 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Non-Rigid Structure from Motion: A Manifold Viewpoint
Jun 15, 2020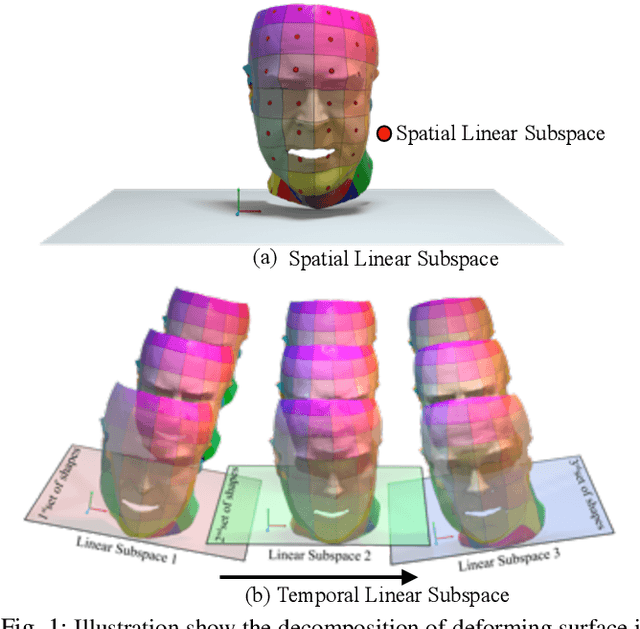
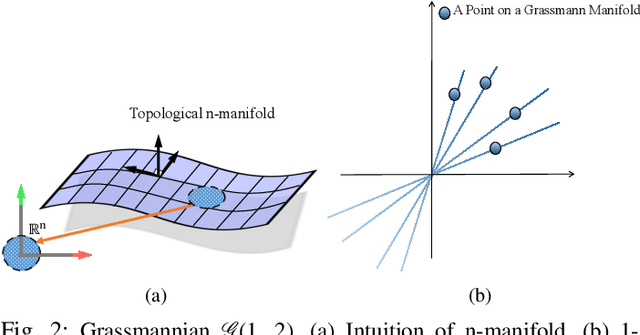
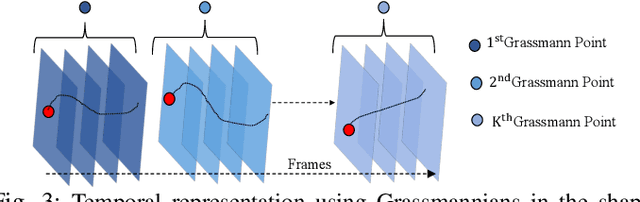
Non-Rigid Structure-from-Motion (NRSfM) problem aims to recover 3D geometry of a deforming object from its 2D feature correspondences across multiple frames. Classical approaches to this problem assume a small number of feature points and, ignore the local non-linearities of the shape deformation, and therefore, struggles to reliably model non-linear deformations. Furthermore, available dense NRSfM algorithms are often hurdled by scalability, computations, noisy measurements and, restricted to model just global deformation. In this paper, we propose algorithms that can overcome these limitations with the previous methods and, at the same time, can recover a reliable dense 3D structure of a non-rigid object with higher accuracy. Assuming that a deforming shape is composed of a union of local linear subspace and, span a global low-rank space over multiple frames enables us to efficiently model complex non-rigid deformations. To that end, each local linear subspace is represented using Grassmannians and, the global 3D shape across multiple frames is represented using a low-rank representation. We show that our approach significantly improves accuracy, scalability, and robustness against noise. Also, our representation naturally allows for simultaneous reconstruction and clustering framework which in general is observed to be more suitable for NRSfM problems. Our method currently achieves leading performance on the standard benchmark datasets.
Relative Pose Estimation for Stereo Rolling Shutter Cameras
Jun 14, 2020
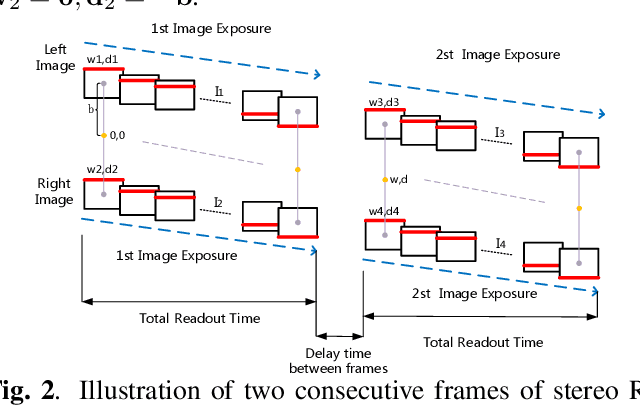
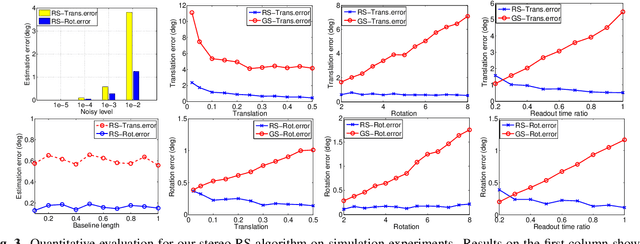

In this paper, we present a novel linear algorithm to estimate the 6 DoF relative pose from consecutive frames of stereo rolling shutter (RS) cameras. Our method is derived based on the assumption that stereo cameras undergo motion with constant velocity around the center of the baseline, which needs 9 pairs of correspondences on both left and right consecutive frames. The stereo RS images enable the recovery of depth maps from the semi-global matching (SGM) algorithm. With the estimated camera motion and depth map, we can correct the RS images to get the undistorted images without any scene structure assumption. Experiments on both simulated points and synthetic RS images demonstrate the effectiveness of our algorithm in relative pose estimation.
Channel Attention based Iterative Residual Learning for Depth Map Super-Resolution
Jun 02, 2020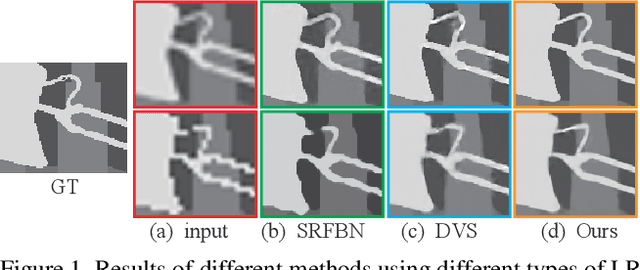
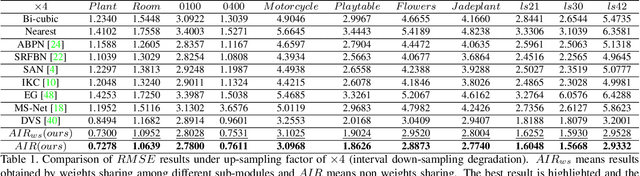
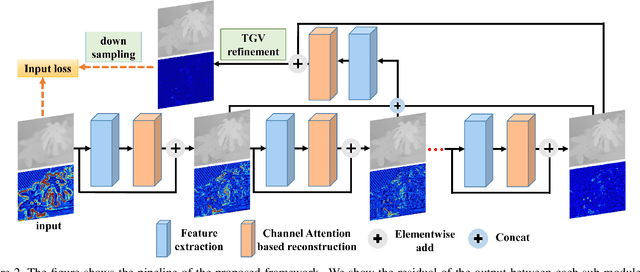
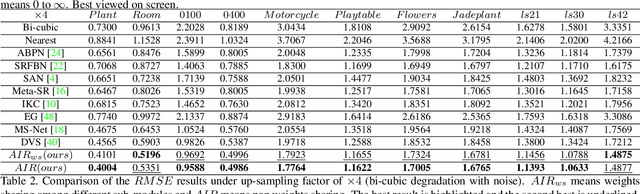
Despite the remarkable progresses made in deep-learning based depth map super-resolution (DSR), how to tackle real-world degradation in low-resolution (LR) depth maps remains a major challenge. Existing DSR model is generally trained and tested on synthetic dataset, which is very different from what would get from a real depth sensor. In this paper, we argue that DSR models trained under this setting are restrictive and not effective in dealing with real-world DSR tasks. We make two contributions in tackling real-world degradation of different depth sensors. First, we propose to classify the generation of LR depth maps into two types: non-linear downsampling with noise and interval downsampling, for which DSR models are learned correspondingly. Second, we propose a new framework for real-world DSR, which consists of four modules : 1) An iterative residual learning module with deep supervision to learn effective high-frequency components of depth maps in a coarse-to-fine manner; 2) A channel attention strategy to enhance channels with abundant high-frequency components; 3) A multi-stage fusion module to effectively re-exploit the results in the coarse-to-fine process; and 4) A depth refinement module to improve the depth map by TGV regularization and input loss. Extensive experiments on benchmarking datasets demonstrate the superiority of our method over current state-of-the-art DSR methods.
UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders
Apr 13, 2020
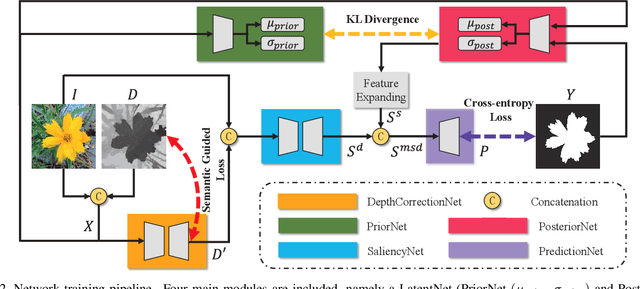
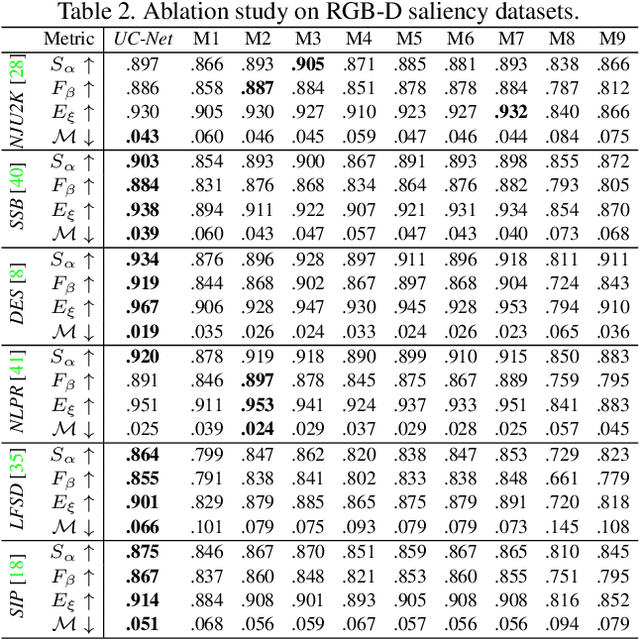
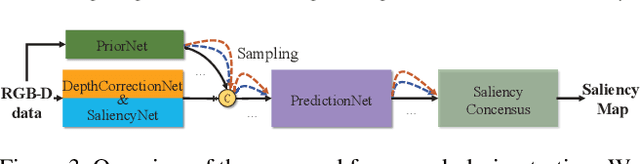
In this paper, we propose the first framework (UCNet) to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection methods treat the saliency detection task as a point estimation problem, and produce a single saliency map following a deterministic learning pipeline. Inspired by the saliency data labeling process, we propose probabilistic RGB-D saliency detection network via conditional variational autoencoders to model human annotation uncertainty and generate multiple saliency maps for each input image by sampling in the latent space. With the proposed saliency consensus process, we are able to generate an accurate saliency map based on these multiple predictions. Quantitative and qualitative evaluations on six challenging benchmark datasets against 18 competing algorithms demonstrate the effectiveness of our approach in learning the distribution of saliency maps, leading to a new state-of-the-art in RGB-D saliency detection.
Weakly-Supervised Salient Object Detection via Scribble Annotations
Mar 17, 2020
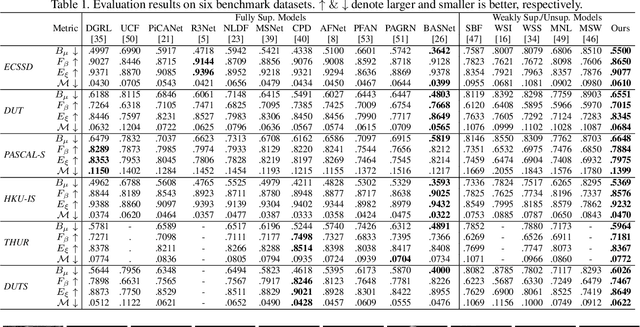
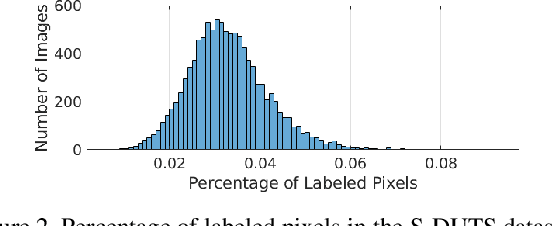
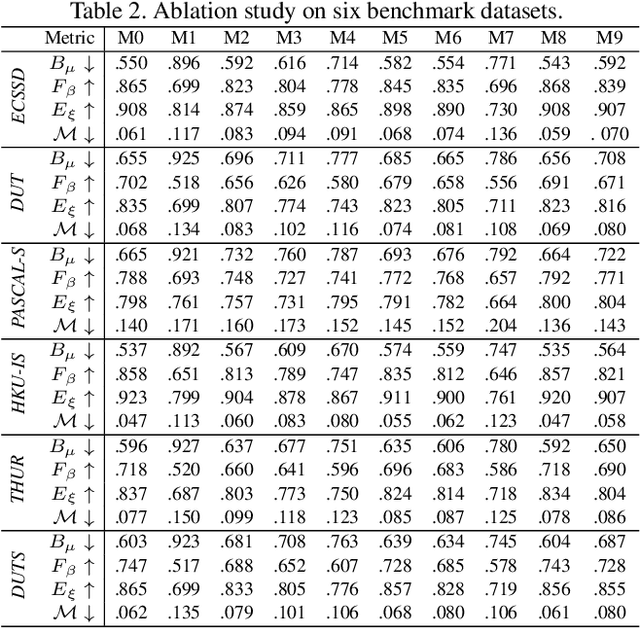
Compared with laborious pixel-wise dense labeling, it is much easier to label data by scribbles, which only costs 1$\sim$2 seconds to label one image. However, using scribble labels to learn salient object detection has not been explored. In this paper, we propose a weakly-supervised salient object detection model to learn saliency from such annotations. In doing so, we first relabel an existing large-scale salient object detection dataset with scribbles, namely S-DUTS dataset. Since object structure and detail information is not identified by scribbles, directly training with scribble labels will lead to saliency maps of poor boundary localization. To mitigate this problem, we propose an auxiliary edge detection task to localize object edges explicitly, and a gated structure-aware loss to place constraints on the scope of structure to be recovered. Moreover, we design a scribble boosting scheme to iteratively consolidate our scribble annotations, which are then employed as supervision to learn high-quality saliency maps. As existing saliency evaluation metrics neglect to measure structure alignment of the predictions, the saliency map ranking metric may not comply with human perception. We present a new metric, termed saliency structure measure, to measure the structure alignment of the predicted saliency maps, which is more consistent with human perception. Extensive experiments on six benchmark datasets demonstrate that our method not only outperforms existing weakly-supervised/unsupervised methods, but also is on par with several fully-supervised state-of-the-art models. Our code and data is publicly available at https://github.com/JingZhang617/Scribble_Saliency.
Superpixel Soup: Monocular Dense 3D Reconstruction of a Complex Dynamic Scene
Nov 19, 2019
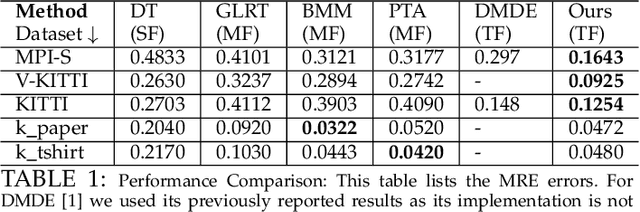
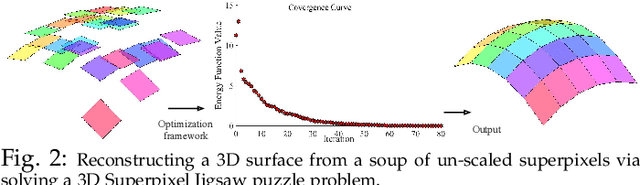
This work addresses the task of dense 3D reconstruction of a complex dynamic scene from images. The prevailing idea to solve this task is composed of a sequence of steps and is dependent on the success of several pipelines in its execution. To overcome such limitations with the existing algorithm, we propose a unified approach to solve this problem. We assume that a dynamic scene can be approximated by numerous piecewise planar surfaces, where each planar surface enjoys its own rigid motion, and the global change in the scene between two frames is as-rigid-as-possible (ARAP). Consequently, our model of a dynamic scene reduces to a soup of planar structures and rigid motion of these local planar structures. Using planar over-segmentation of the scene, we reduce this task to solving a "3D jigsaw puzzle" problem. Hence, the task boils down to correctly assemble each rigid piece to construct a 3D shape that complies with the geometry of the scene under the ARAP assumption. Further, we show that our approach provides an effective solution to the inherent scale-ambiguity in structure-from-motion under perspective projection. We provide extensive experimental results and evaluation on several benchmark datasets. Quantitative comparison with competing approaches shows state-of-the-art performance.
Joint Stereo Video Deblurring, Scene Flow Estimation and Moving Object Segmentation
Oct 06, 2019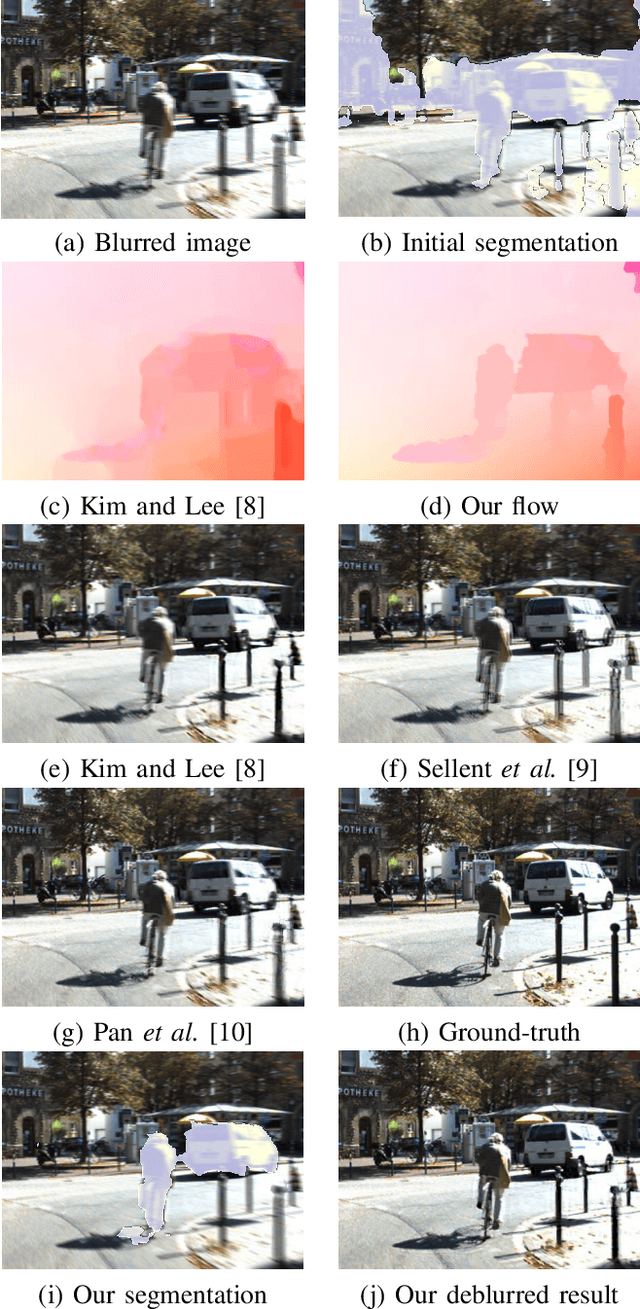
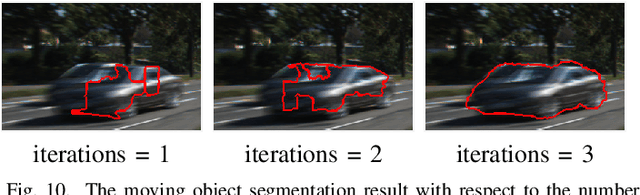


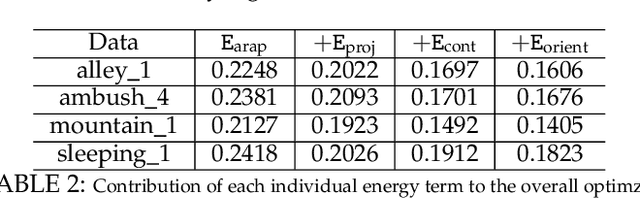
Stereo videos for the dynamic scenes often show unpleasant blurred effects due to the camera motion and the multiple moving objects with large depth variations. Given consecutive blurred stereo video frames, we aim to recover the latent clean images, estimate the 3D scene flow and segment the multiple moving objects. These three tasks have been previously addressed separately, which fail to exploit the internal connections among these tasks and cannot achieve optimality. In this paper, we propose to jointly solve these three tasks in a unified framework by exploiting their intrinsic connections. To this end, we represent the dynamic scenes with the piece-wise planar model, which exploits the local structure of the scene and expresses various dynamic scenes. Under our model, these three tasks are naturally connected and expressed as the parameter estimation of 3D scene structure and camera motion (structure and motion for the dynamic scenes). By exploiting the blur model constraint, the moving objects and the 3D scene structure, we reach an energy minimization formulation for joint deblurring, scene flow and segmentation. We evaluate our approach extensively on both synthetic datasets and publicly available real datasets with fast-moving objects, camera motion, uncontrolled lighting conditions and shadows. Experimental results demonstrate that our method can achieve significant improvement in stereo video deblurring, scene flow estimation and moving object segmentation, over state-of-the-art methods.
MVS^2: Deep Unsupervised Multi-view Stereo with Multi-View Symmetry
Aug 30, 2019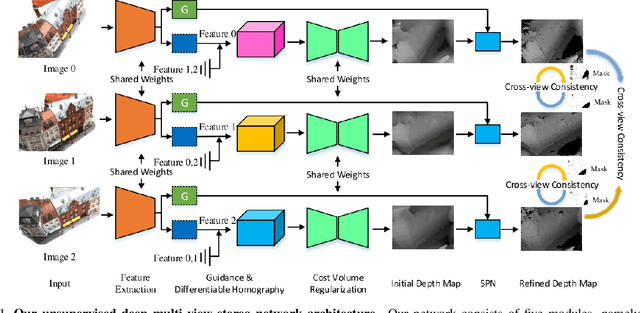
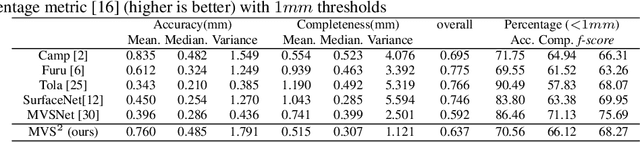
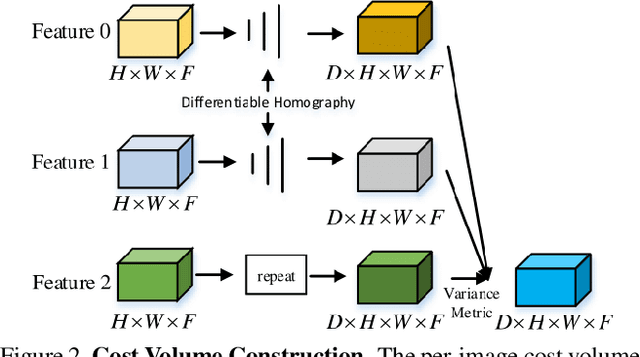

The success of existing deep-learning based multi-view stereo (MVS) approaches greatly depends on the availability of large-scale supervision in the form of dense depth maps. Such supervision, while not always possible, tends to hinder the generalization ability of the learned models in never-seen-before scenarios. In this paper, we propose the first unsupervised learning based MVS network, which learns the multi-view depth maps from the input multi-view images and does not need ground-truth 3D training data. Our network is symmetric in predicting depth maps for all views simultaneously, where we enforce cross-view consistency of multi-view depth maps during both training and testing stages. Thus, the learned multi-view depth maps naturally comply with the underlying 3D scene geometry. Besides, our network also learns the multi-view occlusion maps, which further improves the robustness of our network in handling real-world occlusions. Experimental results on multiple benchmarking datasets demonstrate the effectiveness of our network and the excellent generalization ability.
IoU Loss for 2D/3D Object Detection
Aug 11, 2019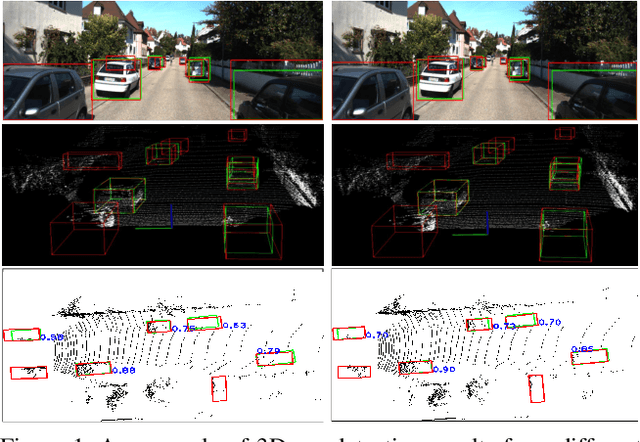

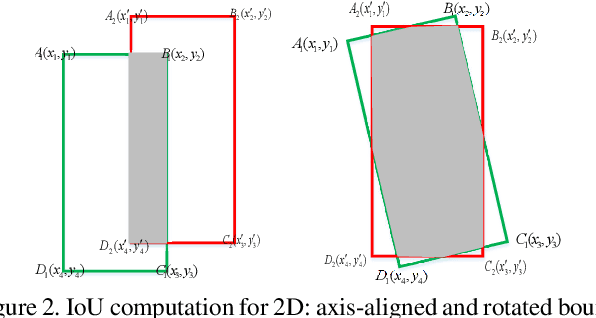
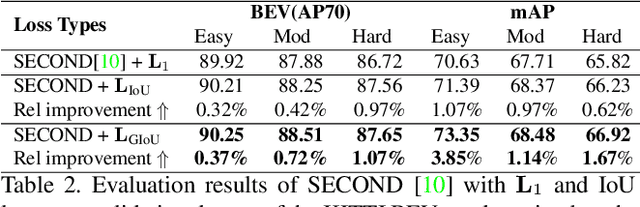
In 2D/3D object detection task, Intersection-over-Union (IoU) has been widely employed as an evaluation metric to evaluate the performance of different detectors in the testing stage. However, during the training stage, the common distance loss (\eg, $L_1$ or $L_2$) is often adopted as the loss function to minimize the discrepancy between the predicted and ground truth Bounding Box (Bbox). To eliminate the performance gap between training and testing, the IoU loss has been introduced for 2D object detection in \cite{yu2016unitbox} and \cite{rezatofighi2019generalized}. Unfortunately, all these approaches only work for axis-aligned 2D Bboxes, which cannot be applied for more general object detection task with rotated Bboxes. To resolve this issue, we investigate the IoU computation for two rotated Bboxes first and then implement a unified framework, IoU loss layer for both 2D and 3D object detection tasks. By integrating the implemented IoU loss into several state-of-the-art 3D object detectors, consistent improvements have been achieved for both bird-eye-view 2D detection and point cloud 3D detection on the public KITTI benchmark.
Multi-scale Cross-form Pyramid Network for Stereo Matching
Jun 04, 2019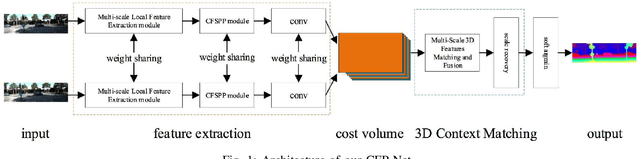
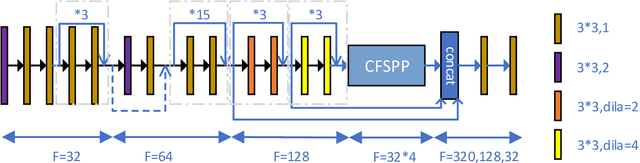
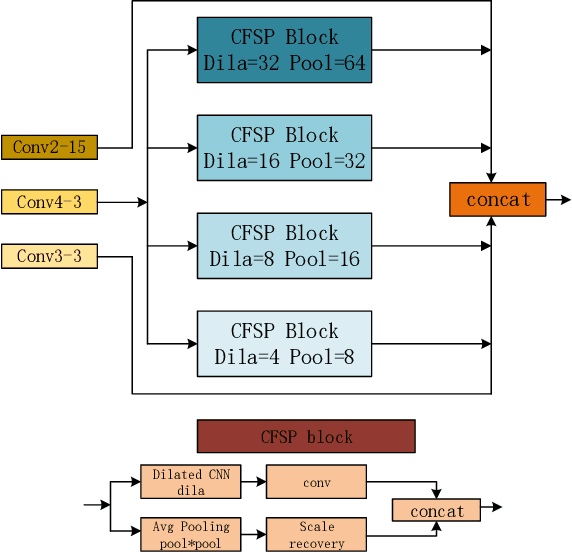
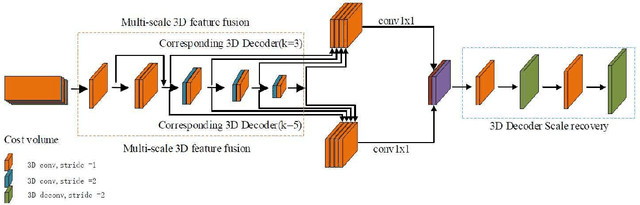
Stereo matching plays an indispensable part in autonomous driving, robotics and 3D scene reconstruction. We propose a novel deep learning architecture, which called CFP-Net, a Cross-Form Pyramid stereo matching network for regressing disparity from a rectified pair of stereo images. The network consists of three modules: Multi-Scale 2D local feature extraction module, Cross-form spatial pyramid module and Multi-Scale 3D Feature Matching and Fusion module. The Multi-Scale 2D local feature extraction module can extract enough multi-scale features. The Cross-form spatial pyramid module aggregates the context information in different scales and locations to form a cost volume. Moreover, it is proved to be more effective than SPP and ASPP in ill-posed regions. The Multi-Scale 3D feature matching and fusion module is proved to regularize the cost volume using two parallel 3D deconvolution structure with two different receptive fields. Our proposed method has been evaluated on the Scene Flow and KITTI datasets. It achieves state-of-the-art performance on the KITTI 2012 and 2015 benchmarks.