 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWi-Fi 8: Embracing the Millimeter-Wave Era
Sep 28, 2023



With the increasing demands in communication, Wi-Fi technology is advancing towards its next generation. Building on the foundation of Wi-Fi 7, millimeter-wave technology is anticipated to converge with Wi-Fi 8 in the near future. In this paper, we look into the millimeter-wave technology and other potential feasible features, providing a comprehensive perspective on the future of Wi-Fi 8. Our simulation results demonstrate that significant performance gains can be achieved, even in the presence of hardware impairments.
IEEE 802.11be Wi-Fi 7: Feature Summary and Performance Evaluation
Sep 27, 2023



While the pace of commercial scale application of Wi-Fi 6 accelerates, the IEEE 802.11 Working Group is about to complete the development of a new amendment standard IEEE 802.11be -- Extremely High Throughput (EHT), also known as Wi-Fi 7, which can be used to meet the demand for the throughput of 4K/8K videos up to tens of Gbps and low-latency video applications such as virtual reality (VR) and augmented reality (AR). Wi-Fi 7 not only scales Wi-Fi 6 with doubled bandwidth, but also supports real-time applications, which brings revolutionary changes to Wi-Fi. In this article, we start by introducing the main objectives and timeline of Wi-Fi 7 and then list the latest key techniques which promote the performance improvement of Wi-Fi 7. Finally, we validate the most critical objectives of Wi-Fi 7 -- the potential up to 30 Gbps throughput and lower latency. System-level simulation results suggest that by combining the new techniques, Wi-Fi 7 achieves 30 Gbps throughput and lower latency than Wi-Fi 6.
Contrastive Learning for Low-light Raw Denoising
May 05, 2023



Image/video denoising in low-light scenes is an extremely challenging problem due to limited photon count and high noise. In this paper, we propose a novel approach with contrastive learning to address this issue. Inspired by the success of contrastive learning used in some high-level computer vision tasks, we bring in this idea to the low-level denoising task. In order to achieve this goal, we introduce a new denoising contrastive regularization (DCR) to exploit the information of noisy images and clean images. In the feature space, DCR makes the denoised image closer to the clean image and far away from the noisy image. In addition, we build a new feature embedding network called Wnet, which is more effective to extract high-frequency information. We conduct the experiments on a real low-light dataset that captures still images taken on a moonless clear night in 0.6 millilux and videos under starlight (no moon present, <0.001 lux). The results show that our method can achieve a higher PSNR and better visual quality compared with existing methods
Bokeh Rendering Based on Adaptive Depth Calibration Network
Feb 21, 2023Bokeh rendering is a popular and effective technique used in photography to create an aesthetically pleasing effect. It is widely used to blur the background and highlight the subject in the foreground, thereby drawing the viewer's attention to the main focus of the image. In traditional digital single-lens reflex cameras (DSLRs), this effect is achieved through the use of a large aperture lens. This allows the camera to capture images with shallow depth-of-field, in which only a small area of the image is in sharp focus, while the rest of the image is blurred. However, the hardware embedded in mobile phones is typically much smaller and more limited than that found in DSLRs. Consequently, mobile phones are not able to capture natural shallow depth-of-field photos, which can be a significant limitation for mobile photography. To address this challenge, in this paper, we propose a novel method for bokeh rendering using the Vision Transformer, a recent and powerful deep learning architecture. Our approach employs an adaptive depth calibration network that acts as a confidence level to compensate for errors in monocular depth estimation. This network is used to supervise the rendering process in conjunction with depth information, allowing for the generation of high-quality bokeh images at high resolutions. Our experiments demonstrate that our proposed method outperforms state-of-the-art methods, achieving about 24.7% improvements on LPIPS and obtaining higher PSNR scores.
Federated contrastive learning models for prostate cancer diagnosis and Gleason grading
Feb 17, 2023



The application effect of artificial intelligence (AI) in the field of medical imaging is remarkable. Robust AI model training requires large datasets, but data collection faces communication, ethics, and privacy protection constraints. Fortunately, federated learning can solve the above problems by coordinating multiple clients to train the model without sharing the original data. In this study, we design a federated contrastive learning framework (FCL) for large-scale pathology images and the heterogeneity challenges. It enhances the model's generalization ability by maximizing the attention consistency between the local client and server models. To alleviate the privacy leakage problem when transferring parameters and verify the robustness of FCL, we use differential privacy to further protect the model by adding noise. We evaluate the effectiveness of FCL on the cancer diagnosis task and Gleason grading task on 19,635 prostate cancer WSIs from multiple clients. In the diagnosis task, the average AUC of 7 clients is 95% when the categories are relatively balanced, and our FCL achieves 97%. In the Gleason grading task, the average Kappa of 6 clients is 0.74, and the Kappa of FCL reaches 0.84. Furthermore, we also validate the robustness of the model on external datasets(one public dataset and two private datasets). In addition, to better explain the classification effect of the model, we show whether the model focuses on the lesion area by drawing a heatmap. Finally, FCL brings a robust, accurate, low-cost AI training model to biomedical research, effectively protecting medical data privacy.
TAOTF: A Two-stage Approximately Orthogonal Training Framework in Deep Neural Networks
Dec 10, 2022The orthogonality constraints, including the hard and soft ones, have been used to normalize the weight matrices of Deep Neural Network (DNN) models, especially the Convolutional Neural Network (CNN) and Vision Transformer (ViT), to reduce model parameter redundancy and improve training stability. However, the robustness to noisy data of these models with constraints is not always satisfactory. In this work, we propose a novel two-stage approximately orthogonal training framework (TAOTF) to find a trade-off between the orthogonal solution space and the main task solution space to solve this problem in noisy data scenarios. In the first stage, we propose a novel algorithm called polar decomposition-based orthogonal initialization (PDOI) to find a good initialization for the orthogonal optimization. In the second stage, unlike other existing methods, we apply soft orthogonal constraints for all layers of DNN model. We evaluate the proposed model-agnostic framework both on the natural image and medical image datasets, which show that our method achieves stable and superior performances to existing methods.
CLOSE: Curriculum Learning On the Sharing Extent Towards Better One-shot NAS
Jul 16, 2022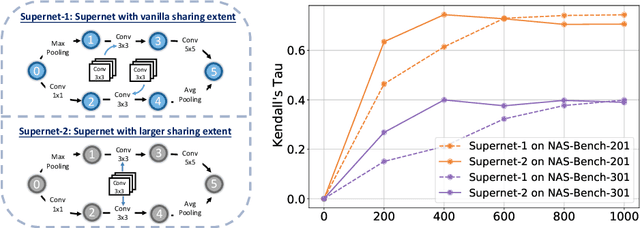
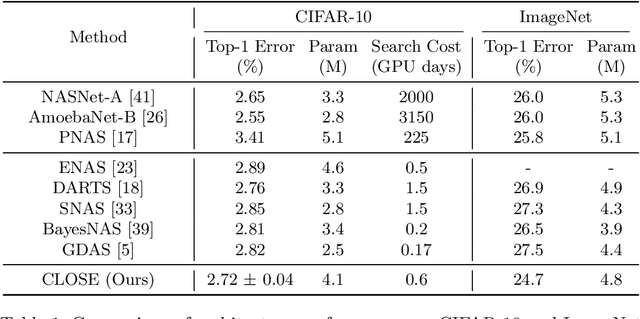
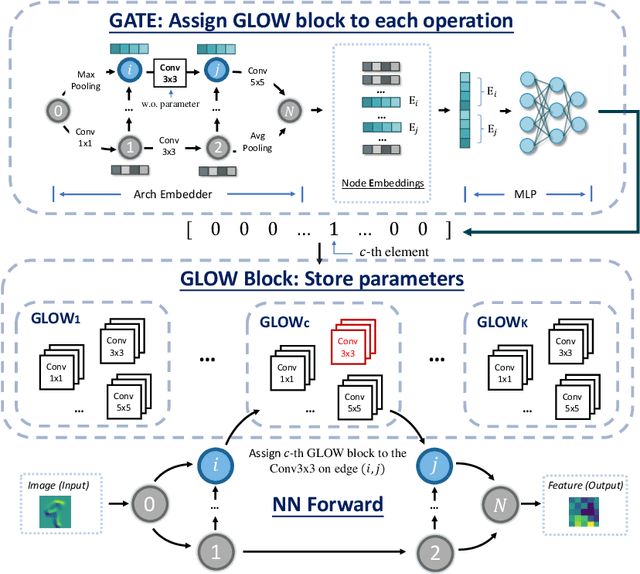

One-shot Neural Architecture Search (NAS) has been widely used to discover architectures due to its efficiency. However, previous studies reveal that one-shot performance estimations of architectures might not be well correlated with their performances in stand-alone training because of the excessive sharing of operation parameters (i.e., large sharing extent) between architectures. Thus, recent methods construct even more over-parameterized supernets to reduce the sharing extent. But these improved methods introduce a large number of extra parameters and thus cause an undesirable trade-off between the training costs and the ranking quality. To alleviate the above issues, we propose to apply Curriculum Learning On Sharing Extent (CLOSE) to train the supernet both efficiently and effectively. Specifically, we train the supernet with a large sharing extent (an easier curriculum) at the beginning and gradually decrease the sharing extent of the supernet (a harder curriculum). To support this training strategy, we design a novel supernet (CLOSENet) that decouples the parameters from operations to realize a flexible sharing scheme and adjustable sharing extent. Extensive experiments demonstrate that CLOSE can obtain a better ranking quality across different computational budget constraints than other one-shot supernets, and is able to discover superior architectures when combined with various search strategies. Code is available at https://github.com/walkerning/aw_nas.
A Fair Federated Learning Framework With Reinforcement Learning
May 26, 2022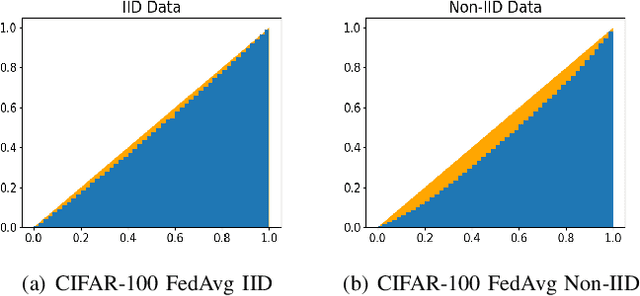
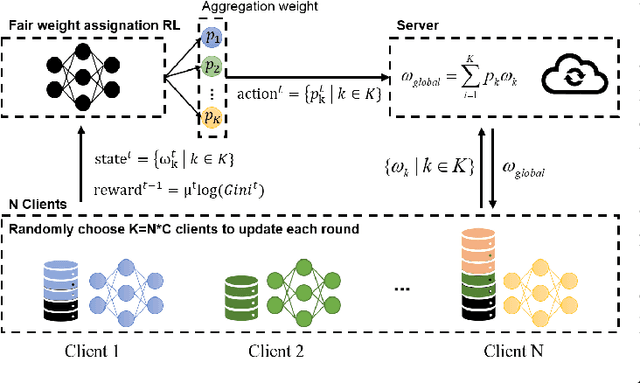
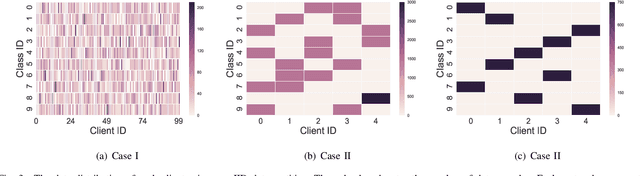
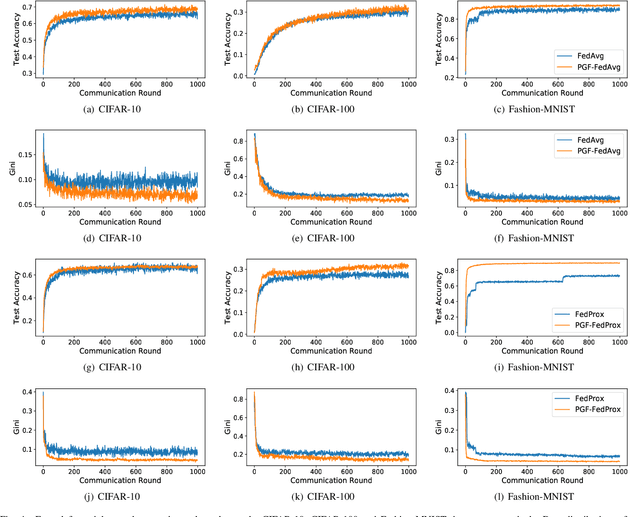
Federated learning (FL) is a paradigm where many clients collaboratively train a model under the coordination of a central server, while keeping the training data locally stored. However, heterogeneous data distributions over different clients remain a challenge to mainstream FL algorithms, which may cause slow convergence, overall performance degradation and unfairness of performance across clients. To address these problems, in this study we propose a reinforcement learning framework, called PG-FFL, which automatically learns a policy to assign aggregation weights to clients. Additionally, we propose to utilize Gini coefficient as the measure of fairness for FL. More importantly, we apply the Gini coefficient and validation accuracy of clients in each communication round to construct a reward function for the reinforcement learning. Our PG-FFL is also compatible to many existing FL algorithms. We conduct extensive experiments over diverse datasets to verify the effectiveness of our framework. The experimental results show that our framework can outperform baseline methods in terms of overall performance, fairness and convergence speed.
Mixed-UNet: Refined Class Activation Mapping for Weakly-Supervised Semantic Segmentation with Multi-scale Inference
May 06, 2022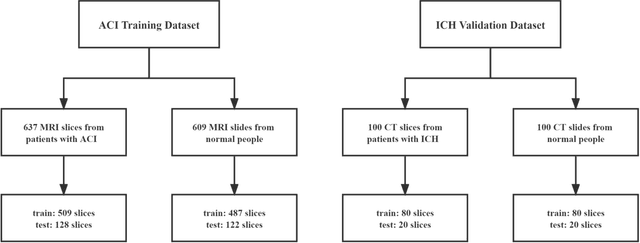
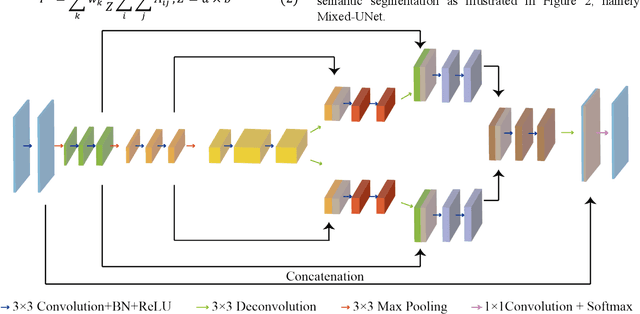
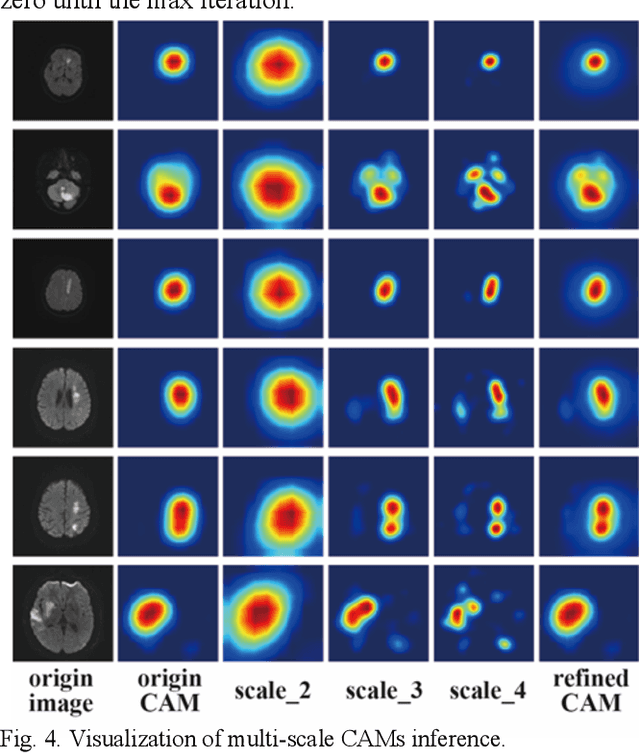
Deep learning techniques have shown great potential in medical image processing, particularly through accurate and reliable image segmentation on magnetic resonance imaging (MRI) scans or computed tomography (CT) scans, which allow the localization and diagnosis of lesions. However, training these segmentation models requires a large number of manually annotated pixel-level labels, which are time-consuming and labor-intensive, in contrast to image-level labels that are easier to obtain. It is imperative to resolve this problem through weakly-supervised semantic segmentation models using image-level labels as supervision since it can significantly reduce human annotation efforts. Most of the advanced solutions exploit class activation mapping (CAM). However, the original CAMs rarely capture the precise boundaries of lesions. In this study, we propose the strategy of multi-scale inference to refine CAMs by reducing the detail loss in single-scale reasoning. For segmentation, we develop a novel model named Mixed-UNet, which has two parallel branches in the decoding phase. The results can be obtained after fusing the extracted features from two branches. We evaluate the designed Mixed-UNet against several prevalent deep learning-based segmentation approaches on our dataset collected from the local hospital and public datasets. The validation results demonstrate that our model surpasses available methods under the same supervision level in the segmentation of various lesions from brain imaging.
RCMNet: A deep learning model assists CAR-T therapy for leukemia
May 06, 2022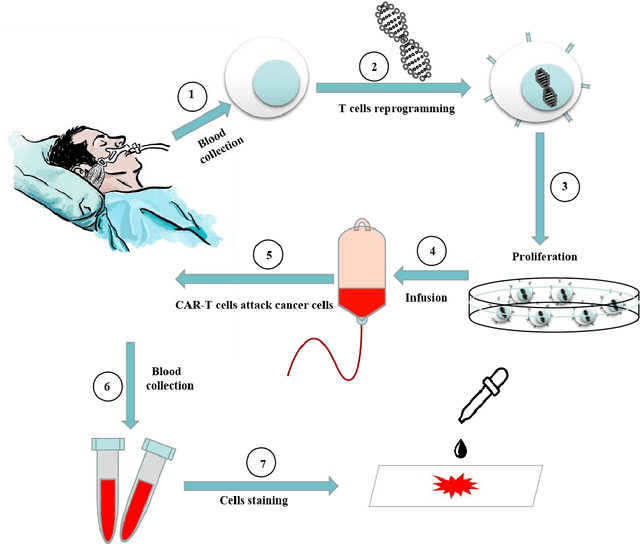
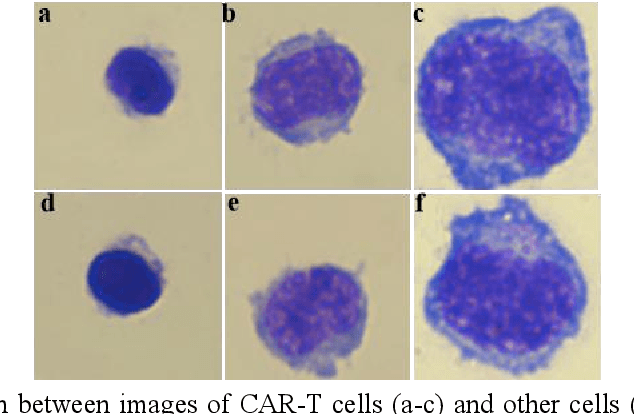

Acute leukemia is a type of blood cancer with a high mortality rate. Current therapeutic methods include bone marrow transplantation, supportive therapy, and chemotherapy. Although a satisfactory remission of the disease can be achieved, the risk of recurrence is still high. Therefore, novel treatments are demanding. Chimeric antigen receptor-T (CAR-T) therapy has emerged as a promising approach to treat and cure acute leukemia. To harness the therapeutic potential of CAR-T cell therapy for blood diseases, reliable cell morphological identification is crucial. Nevertheless, the identification of CAR-T cells is a big challenge posed by their phenotypic similarity with other blood cells. To address this substantial clinical challenge, herein we first construct a CAR-T dataset with 500 original microscopy images after staining. Following that, we create a novel integrated model called RCMNet (ResNet18 with CBAM and MHSA) that combines the convolutional neural network (CNN) and Transformer. The model shows 99.63% top-1 accuracy on the public dataset. Compared with previous reports, our model obtains satisfactory results for image classification. Although testing on the CAR-T cells dataset, a decent performance is observed, which is attributed to the limited size of the dataset. Transfer learning is adapted for RCMNet and a maximum of 83.36% accuracy has been achieved, which is higher than other SOTA models. The study evaluates the effectiveness of RCMNet on a big public dataset and translates it to a clinical dataset for diagnostic applications.