 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware 3D Salient Object Detection Network
Feb 23, 2025



Point cloud salient object detection has attracted the attention of researchers in recent years. Since existing works do not fully utilize the geometry context of 3D objects, blurry boundaries are generated when segmenting objects with complex backgrounds. In this paper, we propose a geometry-aware 3D salient object detection network that explicitly clusters points into superpoints to enhance the geometric boundaries of objects, thereby segmenting complete objects with clear boundaries. Specifically, we first propose a simple yet effective superpoint partition module to cluster points into superpoints. In order to improve the quality of superpoints, we present a point cloud class-agnostic loss to learn discriminative point features for clustering superpoints from the object. After obtaining superpoints, we then propose a geometry enhancement module that utilizes superpoint-point attention to aggregate geometric information into point features for predicting the salient map of the object with clear boundaries. Extensive experiments show that our method achieves new state-of-the-art performance on the PCSOD dataset.
Instance-Level Moving Object Segmentation from a Single Image with Events
Feb 18, 2025Moving object segmentation plays a crucial role in understanding dynamic scenes involving multiple moving objects, while the difficulties lie in taking into account both spatial texture structures and temporal motion cues. Existing methods based on video frames encounter difficulties in distinguishing whether pixel displacements of an object are caused by camera motion or object motion due to the complexities of accurate image-based motion modeling. Recent advances exploit the motion sensitivity of novel event cameras to counter conventional images' inadequate motion modeling capabilities, but instead lead to challenges in segmenting pixel-level object masks due to the lack of dense texture structures in events. To address these two limitations imposed by unimodal settings, we propose the first instance-level moving object segmentation framework that integrates complementary texture and motion cues. Our model incorporates implicit cross-modal masked attention augmentation, explicit contrastive feature learning, and flow-guided motion enhancement to exploit dense texture information from a single image and rich motion information from events, respectively. By leveraging the augmented texture and motion features, we separate mask segmentation from motion classification to handle varying numbers of independently moving objects. Through extensive evaluations on multiple datasets, as well as ablation experiments with different input settings and real-time efficiency analysis of the proposed framework, we believe that our first attempt to incorporate image and event data for practical deployment can provide new insights for future work in event-based motion related works. The source code with model training and pre-trained weights is released at https://npucvr.github.io/EvInsMOS
A Generative Victim Model for Segmentation
Dec 10, 2024We find that the well-trained victim models (VMs), against which the attacks are generated, serve as fundamental prerequisites for adversarial attacks, i.e. a segmentation VM is needed to generate attacks for segmentation. In this context, the victim model is assumed to be robust to achieve effective adversarial perturbation generation. Instead of focusing on improving the robustness of the task-specific victim models, we shift our attention to image generation. From an image generation perspective, we derive a novel VM for segmentation, aiming to generate adversarial perturbations for segmentation tasks without requiring models explicitly designed for image segmentation. Our approach to adversarial attack generation diverges from conventional white-box or black-box attacks, offering a fresh outlook on adversarial attack strategies. Experiments show that our attack method is able to generate effective adversarial attacks with good transferability.
3D Focusing-and-Matching Network for Multi-Instance Point Cloud Registration
Nov 12, 2024



Multi-instance point cloud registration aims to estimate the pose of all instances of a model point cloud in the whole scene. Existing methods all adopt the strategy of first obtaining the global correspondence and then clustering to obtain the pose of each instance. However, due to the cluttered and occluded objects in the scene, it is difficult to obtain an accurate correspondence between the model point cloud and all instances in the scene. To this end, we propose a simple yet powerful 3D focusing-and-matching network for multi-instance point cloud registration by learning the multiple pair-wise point cloud registration. Specifically, we first present a 3D multi-object focusing module to locate the center of each object and generate object proposals. By using self-attention and cross-attention to associate the model point cloud with structurally similar objects, we can locate potential matching instances by regressing object centers. Then, we propose a 3D dual masking instance matching module to estimate the pose between the model point cloud and each object proposal. It performs instance mask and overlap mask masks to accurately predict the pair-wise correspondence. Extensive experiments on two public benchmarks, Scan2CAD and ROBI, show that our method achieves a new state-of-the-art performance on the multi-instance point cloud registration task. Code is available at https://github.com/zlynpu/3DFMNet.
LoFLAT: Local Feature Matching using Focused Linear Attention Transformer
Oct 30, 2024Local feature matching is an essential technique in image matching and plays a critical role in a wide range of vision-based applications. However, existing Transformer-based detector-free local feature matching methods encounter challenges due to the quadratic computational complexity of attention mechanisms, especially at high resolutions. However, while existing Transformer-based detector-free local feature matching methods have reduced computational costs using linear attention mechanisms, they still struggle to capture detailed local interactions, which affects the accuracy and robustness of precise local correspondences. In order to enhance representations of attention mechanisms while preserving low computational complexity, we propose the LoFLAT, a novel Local Feature matching using Focused Linear Attention Transformer in this paper. Our LoFLAT consists of three main modules: the Feature Extraction Module, the Feature Transformer Module, and the Matching Module. Specifically, the Feature Extraction Module firstly uses ResNet and a Feature Pyramid Network to extract hierarchical features. The Feature Transformer Module further employs the Focused Linear Attention to refine attention distribution with a focused mapping function and to enhance feature diversity with a depth-wise convolution. Finally, the Matching Module predicts accurate and robust matches through a coarse-to-fine strategy. Extensive experimental evaluations demonstrate that the proposed LoFLAT outperforms the LoFTR method in terms of both efficiency and accuracy.
You Only Scan Once: Efficient Multi-dimension Sequential Modeling with LightNet
May 31, 2024



Linear attention mechanisms have gained prominence in causal language models due to their linear computational complexity and enhanced speed. However, the inherent decay mechanism in linear attention presents challenges when applied to multi-dimensional sequence modeling tasks, such as image processing and multi-modal learning. In these scenarios, the utilization of sequential scanning to establish a global receptive field necessitates multiple scans for multi-dimensional data, thereby leading to inefficiencies. This paper identifies the inefficiency caused by a multiplicative linear recurrence and proposes an efficient alternative additive linear recurrence to avoid the issue, as it can handle multi-dimensional data within a single scan. We further develop an efficient multi-dimensional sequential modeling framework called LightNet based on the new recurrence. Moreover, we present two new multi-dimensional linear relative positional encoding methods, MD-TPE and MD-LRPE to enhance the model's ability to discern positional information in multi-dimensional scenarios. Our empirical evaluations across various tasks, including image classification, image generation, bidirectional language modeling, and autoregressive language modeling, demonstrate the efficacy of LightNet, showcasing its potential as a versatile and efficient solution for multi-dimensional sequential modeling.
Non-rigid Structure-from-Motion: Temporally-smooth Procrustean Alignment and Spatially-variant Deformation Modeling
May 07, 2024



Even though Non-rigid Structure-from-Motion (NRSfM) has been extensively studied and great progress has been made, there are still key challenges that hinder their broad real-world applications: 1) the inherent motion/rotation ambiguity requires either explicit camera motion recovery with extra constraint or complex Procrustean Alignment; 2) existing low-rank modeling of the global shape can over-penalize drastic deformations in the 3D shape sequence. This paper proposes to resolve the above issues from a spatial-temporal modeling perspective. First, we propose a novel Temporally-smooth Procrustean Alignment module that estimates 3D deforming shapes and adjusts the camera motion by aligning the 3D shape sequence consecutively. Our new alignment module remedies the requirement of complex reference 3D shape during alignment, which is more conductive to non-isotropic deformation modeling. Second, we propose a spatial-weighted approach to enforce the low-rank constraint adaptively at different locations to accommodate drastic spatially-variant deformation reconstruction better. Our modeling outperform existing low-rank based methods, and extensive experiments across different datasets validate the effectiveness of our method.
TAVGBench: Benchmarking Text to Audible-Video Generation
Apr 22, 2024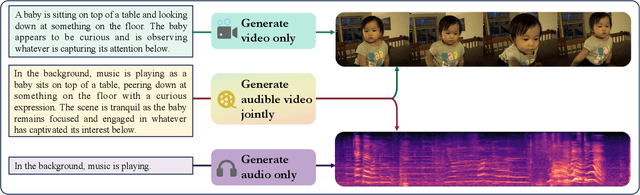

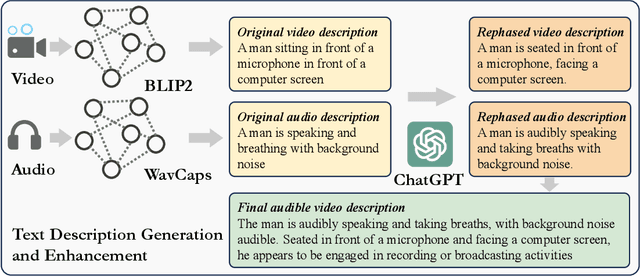

The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Apr 14, 2024



In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
LRRU: Long-short Range Recurrent Updating Networks for Depth Completion
Oct 13, 2023Existing deep learning-based depth completion methods generally employ massive stacked layers to predict the dense depth map from sparse input data. Although such approaches greatly advance this task, their accompanied huge computational complexity hinders their practical applications. To accomplish depth completion more efficiently, we propose a novel lightweight deep network framework, the Long-short Range Recurrent Updating (LRRU) network. Without learning complex feature representations, LRRU first roughly fills the sparse input to obtain an initial dense depth map, and then iteratively updates it through learned spatially-variant kernels. Our iterative update process is content-adaptive and highly flexible, where the kernel weights are learned by jointly considering the guidance RGB images and the depth map to be updated, and large-to-small kernel scopes are dynamically adjusted to capture long-to-short range dependencies. Our initial depth map has coarse but complete scene depth information, which helps relieve the burden of directly regressing the dense depth from sparse ones, while our proposed method can effectively refine it to an accurate depth map with less learnable parameters and inference time. Experimental results demonstrate that our proposed LRRU variants achieve state-of-the-art performance across different parameter regimes. In particular, the LRRU-Base model outperforms competing approaches on the NYUv2 dataset, and ranks 1st on the KITTI depth completion benchmark at the time of submission. Project page: https://npucvr.github.io/LRRU/.