 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2G: A Multi-View Circuit Graph Benchmark Suite from RTL to GDSII
Apr 09, 2026Graph neural networks (GNNs) are increasingly applied to physical design tasks such as congestion prediction and wirelength estimation, yet progress is hindered by inconsistent circuit representations and the absence of controlled evaluation protocols. We present R2G (RTL-to-GDSII), a multi-view circuit-graph benchmark suite that standardizes five stage-aware views with information parity (every view encodes the same attribute set, differing only in where features attach) over 30 open-source IP cores (up to $10^6$ nodes/edges). R2G provides an end-to-end DEF-to-graph pipeline spanning synthesis, placement, and routing stages, together with loaders, unified splits, domain metrics, and reproducible baselines. By decoupling representation choice from model choice, R2G isolates a confound that prior EDA and graph-ML benchmarks leave uncontrolled. In systematic studies with GINE, GAT, and ResGatedGCN, we find: (i) view choice dominates model choice, with Test R$^2$ varying by more than 0.3 across representations for a fixed GNN; (ii) node-centric views generalize best across both placement and routing; and (iii) decoder-head depth (3--4 layers) is the primary accuracy driver, turning divergent training into near-perfect predictions (R$^2$$>$0.99). Code and datasets are available at https://github.com/ShenShan123/R2G.
The Denario project: Deep knowledge AI agents for scientific discovery
Oct 30, 2025We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Social Media
Sep 26, 2025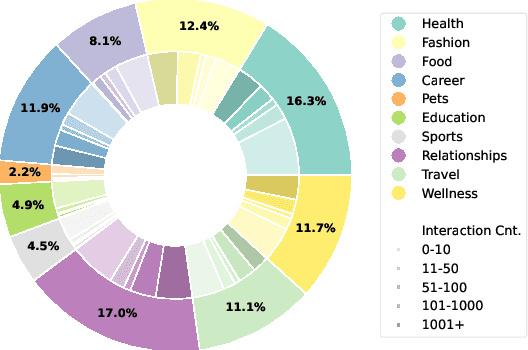
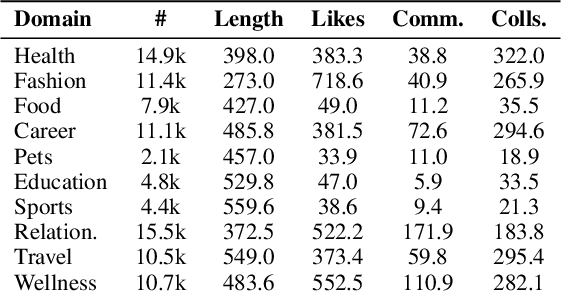

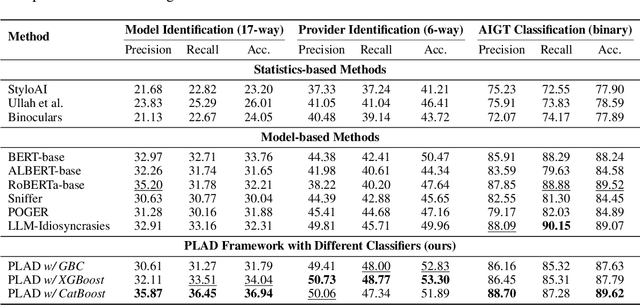
The proliferation of Large Language Models (LLMs) has led to widespread AI-Generated Text (AIGT) on social media platforms, creating unique challenges where content dynamics are driven by user engagement and evolve over time. However, existing datasets mainly depict static AIGT detection. In this work, we introduce RedNote-Vibe, the first longitudinal (5-years) dataset for social media AIGT analysis. This dataset is sourced from Xiaohongshu platform, containing user engagement metrics (e.g., likes, comments) and timestamps spanning from the pre-LLM period to July 2025, which enables research into the temporal dynamics and user interaction patterns of AIGT. Furthermore, to detect AIGT in the context of social media, we propose PsychoLinguistic AIGT Detection Framework (PLAD), an interpretable approach that leverages psycholinguistic features. Our experiments show that PLAD achieves superior detection performance and provides insights into the signatures distinguishing human and AI-generated content. More importantly, it reveals the complex relationship between these linguistic features and social media engagement. The dataset is available at https://github.com/testuser03158/RedNote-Vibe.
Transferable Parasitic Estimation via Graph Contrastive Learning and Label Rebalancing in AMS Circuits
Jul 09, 2025Graph representation learning on Analog-Mixed Signal (AMS) circuits is crucial for various downstream tasks, e.g., parasitic estimation. However, the scarcity of design data, the unbalanced distribution of labels, and the inherent diversity of circuit implementations pose significant challenges to learning robust and transferable circuit representations. To address these limitations, we propose CircuitGCL, a novel graph contrastive learning framework that integrates representation scattering and label rebalancing to enhance transferability across heterogeneous circuit graphs. CircuitGCL employs a self-supervised strategy to learn topology-invariant node embeddings through hyperspherical representation scattering, eliminating dependency on large-scale data. Simultaneously, balanced mean squared error (MSE) and softmax cross-entropy (bsmCE) losses are introduced to mitigate label distribution disparities between circuits, enabling robust and transferable parasitic estimation. Evaluated on parasitic capacitance estimation (edge-level task) and ground capacitance classification (node-level task) across TSMC 28nm AMS designs, CircuitGCL outperforms all state-of-the-art (SOTA) methods, with the $R^2$ improvement of $33.64\% \sim 44.20\%$ for edge regression and F1-score gain of $0.9\times \sim 2.1\times$ for node classification. Our code is available at \href{https://anonymous.4open.science/r/CircuitGCL-099B/README.md}{here}.
An adversarial feature learning based semantic communication method for Human 3D Reconstruction
Nov 23, 2024



With the widespread application of human body 3D reconstruction technology across various fields, the demands for data transmission and processing efficiency continue to rise, particularly in scenarios where network bandwidth is limited and low latency is required. This paper introduces an Adversarial Feature Learning-based Semantic Communication method (AFLSC) for human body 3D reconstruction, which focuses on extracting and transmitting semantic information crucial for the 3D reconstruction task, thereby significantly optimizing data flow and alleviating bandwidth pressure. At the sender's end, we propose a multitask learning-based feature extraction method to capture the spatial layout, keypoints, posture, and depth information from 2D human images, and design a semantic encoding technique based on adversarial feature learning to encode these feature information into semantic data. We also develop a dynamic compression technique to efficiently transmit this semantic data, greatly enhancing transmission efficiency and reducing latency. At the receiver's end, we design an efficient multi-level semantic feature decoding method to convert semantic data back into key image features. Finally, an improved ViT-diffusion model is employed for 3D reconstruction, producing human body 3D mesh models. Experimental results validate the advantages of our method in terms of data transmission efficiency and reconstruction quality, demonstrating its excellent potential for application in bandwidth-limited environments.