 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Walking, Running, and Recovery for Humanoids via State-Dependent Adversarial Motion Priors
May 18, 2026We propose a unified reinforcement learning framework that enables a single policy to perform walking, running, and fall recovery on the Unitree G1 humanoid robot, validated on physical hardware without any explicit mode-switching command at deployment. The framework extends Adversarial Motion Priors (AMP) by replacing the conventional global reference distribution with a state-dependent gate that routes each training transition to one of two discriminators: a dedicated recovery discriminator and a velocity-conditioned locomotion discriminator that jointly covers walking and running. The gate is defined by a single fixed threshold on projected gravity: the recovery discriminator is activated when body tilt exceeds approximately $37^\circ$ from vertical ($|g_z+1|>0.6$); otherwise the locomotion discriminator is used, with the normalized commanded velocity serving as a condition that selects the appropriate reference trajectory between walk and run clips. Only three LAFAN1 reference clips are required to regularize the complete behavior set. At deployment, a single frozen ONNX policy executes at 50\,Hz with no runtime mode logic; hardware experiments demonstrate successful recovery from both prone and supine falls and smooth walk-to-run transitions under the same controller.
Learning Human-Like Badminton Skills for Humanoid Robots
Feb 09, 2026Realizing versatile and human-like performance in high-demand sports like badminton remains a formidable challenge for humanoid robotics. Unlike standard locomotion or static manipulation, this task demands a seamless integration of explosive whole-body coordination and precise, timing-critical interception. While recent advances have achieved lifelike motion mimicry, bridging the gap between kinematic imitation and functional, physics-aware striking without compromising stylistic naturalness is non-trivial. To address this, we propose Imitation-to-Interaction, a progressive reinforcement learning framework designed to evolve a robot from a "mimic" to a capable "striker." Our approach establishes a robust motor prior from human data, distills it into a compact, model-based state representation, and stabilizes dynamics via adversarial priors. Crucially, to overcome the sparsity of expert demonstrations, we introduce a manifold expansion strategy that generalizes discrete strike points into a dense interaction volume. We validate our framework through the mastery of diverse skills, including lifts and drop shots, in simulation. Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot, successfully replicating the kinetic elegance and functional precision of human athletes in the physical world.
Like Playing a Video Game: Spatial-Temporal Optimization of Foot Trajectories for Controlled Football Kicking in Bipedal Robots
Oct 02, 2025Humanoid robot soccer presents several challenges, particularly in maintaining system stability during aggressive kicking motions while achieving precise ball trajectory control. Current solutions, whether traditional position-based control methods or reinforcement learning (RL) approaches, exhibit significant limitations. Model predictive control (MPC) is a prevalent approach for ordinary quadruped and biped robots. While MPC has demonstrated advantages in legged robots, existing studies often oversimplify the leg swing progress, relying merely on simple trajectory interpolation methods. This severely constrains the foot's environmental interaction capability, hindering tasks such as ball kicking. This study innovatively adapts the spatial-temporal trajectory planning method, which has been successful in drone applications, to bipedal robotic systems. The proposed approach autonomously generates foot trajectories that satisfy constraints on target kicking position, velocity, and acceleration while simultaneously optimizing swing phase duration. Experimental results demonstrate that the optimized trajectories closely mimic human kicking behavior, featuring a backswing motion. Simulation and hardware experiments confirm the algorithm's efficiency, with trajectory planning times under 1 ms, and its reliability, achieving nearly 100 % task completion accuracy when the soccer goal is within the range of -90{\deg} to 90{\deg}.
RedNote-Vibe: A Dataset for Capturing Temporal Dynamics of AI-Generated Text in Social Media
Sep 26, 2025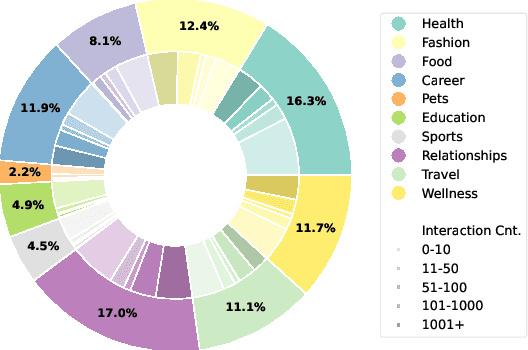
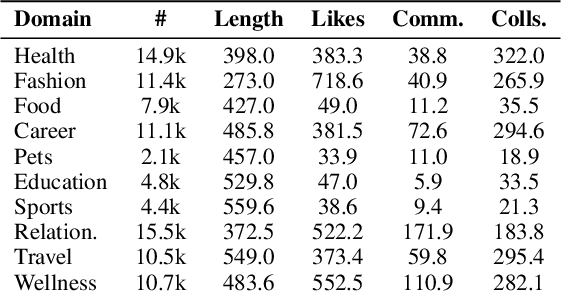

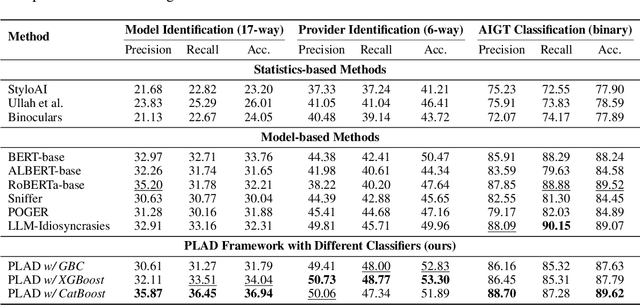
The proliferation of Large Language Models (LLMs) has led to widespread AI-Generated Text (AIGT) on social media platforms, creating unique challenges where content dynamics are driven by user engagement and evolve over time. However, existing datasets mainly depict static AIGT detection. In this work, we introduce RedNote-Vibe, the first longitudinal (5-years) dataset for social media AIGT analysis. This dataset is sourced from Xiaohongshu platform, containing user engagement metrics (e.g., likes, comments) and timestamps spanning from the pre-LLM period to July 2025, which enables research into the temporal dynamics and user interaction patterns of AIGT. Furthermore, to detect AIGT in the context of social media, we propose PsychoLinguistic AIGT Detection Framework (PLAD), an interpretable approach that leverages psycholinguistic features. Our experiments show that PLAD achieves superior detection performance and provides insights into the signatures distinguishing human and AI-generated content. More importantly, it reveals the complex relationship between these linguistic features and social media engagement. The dataset is available at https://github.com/testuser03158/RedNote-Vibe.
Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support
Feb 26, 2025Large language models (LLMs), particularly those with reasoning capabilities, have rapidly advanced in recent years, demonstrating significant potential across a wide range of applications. However, their deployment in healthcare, especially in disease reasoning tasks, is hindered by the challenge of acquiring expert-level cognitive data. In this paper, we introduce Citrus, a medical language model that bridges the gap between clinical expertise and AI reasoning by emulating the cognitive processes of medical experts. The model is trained on a large corpus of simulated expert disease reasoning data, synthesized using a novel approach that accurately captures the decision-making pathways of clinicians. This approach enables Citrus to better simulate the complex reasoning processes involved in diagnosing and treating medical conditions. To further address the lack of publicly available datasets for medical reasoning tasks, we release the last-stage training data, including a custom-built medical diagnostic dialogue dataset. This open-source contribution aims to support further research and development in the field. Evaluations using authoritative benchmarks such as MedQA, covering tasks in medical reasoning and language understanding, show that Citrus achieves superior performance compared to other models of similar size. These results highlight Citrus potential to significantly enhance medical decision support systems, providing a more accurate and efficient tool for clinical decision-making.
Generating Fundus Fluorescence Angiography Images from Structure Fundus Images Using Generative Adversarial Networks
Jun 18, 2020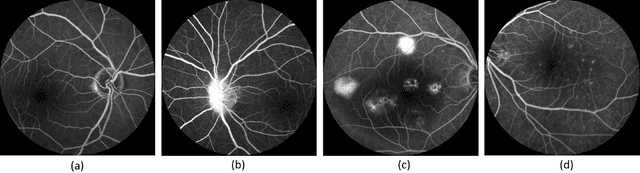
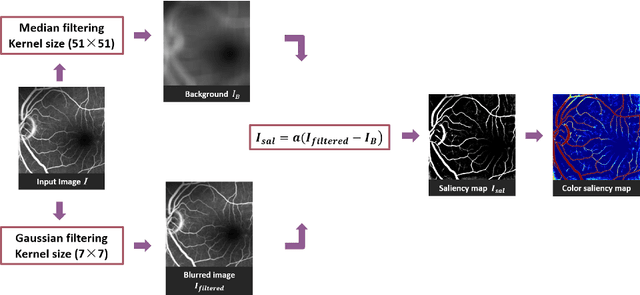
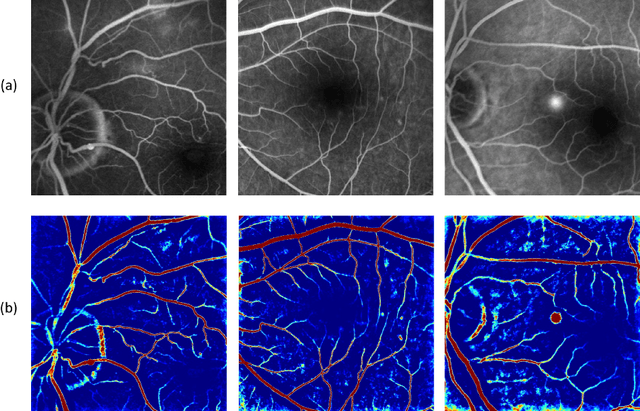
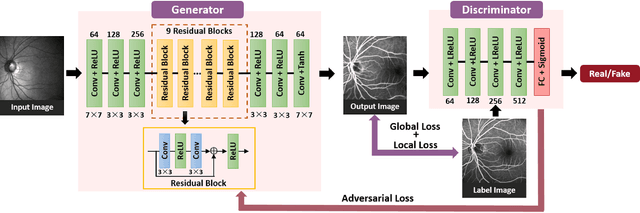
Fluorescein angiography can provide a map of retinal vascular structure and function, which is commonly used in ophthalmology diagnosis, however, this imaging modality may pose risks of harm to the patients. To help physicians reduce the potential risks of diagnosis, an image translation method is adopted. In this work, we proposed a conditional generative adversarial network(GAN) - based method to directly learn the mapping relationship between structure fundus images and fundus fluorescence angiography images. Moreover, local saliency maps, which define each pixel's importance, are used to define a novel saliency loss in the GAN cost function. This facilitates more accurate learning of small-vessel and fluorescein leakage features.