 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Preference Optimization with Provable Noise Tolerance for LLMs
Apr 05, 2024



The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
Causal knowledge engineering: A case study from COVID-19
Mar 21, 2024



COVID-19 appeared abruptly in early 2020, requiring a rapid response amid a context of great uncertainty. Good quality data and knowledge was initially lacking, and many early models had to be developed with causal assumptions and estimations built in to supplement limited data, often with no reliable approach for identifying, validating and documenting these causal assumptions. Our team embarked on a knowledge engineering process to develop a causal knowledge base consisting of several causal BNs for diverse aspects of COVID-19. The unique challenges of the setting lead to experiments with the elicitation approach, and what emerged was a knowledge engineering method we call Causal Knowledge Engineering (CKE). The CKE provides a structured approach for building a causal knowledge base that can support the development of a variety of application-specific models. Here we describe the CKE method, and use our COVID-19 work as a case study to provide a detailed discussion and analysis of the method.
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Mar 21, 2024



The conformational landscape of proteins is crucial to understanding their functionality in complex biological processes. Traditional physics-based computational methods, such as molecular dynamics (MD) simulations, suffer from rare event sampling and long equilibration time problems, hindering their applications in general protein systems. Recently, deep generative modeling techniques, especially diffusion models, have been employed to generate novel protein conformations. However, existing score-based diffusion methods cannot properly incorporate important physical prior knowledge to guide the generation process, causing large deviations in the sampled protein conformations from the equilibrium distribution. In this paper, to overcome these limitations, we propose a force-guided SE(3) diffusion model, ConfDiff, for protein conformation generation. By incorporating a force-guided network with a mixture of data-based score models, ConfDiff can can generate protein conformations with rich diversity while preserving high fidelity. Experiments on a variety of protein conformation prediction tasks, including 12 fast-folding proteins and the Bovine Pancreatic Trypsin Inhibitor (BPTI), demonstrate that our method surpasses the state-of-the-art method.
Editing Massive Concepts in Text-to-Image Diffusion Models
Mar 20, 2024



Text-to-image diffusion models suffer from the risk of generating outdated, copyrighted, incorrect, and biased content. While previous methods have mitigated the issues on a small scale, it is essential to handle them simultaneously in larger-scale real-world scenarios. We propose a two-stage method, Editing Massive Concepts In Diffusion Models (EMCID). The first stage performs memory optimization for each individual concept with dual self-distillation from text alignment loss and diffusion noise prediction loss. The second stage conducts massive concept editing with multi-layer, closed form model editing. We further propose a comprehensive benchmark, named ImageNet Concept Editing Benchmark (ICEB), for evaluating massive concept editing for T2I models with two subtasks, free-form prompts, massive concept categories, and extensive evaluation metrics. Extensive experiments conducted on our proposed benchmark and previous benchmarks demonstrate the superior scalability of EMCID for editing up to 1,000 concepts, providing a practical approach for fast adjustment and re-deployment of T2I diffusion models in real-world applications.
MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small Target Detection
Mar 08, 2024



Recently, infrared small target detection (ISTD) has made significant progress, thanks to the development of basic models. Specifically, the structures combining convolutional networks with transformers can successfully extract both local and global features. However, the disadvantage of the transformer is also inherited, i.e., the quadratic computational complexity to the length of the sequence. Inspired by the recent basic model with linear complexity for long-distance modeling, called Mamba, we explore the potential of this state space model for ISTD task in terms of effectiveness and efficiency in the paper. However, directly applying Mamba achieves poor performance since local features, which are critical to detecting small targets, cannot be fully exploited. Instead, we tailor a Mamba-in-Mamba (MiM-ISTD) structure for efficient ISTD. Specifically, we treat the local patches as "visual sentences" and use the Outer Mamba to explore the global information. We then decompose each visual sentence into sub-patches as "visual words" and use the Inner Mamba to further explore the local information among words in the visual sentence with negligible computational costs. By aggregating the word and sentence features, the MiM-ISTD can effectively explore both global and local information. Experiments on NUAA-SIRST and IRSTD-1k show the superior accuracy and efficiency of our method. Specifically, MiM-ISTD is $10 \times$ faster than the SOTA method and reduces GPU memory usage by 73.4$\%$ when testing on $2048 \times 2048$ image, overcoming the computation and memory constraints on high-resolution infrared images. Source code is available at https://github.com/txchen-USTC/MiM-ISTD.
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Mar 07, 2024



In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts. A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker' baseline to a `stronger' model via incorporating higher quality data, a process we term "weak-to-strong training". The advancements in PixArt-\Sigma are twofold: (1) High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions. (2) Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma's capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
EyeGPT: Ophthalmic Assistant with Large Language Models
Feb 29, 2024



Artificial intelligence (AI) has gained significant attention in healthcare consultation due to its potential to improve clinical workflow and enhance medical communication. However, owing to the complex nature of medical information, large language models (LLM) trained with general world knowledge might not possess the capability to tackle medical-related tasks at an expert level. Here, we introduce EyeGPT, a specialized LLM designed specifically for ophthalmology, using three optimization strategies including role-playing, finetuning, and retrieval-augmented generation. In particular, we proposed a comprehensive evaluation framework that encompasses a diverse dataset, covering various subspecialties of ophthalmology, different users, and diverse inquiry intents. Moreover, we considered multiple evaluation metrics, including accuracy, understandability, trustworthiness, empathy, and the proportion of hallucinations. By assessing the performance of different EyeGPT variants, we identify the most effective one, which exhibits comparable levels of understandability, trustworthiness, and empathy to human ophthalmologists (all Ps>0.05). Overall, ur study provides valuable insights for future research, facilitating comprehensive comparisons and evaluations of different strategies for developing specialized LLMs in ophthalmology. The potential benefits include enhancing the patient experience in eye care and optimizing ophthalmologists' services.
Reliable Conflictive Multi-View Learning
Feb 28, 2024



Multi-view learning aims to combine multiple features to achieve more comprehensive descriptions of data. Most previous works assume that multiple views are strictly aligned. However, real-world multi-view data may contain low-quality conflictive instances, which show conflictive information in different views. Previous methods for this problem mainly focus on eliminating the conflictive data instances by removing them or replacing conflictive views. Nevertheless, real-world applications usually require making decisions for conflictive instances rather than only eliminating them. To solve this, we point out a new Reliable Conflictive Multi-view Learning (RCML) problem, which requires the model to provide decision results and attached reliabilities for conflictive multi-view data. We develop an Evidential Conflictive Multi-view Learning (ECML) method for this problem. ECML first learns view-specific evidence, which could be termed as the amount of support to each category collected from data. Then, we can construct view-specific opinions consisting of decision results and reliability. In the multi-view fusion stage, we propose a conflictive opinion aggregation strategy and theoretically prove this strategy can exactly model the relation of multi-view common and view-specific reliabilities. Experiments performed on 6 datasets verify the effectiveness of ECML.
GCOF: Self-iterative Text Generation for Copywriting Using Large Language Model
Feb 21, 2024
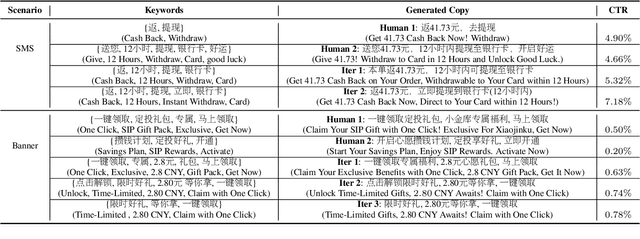
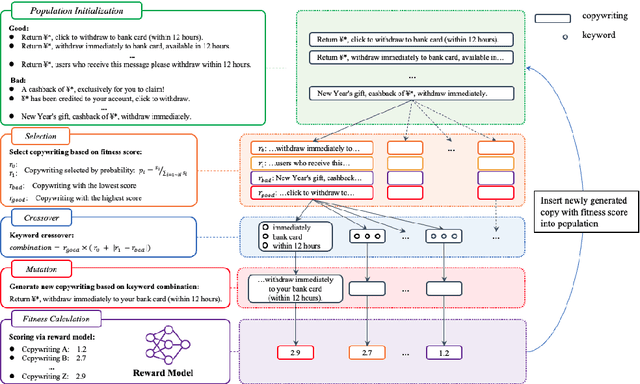

Large language models(LLM) such as ChatGPT have substantially simplified the generation of marketing copy, yet producing content satisfying domain specific requirements, such as effectively engaging customers, remains a significant challenge. In this work, we introduce the Genetic Copy Optimization Framework (GCOF) designed to enhance both efficiency and engagememnt of marketing copy creation. We conduct explicit feature engineering within the prompts of LLM. Additionally, we modify the crossover operator in Genetic Algorithm (GA), integrating it into the GCOF to enable automatic feature engineering. This integration facilitates a self-iterative refinement of the marketing copy. Compared to human curated copy, Online results indicate that copy produced by our framework achieves an average increase in click-through rate (CTR) of over $50\%$.
The practice of qualitative parameterisation in the development of Bayesian networks
Feb 20, 2024

The typical phases of Bayesian network (BN) structured development include specification of purpose and scope, structure development, parameterisation and validation. Structure development is typically focused on qualitative issues and parameterisation quantitative issues, however there are qualitative and quantitative issues that arise in both phases. A common step that occurs after the initial structure has been developed is to perform a rough parameterisation that only captures and illustrates the intended qualitative behaviour of the model. This is done prior to a more rigorous parameterisation, ensuring that the structure is fit for purpose, as well as supporting later development and validation. In our collective experience and in discussions with other modellers, this step is an important part of the development process, but is under-reported in the literature. Since the practice focuses on qualitative issues, despite being quantitative in nature, we call this step qualitative parameterisation and provide an outline of its role in the BN development process.