 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Multi-Target Domain Adaptation
Aug 17, 2021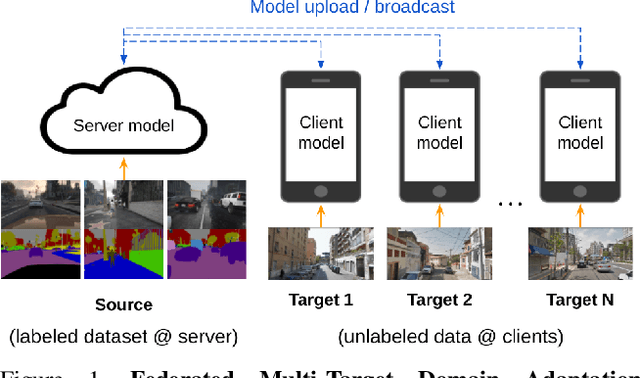
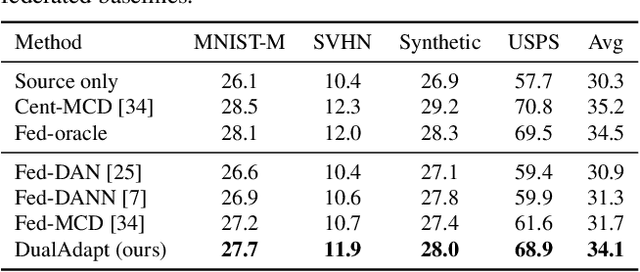
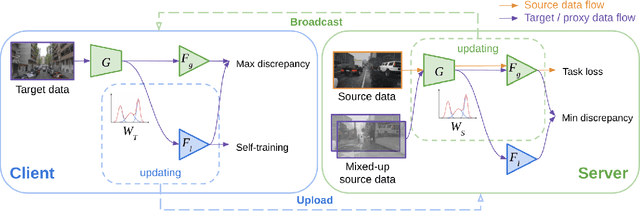
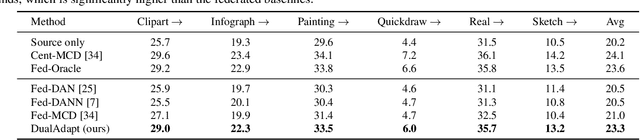
Federated learning methods enable us to train machine learning models on distributed user data while preserving its privacy. However, it is not always feasible to obtain high-quality supervisory signals from users, especially for vision tasks. Unlike typical federated settings with labeled client data, we consider a more practical scenario where the distributed client data is unlabeled, and a centralized labeled dataset is available on the server. We further take the server-client and inter-client domain shifts into account and pose a domain adaptation problem with one source (centralized server data) and multiple targets (distributed client data). Within this new Federated Multi-Target Domain Adaptation (FMTDA) task, we analyze the model performance of exiting domain adaptation methods and propose an effective DualAdapt method to address the new challenges. Extensive experimental results on image classification and semantic segmentation tasks demonstrate that our method achieves high accuracy, incurs minimal communication cost, and requires low computational resources on client devices.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.
BasisNet: Two-stage Model Synthesis for Efficient Inference
May 07, 2021
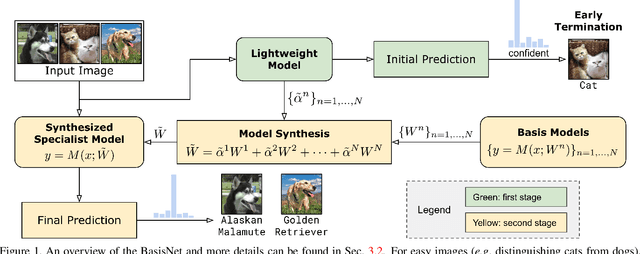

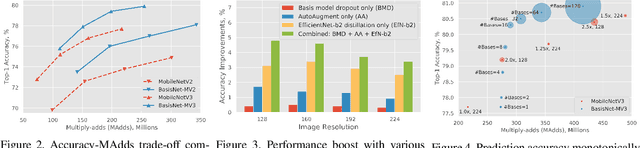
In this work, we present BasisNet which combines recent advancements in efficient neural network architectures, conditional computation, and early termination in a simple new form. Our approach incorporates a lightweight model to preview the input and generate input-dependent combination coefficients, which later controls the synthesis of a more accurate specialist model to make final prediction. The two-stage model synthesis strategy can be applied to any network architectures and both stages are jointly trained. We also show that proper training recipes are critical for increasing generalizability for such high capacity neural networks. On ImageNet classification benchmark, our BasisNet with MobileNets as backbone demonstrated clear advantage on accuracy-efficiency trade-off over several strong baselines. Specifically, BasisNet-MobileNetV3 obtained 80.3% top-1 accuracy with only 290M Multiply-Add operations, halving the computational cost of previous state-of-the-art without sacrificing accuracy. With early termination, the average cost can be further reduced to 198M MAdds while maintaining accuracy of 80.0% on ImageNet.
Joint Representation Learning and Novel Category Discovery on Single- and Multi-modal Data
Apr 27, 2021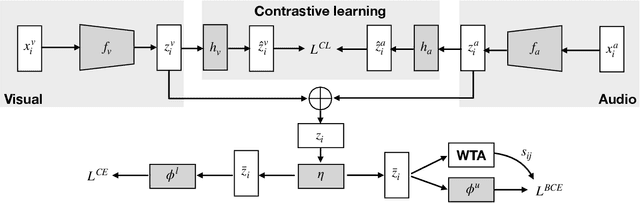
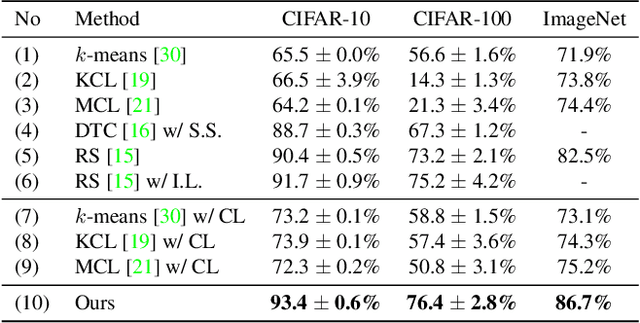
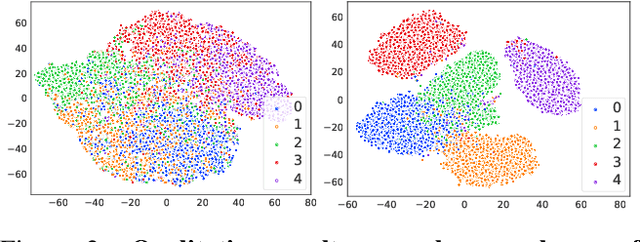
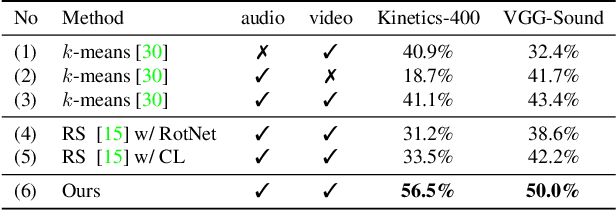
This paper studies the problem of novel category discovery on single- and multi-modal data with labels from different but relevant categories. We present a generic, end-to-end framework to jointly learn a reliable representation and assign clusters to unlabelled data. To avoid over-fitting the learnt embedding to labelled data, we take inspiration from self-supervised representation learning by noise-contrastive estimation and extend it to jointly handle labelled and unlabelled data. In particular, we propose using category discrimination on labelled data and cross-modal discrimination on multi-modal data to augment instance discrimination used in conventional contrastive learning approaches. We further employ Winner-Take-All (WTA) hashing algorithm on the shared representation space to generate pairwise pseudo labels for unlabelled data to better predict cluster assignments. We thoroughly evaluate our framework on large-scale multi-modal video benchmarks Kinetics-400 and VGG-Sound, and image benchmarks CIFAR10, CIFAR100 and ImageNet, obtaining state-of-the-art results.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021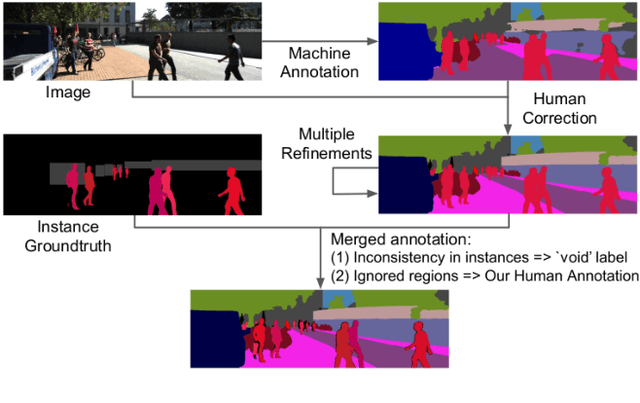
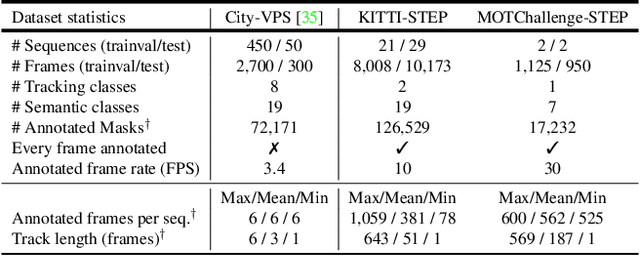


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation
Dec 09, 2020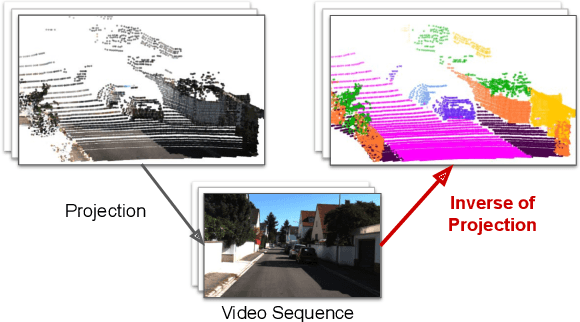
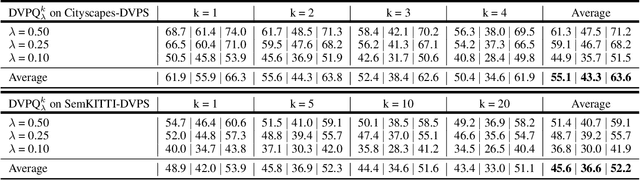
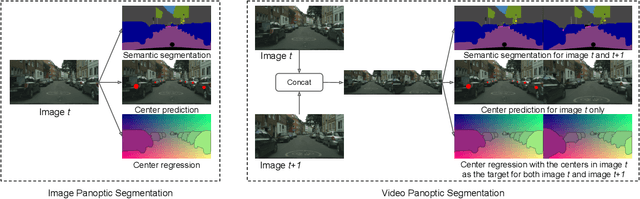
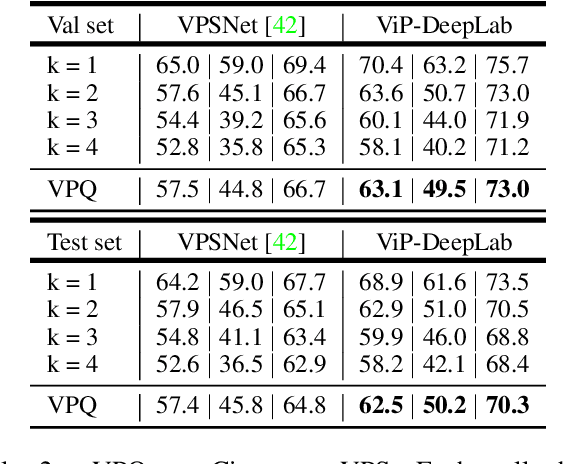
In this paper, we present ViP-DeepLab, a unified model attempting to tackle the long-standing and challenging inverse projection problem in vision, which we model as restoring the point clouds from perspective image sequences while providing each point with instance-level semantic interpretations. Solving this problem requires the vision models to predict the spatial location, semantic class, and temporally consistent instance label for each 3D point. ViP-DeepLab approaches it by jointly performing monocular depth estimation and video panoptic segmentation. We name this joint task as Depth-aware Video Panoptic Segmentation, and propose a new evaluation metric along with two derived datasets for it, which will be made available to the public. On the individual sub-tasks, ViP-DeepLab also achieves state-of-the-art results, outperforming previous methods by 5.1% VPQ on Cityscapes-VPS, ranking 1st on the KITTI monocular depth estimation benchmark, and 1st on KITTI MOTS pedestrian. The datasets and the evaluation codes are made publicly available.
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
Dec 01, 2020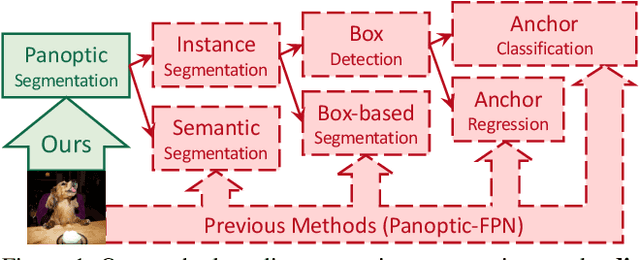
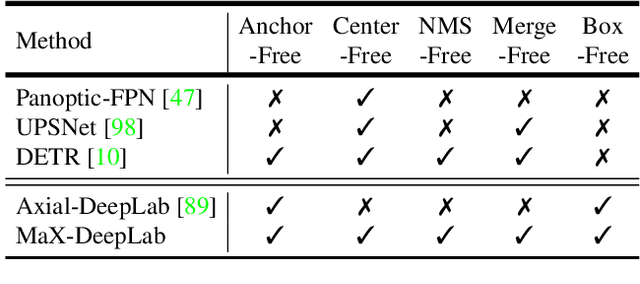

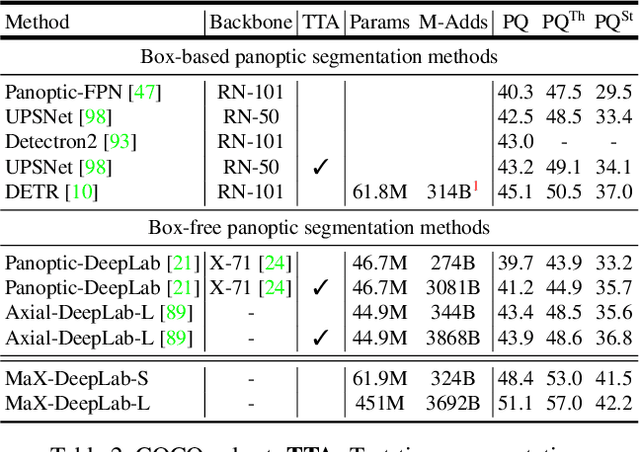
We present MaX-DeepLab, the first end-to-end model for panoptic segmentation. Our approach simplifies the current pipeline that depends heavily on surrogate sub-tasks and hand-designed components, such as box detection, non-maximum suppression, thing-stuff merging, etc. Although these sub-tasks are tackled by area experts, they fail to comprehensively solve the target task. By contrast, our MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching. Our mask transformer employs a dual-path architecture that introduces a global memory path in addition to a CNN path, allowing direct communication with any CNN layers. As a result, MaX-DeepLab shows a significant 7.1% PQ gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. A small variant of MaX-DeepLab improves 3.0% PQ over DETR with similar parameters and M-Adds. Furthermore, MaX-DeepLab, without test time augmentation, achieves new state-of-the-art 51.3% PQ on COCO test-dev set.
Ranking Neural Checkpoints
Nov 23, 2020
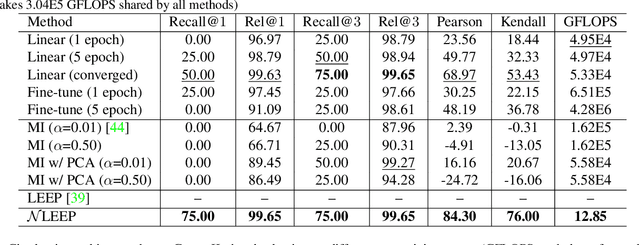
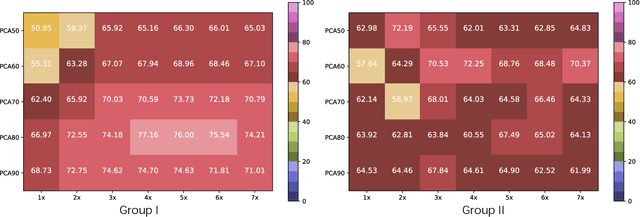
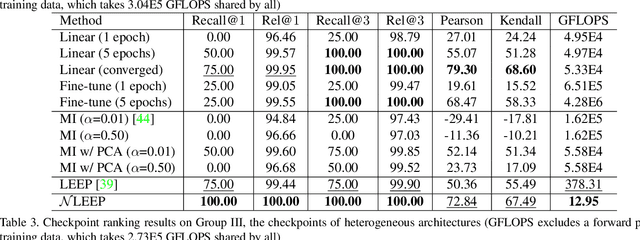
This paper is concerned with ranking many pre-trained deep neural networks (DNNs), called checkpoints, for the transfer learning to a downstream task. Thanks to the broad use of DNNs, we may easily collect hundreds of checkpoints from various sources. Which of them transfers the best to our downstream task of interest? Striving to answer this question thoroughly, we establish a neural checkpoint ranking benchmark (NeuCRaB) and study some intuitive ranking measures. These measures are generic, applying to the checkpoints of different output types without knowing how the checkpoints are pre-trained on which dataset. They also incur low computation cost, making them practically meaningful. Our results suggest that the linear separability of the features extracted by the checkpoints is a strong indicator of transferability. We also arrive at a new ranking measure, NLEEP, which gives rise to the best performance in the experiments.
Boosting Image-based Mutual Gaze Detection using Pseudo 3D Gaze
Oct 15, 2020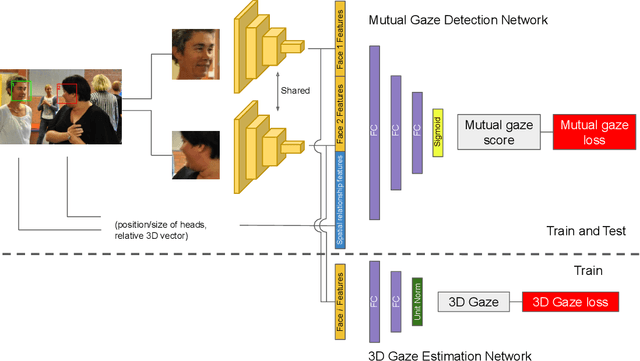
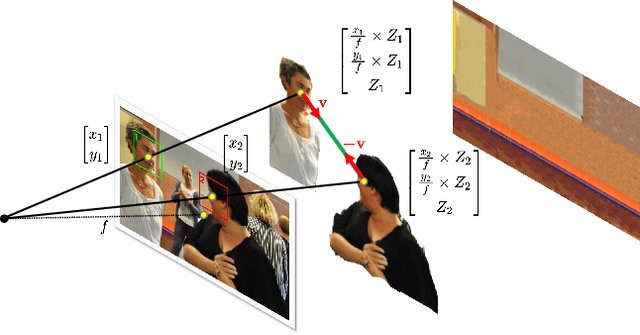


Mutual gaze detection, i.e., predicting whether or not two people are looking at each other, plays an important role in understanding human interactions. In this work, we focus on the task of image-based mutual gaze detection, and propose a simple and effective approach to boost the performance by using an auxiliary 3D gaze estimation task during training. We achieve the performance boost without additional labeling cost by training the 3D gaze estimation branch using pseudo 3D gaze labels deduced from mutual gaze labels. By sharing the head image encoder between the 3D gaze estimation and the mutual gaze detection branches, we achieve better head features than learned by training the mutual gaze detection branch alone. Experimental results on three image datasets show that the proposed approach improves the detection performance significantly without additional annotations. This work also introduces a new image dataset that consists of 33.1K pairs of humans annotated with mutual gaze labels in 29.2K images.
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
Mar 17, 2020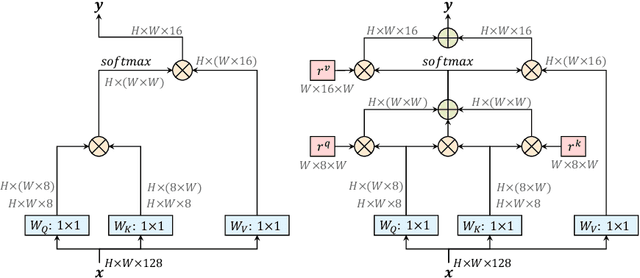
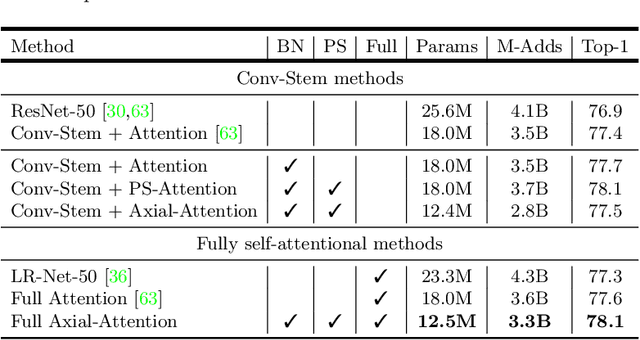
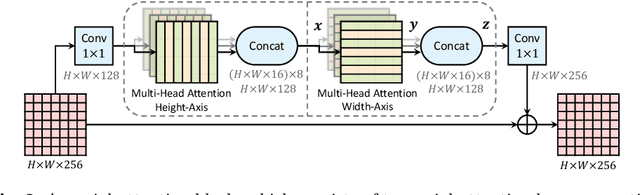
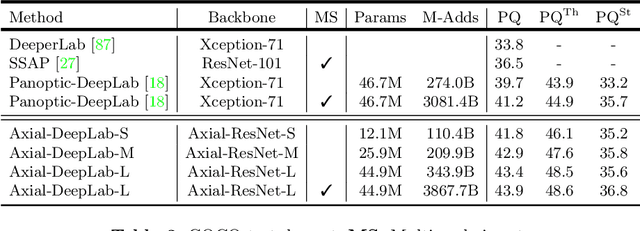
Convolution exploits locality for efficiency at a cost of missing long range context. Self-attention has been adopted to augment CNNs with non-local interactions. Recent works prove it possible to stack self-attention layers to obtain a fully attentional network by restricting the attention to a local region. In this paper, we attempt to remove this constraint by factorizing 2D self-attention into two 1D self-attentions. This reduces computation complexity and allows performing attention within a larger or even global region. In companion, we also propose a position-sensitive self-attention design. Combining both yields our position-sensitive axial-attention layer, a novel building block that one could stack to form axial-attention models for image classification and dense prediction. We demonstrate the effectiveness of our model on four large-scale datasets. In particular, our model outperforms all existing stand-alone self-attention models on ImageNet. Our Axial-DeepLab improves 2.8% PQ over bottom-up state-of-the-art on COCO test-dev. This previous state-of-the-art is attained by our small variant that is 3.8x parameter-efficient and 27x computation-efficient. Axial-DeepLab also achieves state-of-the-art results on Mapillary Vistas and Cityscapes.