 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025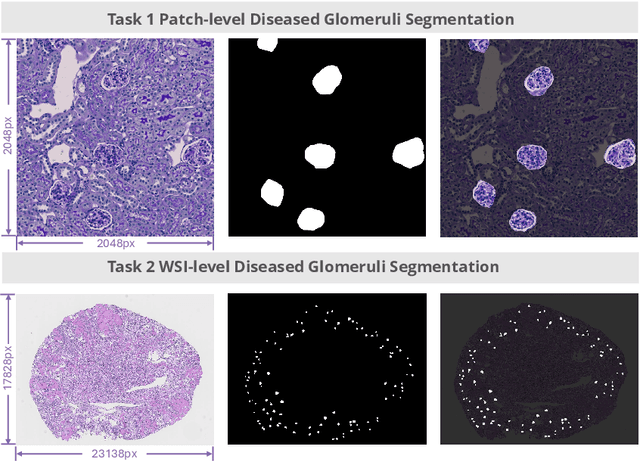

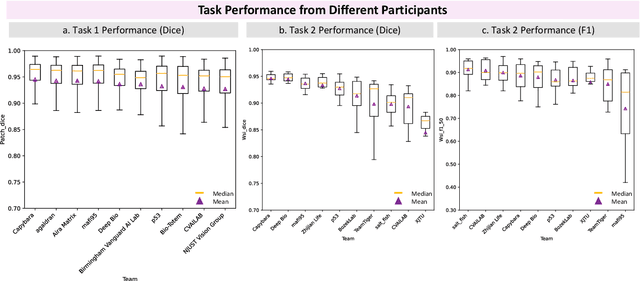

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
Post-Training Quantization for 3D Medical Image Segmentation: A Practical Study on Real Inference Engines
Jan 28, 2025Quantizing deep neural networks ,reducing the precision (bit-width) of their computations, can remarkably decrease memory usage and accelerate processing, making these models more suitable for large-scale medical imaging applications with limited computational resources. However, many existing methods studied "fake quantization", which simulates lower precision operations during inference, but does not actually reduce model size or improve real-world inference speed. Moreover, the potential of deploying real 3D low-bit quantization on modern GPUs is still unexplored. In this study, we introduce a real post-training quantization (PTQ) framework that successfully implements true 8-bit quantization on state-of-the-art (SOTA) 3D medical segmentation models, i.e., U-Net, SegResNet, SwinUNETR, nnU-Net, UNesT, TransUNet, ST-UNet,and VISTA3D. Our approach involves two main steps. First, we use TensorRT to perform fake quantization for both weights and activations with unlabeled calibration dataset. Second, we convert this fake quantization into real quantization via TensorRT engine on real GPUs, resulting in real-world reductions in model size and inference latency. Extensive experiments demonstrate that our framework effectively performs 8-bit quantization on GPUs without sacrificing model performance. This advancement enables the deployment of efficient deep learning models in medical imaging applications where computational resources are constrained. The code and models have been released, including U-Net, TransUNet pretrained on the BTCV dataset for abdominal (13-label) segmentation, UNesT pretrained on the Whole Brain Dataset for whole brain (133-label) segmentation, and nnU-Net, SegResNet, SwinUNETR and VISTA3D pretrained on TotalSegmentator V2 for full body (104-label) segmentation. https://github.com/hrlblab/PTQ.
ScaleMAI: Accelerating the Development of Trusted Datasets and AI Models
Jan 06, 2025



Building trusted datasets is critical for transparent and responsible Medical AI (MAI) research, but creating even small, high-quality datasets can take years of effort from multidisciplinary teams. This process often delays AI benefits, as human-centric data creation and AI-centric model development are treated as separate, sequential steps. To overcome this, we propose ScaleMAI, an agent of AI-integrated data curation and annotation, allowing data quality and AI performance to improve in a self-reinforcing cycle and reducing development time from years to months. We adopt pancreatic tumor detection as an example. First, ScaleMAI progressively creates a dataset of 25,362 CT scans, including per-voxel annotations for benign/malignant tumors and 24 anatomical structures. Second, through progressive human-in-the-loop iterations, ScaleMAI provides Flagship AI Model that can approach the proficiency of expert annotators (30-year experience) in detecting pancreatic tumors. Flagship Model significantly outperforms models developed from smaller, fixed-quality datasets, with substantial gains in tumor detection (+14%), segmentation (+5%), and classification (72%) on three prestigious benchmarks. In summary, ScaleMAI transforms the speed, scale, and reliability of medical dataset creation, paving the way for a variety of impactful, data-driven applications.
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
ETA-IK: Execution-Time-Aware Inverse Kinematics for Dual-Arm Systems
Nov 21, 2024This paper presents ETA-IK, a novel Execution-Time-Aware Inverse Kinematics method tailored for dual-arm robotic systems. The primary goal is to optimize motion execution time by leveraging the redundancy of both arms, specifically in tasks where only the relative pose of the robots is constrained, such as dual-arm scanning of unknown objects. Unlike traditional inverse kinematics methods that use surrogate metrics such as joint configuration distance, our method incorporates direct motion execution time and implicit collisions into the optimization process, thereby finding target joints that allow subsequent trajectory generation to get more efficient and collision-free motion. A neural network based execution time approximator is employed to predict time-efficient joint configurations while accounting for potential collisions. Through experimental evaluation on a system composed of a UR5 and a KUKA iiwa robot, we demonstrate significant reductions in execution time. The proposed method outperforms conventional approaches, showing improved motion efficiency without sacrificing positioning accuracy. These results highlight the potential of ETA-IK to improve the performance of dual-arm systems in applications, where efficiency and safety are paramount.
VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge
Nov 19, 2024



Generalist vision language models (VLMs) have made significant strides in computer vision, but they fall short in specialized fields like healthcare, where expert knowledge is essential. In traditional computer vision tasks, creative or approximate answers may be acceptable, but in healthcare, precision is paramount.Current large multimodal models like Gemini and GPT-4o are insufficient for medical tasks due to their reliance on memorized internet knowledge rather than the nuanced expertise required in healthcare. VLMs are usually trained in three stages: vision pre-training, vision-language pre-training, and instruction fine-tuning (IFT). IFT has been typically applied using a mixture of generic and healthcare data. In contrast, we propose that for medical VLMs, a fourth stage of specialized IFT is necessary, which focuses on medical data and includes information from domain expert models. Domain expert models developed for medical use are crucial because they are specifically trained for certain clinical tasks, e.g. to detect tumors and classify abnormalities through segmentation and classification, which learn fine-grained features of medical data$-$features that are often too intricate for a VLM to capture effectively especially in radiology. This paper introduces a new framework, VILA-M3, for medical VLMs that utilizes domain knowledge via expert models. Through our experiments, we show an improved state-of-the-art (SOTA) performance with an average improvement of ~9% over the prior SOTA model Med-Gemini and ~6% over models trained on the specific tasks. Our approach emphasizes the importance of domain expertise in creating precise, reliable VLMs for medical applications.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
MAISI: Medical AI for Synthetic Imaging
Sep 13, 2024



Medical imaging analysis faces challenges such as data scarcity, high annotation costs, and privacy concerns. This paper introduces the Medical AI for Synthetic Imaging (MAISI), an innovative approach using the diffusion model to generate synthetic 3D computed tomography (CT) images to address those challenges. MAISI leverages the foundation volume compression network and the latent diffusion model to produce high-resolution CT images (up to a landmark volume dimension of 512 x 512 x 768 ) with flexible volume dimensions and voxel spacing. By incorporating ControlNet, MAISI can process organ segmentation, including 127 anatomical structures, as additional conditions and enables the generation of accurately annotated synthetic images that can be used for various downstream tasks. Our experiment results show that MAISI's capabilities in generating realistic, anatomically accurate images for diverse regions and conditions reveal its promising potential to mitigate challenges using synthetic data.
Robust Real-time Segmentation of Bio-Morphological Features in Human Cherenkov Imaging during Radiotherapy via Deep Learning
Sep 09, 2024



Cherenkov imaging enables real-time visualization of megavoltage X-ray or electron beam delivery to the patient during Radiation Therapy (RT). Bio-morphological features, such as vasculature, seen in these images are patient-specific signatures that can be used for verification of positioning and motion management that are essential to precise RT treatment. However until now, no concerted analysis of this biological feature-based tracking was utilized because of the slow speed and accuracy of conventional image processing for feature segmentation. This study demonstrated the first deep learning framework for such an application, achieving video frame rate processing. To address the challenge of limited annotation of these features in Cherenkov images, a transfer learning strategy was applied. A fundus photography dataset including 20,529 patch retina images with ground-truth vessel annotation was used to pre-train a ResNet segmentation framework. Subsequently, a small Cherenkov dataset (1,483 images from 212 treatment fractions of 19 breast cancer patients) with known annotated vasculature masks was used to fine-tune the model for accurate segmentation prediction. This deep learning framework achieved consistent and rapid segmentation of Cherenkov-imaged bio-morphological features on another 19 patients, including subcutaneous veins, scars, and pigmented skin. Average segmentation by the model achieved Dice score of 0.85 and required less than 0.7 milliseconds processing time per instance. The model demonstrated outstanding consistency against input image variances and speed compared to conventional manual segmentation methods, laying the foundation for online segmentation in real-time monitoring in a prospective setting.
A Short Review and Evaluation of SAM2's Performance in 3D CT Image Segmentation
Aug 20, 2024



Since the release of Segment Anything 2 (SAM2), the medical imaging community has been actively evaluating its performance for 3D medical image segmentation. However, different studies have employed varying evaluation pipelines, resulting in conflicting outcomes that obscure a clear understanding of SAM2's capabilities and potential applications. We shortly review existing benchmarks and point out that the SAM2 paper clearly outlines a zero-shot evaluation pipeline, which simulates user clicks iteratively for up to eight iterations. We reproduced this interactive annotation simulation on 3D CT datasets and provided the results and code~\url{https://github.com/Project-MONAI/VISTA}. Our findings reveal that directly applying SAM2 on 3D medical imaging in a zero-shot manner is far from satisfactory. It is prone to generating false positives when foreground objects disappear, and annotating more slices cannot fully offset this tendency. For smaller single-connected objects like kidney and aorta, SAM2 performs reasonably well but for most organs it is still far behind state-of-the-art 3D annotation methods. More research and innovation are needed for 3D medical imaging community to use SAM2 correctly.