to fuse the label hierarchy knowledge and introduce a zero-bounded multi-label cross entropy loss to harmonize the objectives of HTC and MLM. Extensive experiments show HPT achieves the state-of-the-art performances on 3 popular HTC datasets and is adept at handling the imbalance and low resource situations.
SmartSales: Sales Script Extraction and Analysis from Sales Chatlog
Apr 19, 2022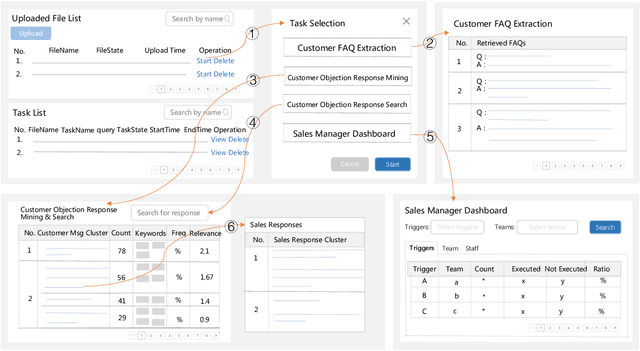
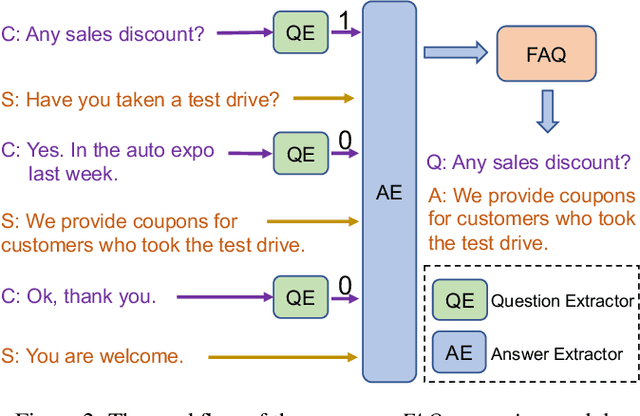
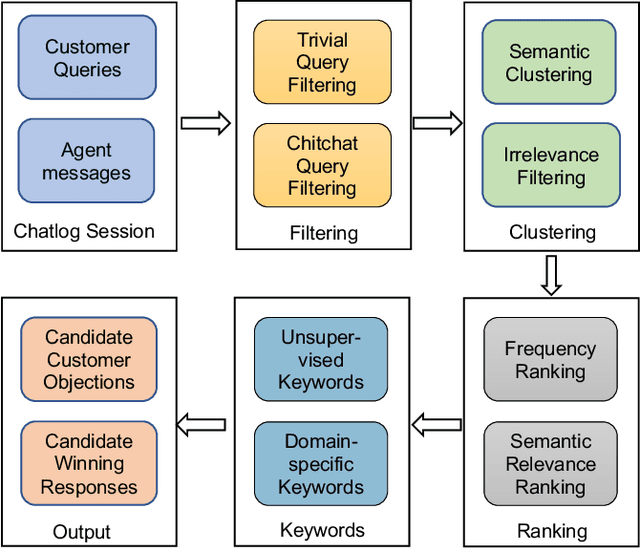
In modern sales applications, automatic script extraction and management greatly decrease the need for human labor to collect the winning sales scripts, which largely boost the success rate for sales and can be shared across the sales teams. In this work, we present the SmartSales system to serve both the sales representatives and managers to attain the sales insights from the large-scale sales chatlog. SmartSales consists of three modules: 1) Customer frequently asked questions (FAQ) extraction aims to enrich the FAQ knowledge base by harvesting high quality customer question-answer pairs from the chatlog. 2) Customer objection response assists the salespeople to figure out the typical customer objections and corresponding winning sales scripts, as well as search for proper sales responses for a certain customer objection. 3) Sales manager dashboard helps sales managers to monitor whether a specific sales representative or team follows the sales standard operating procedures (SOP). The proposed prototype system is empowered by the state-of-the-art conversational intelligence techniques and has been running on the Tencent Cloud to serve the sales teams from several different areas.
Type-Driven Multi-Turn Corrections for Grammatical Error Correction
Mar 17, 2022

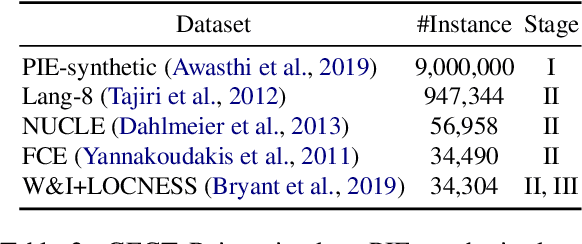
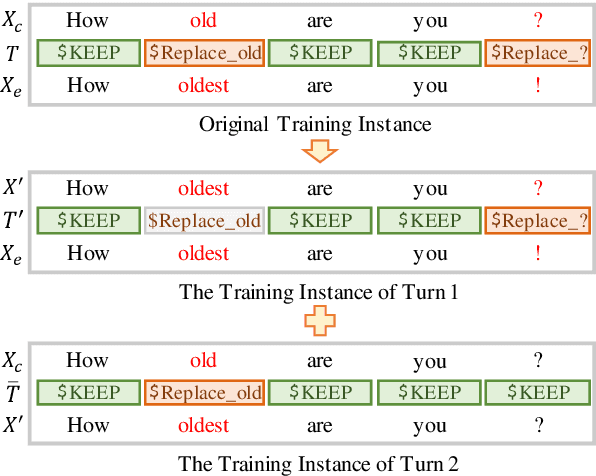
Grammatical Error Correction (GEC) aims to automatically detect and correct grammatical errors. In this aspect, dominant models are trained by one-iteration learning while performing multiple iterations of corrections during inference. Previous studies mainly focus on the data augmentation approach to combat the exposure bias, which suffers from two drawbacks. First, they simply mix additionally-constructed training instances and original ones to train models, which fails to help models be explicitly aware of the procedure of gradual corrections. Second, they ignore the interdependence between different types of corrections. In this paper, we propose a Type-Driven Multi-Turn Corrections approach for GEC. Using this approach, from each training instance, we additionally construct multiple training instances, each of which involves the correction of a specific type of errors. Then, we use these additionally-constructed training instances and the original one to train the model in turn. Experimental results and in-depth analysis show that our approach significantly benefits the model training. Particularly, our enhanced model achieves state-of-the-art single-model performance on English GEC benchmarks. We release our code at Github.
The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking
Mar 02, 2022
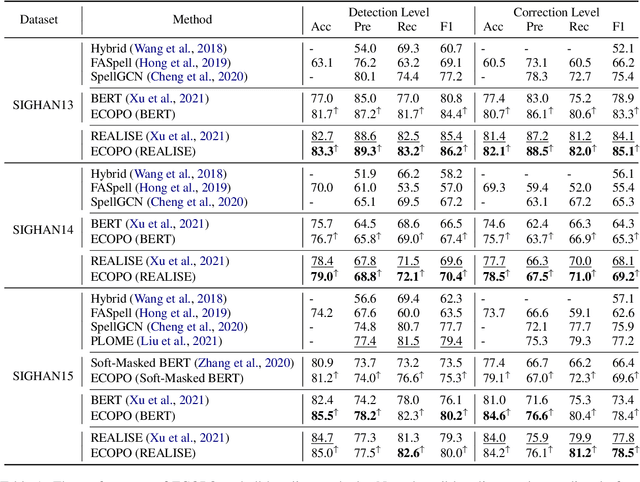
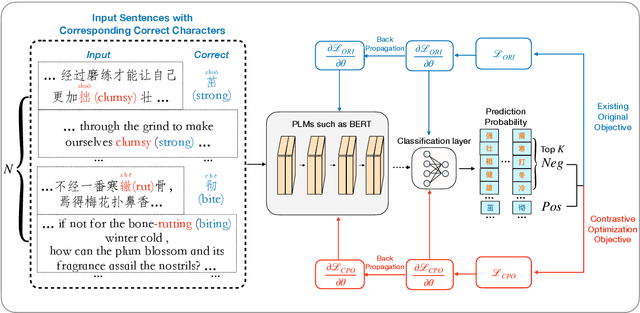
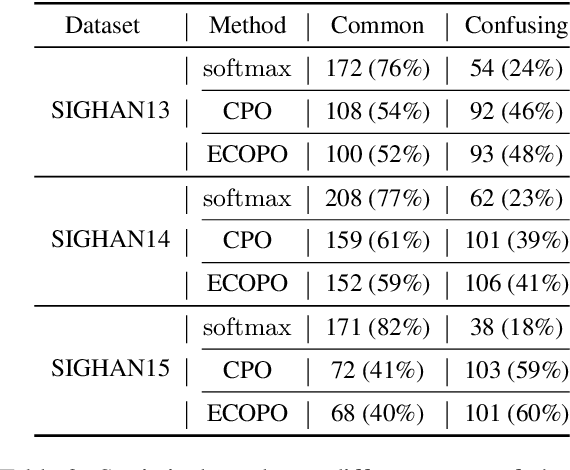
Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors, which are mainly caused by the phonological or visual similarity. Recently, pre-trained language models (PLMs) promote the progress of CSC task. However, there exists a gap between the learned knowledge of PLMs and the goal of CSC task. PLMs focus on the semantics in text and tend to correct the erroneous characters to semantically proper or commonly used ones, but these aren't the ground-truth corrections. To address this issue, we propose an Error-driven COntrastive Probability Optimization (ECOPO) framework for CSC task. ECOPO refines the knowledge representations of PLMs, and guides the model to avoid predicting these common characters through an error-driven way. Particularly, ECOPO is model-agnostic and it can be combined with existing CSC methods to achieve better performance. Extensive experiments and detailed analyses on SIGHAN datasets demonstrate that ECOPO is simple yet effective.
Pretraining without Wordpieces: Learning Over a Vocabulary of Millions of Words
Feb 24, 2022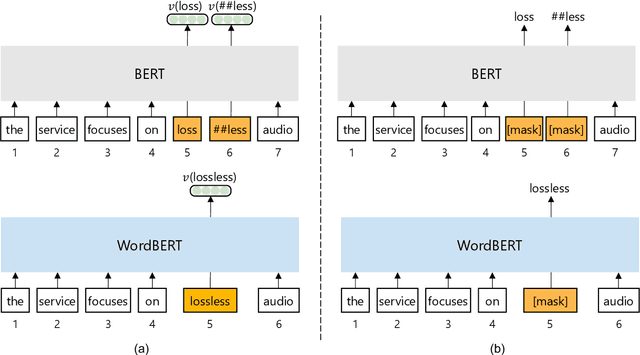
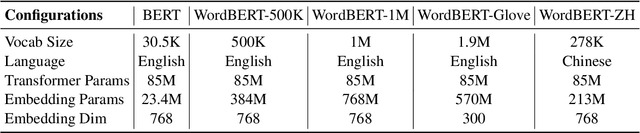
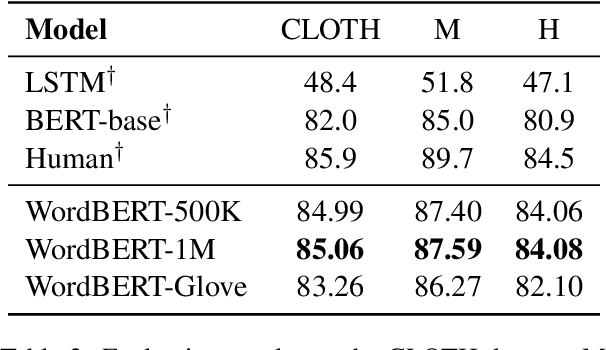
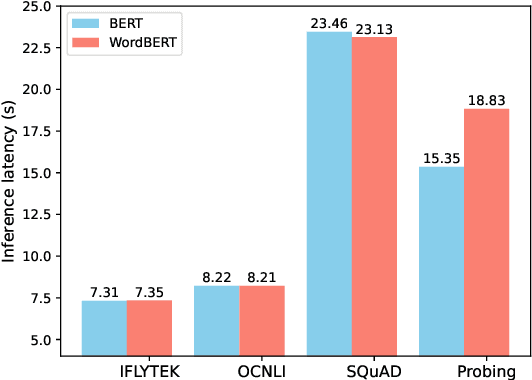
The standard BERT adopts subword-based tokenization, which may break a word into two or more wordpieces (e.g., converting "lossless" to "loss" and "less"). This will bring inconvenience in following situations: (1) what is the best way to obtain the contextual vector of a word that is divided into multiple wordpieces? (2) how to predict a word via cloze test without knowing the number of wordpieces in advance? In this work, we explore the possibility of developing BERT-style pretrained model over a vocabulary of words instead of wordpieces. We call such word-level BERT model as WordBERT. We train models with different vocabulary sizes, initialization configurations and languages. Results show that, compared to standard wordpiece-based BERT, WordBERT makes significant improvements on cloze test and machine reading comprehension. On many other natural language understanding tasks, including POS tagging, chunking and NER, WordBERT consistently performs better than BERT. Model analysis indicates that the major advantage of WordBERT over BERT lies in the understanding for low-frequency words and rare words. Furthermore, since the pipeline is language-independent, we train WordBERT for Chinese language and obtain significant gains on five natural language understanding datasets. Lastly, the analyse on inference speed illustrates WordBERT has comparable time cost to BERT in natural language understanding tasks.