 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiAuto-GeoX: Efficient Grounded Driving Transformer
Jun 04, 2026Dense 3D reconstruction has demonstrated immense potential for spatial understanding, yet its viability as a real-time, onboard representation for autonomous driving remains an open challenge. Existing large-scale visual geometry models typically require substantial computational resources and lack the long-range geometric fidelity, surround-view consistency, and real-time efficiency demanded by dynamic driving environments. To bridge this gap, we present \textbf{LiAuto-GeoX}, an efficient grounded driving transformer designed for deployable, ego-centric 3D scene understanding. Our approach begins by learning a high-capacity driving geometry model from large-scale surround-view data, utilizing sparse LiDAR priors to provide robust geometric grounding in distant, ambiguous, or structure-sparse regions. We then instantiate this capability into a highly compact 155M-parameter onboard model through a novel geometry-preserving distillation framework. This framework employs mask-guided depth-aware distillation to retain fine-grained metric structures by emphasizing geometrically informative regions, and relative-pose relational distillation to enforce cross-view spatial consistency through pose-induced geometric relations. Extensive evaluations reveal that \textbf{LiAuto-GeoX} runs at 220 FPS on KITTI while maintaining high-fidelity dense reconstruction, enabling real-time deployment. The learned geometry transfers seamlessly to downstream autonomy tasks, achieving 90.6 PDMS in trajectory prediction, 24.63 mIoU in occupancy prediction, and 47.67 IoU in future-frame prediction. These all demonstrate that efficient dense 3D reconstruction can transcend its traditional role as a perception target to serve as a scalable, foundational geometric representation for next-generation autonomous driving.
Sketchy Bounding-box Supervision for 3D Instance Segmentation
May 22, 2025Bounding box supervision has gained considerable attention in weakly supervised 3D instance segmentation. While this approach alleviates the need for extensive point-level annotations, obtaining accurate bounding boxes in practical applications remains challenging. To this end, we explore the inaccurate bounding box, named sketchy bounding box, which is imitated through perturbing ground truth bounding box by adding scaling, translation, and rotation. In this paper, we propose Sketchy-3DIS, a novel weakly 3D instance segmentation framework, which jointly learns pseudo labeler and segmentator to improve the performance under the sketchy bounding-box supervisions. Specifically, we first propose an adaptive box-to-point pseudo labeler that adaptively learns to assign points located in the overlapped parts between two sketchy bounding boxes to the correct instance, resulting in compact and pure pseudo instance labels. Then, we present a coarse-to-fine instance segmentator that first predicts coarse instances from the entire point cloud and then learns fine instances based on the region of coarse instances. Finally, by using the pseudo instance labels to supervise the instance segmentator, we can gradually generate high-quality instances through joint training. Extensive experiments show that our method achieves state-of-the-art performance on both the ScanNetV2 and S3DIS benchmarks, and even outperforms several fully supervised methods using sketchy bounding boxes. Code is available at https://github.com/dengq7/Sketchy-3DIS.
AuxDet: Auxiliary Metadata Matters for Omni-Domain Infrared Small Target Detection
May 21, 2025



Omni-domain infrared small target detection (IRSTD) poses formidable challenges, as a single model must seamlessly adapt to diverse imaging systems, varying resolutions, and multiple spectral bands simultaneously. Current approaches predominantly rely on visual-only modeling paradigms that not only struggle with complex background interference and inherently scarce target features, but also exhibit limited generalization capabilities across complex omni-scene environments where significant domain shifts and appearance variations occur. In this work, we reveal a critical oversight in existing paradigms: the neglect of readily available auxiliary metadata describing imaging parameters and acquisition conditions, such as spectral bands, sensor platforms, resolution, and observation perspectives. To address this limitation, we propose the Auxiliary Metadata Driven Infrared Small Target Detector (AuxDet), a novel multi-modal framework that fundamentally reimagines the IRSTD paradigm by incorporating textual metadata for scene-aware optimization. Through a high-dimensional fusion module based on multi-layer perceptrons (MLPs), AuxDet dynamically integrates metadata semantics with visual features, guiding adaptive representation learning for each individual sample. Additionally, we design a lightweight prior-initialized enhancement module using 1D convolutional blocks to further refine fused features and recover fine-grained target cues. Extensive experiments on the challenging WideIRSTD-Full benchmark demonstrate that AuxDet consistently outperforms state-of-the-art methods, validating the critical role of auxiliary information in improving robustness and accuracy in omni-domain IRSTD tasks. Code is available at https://github.com/GrokCV/AuxDet.
Learning Class Prototypes for Unified Sparse Supervised 3D Object Detection
Mar 27, 2025



Both indoor and outdoor scene perceptions are essential for embodied intelligence. However, current sparse supervised 3D object detection methods focus solely on outdoor scenes without considering indoor settings. To this end, we propose a unified sparse supervised 3D object detection method for both indoor and outdoor scenes through learning class prototypes to effectively utilize unlabeled objects. Specifically, we first propose a prototype-based object mining module that converts the unlabeled object mining into a matching problem between class prototypes and unlabeled features. By using optimal transport matching results, we assign prototype labels to high-confidence features, thereby achieving the mining of unlabeled objects. We then present a multi-label cooperative refinement module to effectively recover missed detections through pseudo label quality control and prototype label cooperation. Experiments show that our method achieves state-of-the-art performance under the one object per scene sparse supervised setting across indoor and outdoor datasets. With only one labeled object per scene, our method achieves about 78%, 90%, and 96% performance compared to the fully supervised detector on ScanNet V2, SUN RGB-D, and KITTI, respectively, highlighting the scalability of our method. Code is available at https://github.com/zyrant/CPDet3D.
Geometry-Aware 3D Salient Object Detection Network
Feb 23, 2025



Point cloud salient object detection has attracted the attention of researchers in recent years. Since existing works do not fully utilize the geometry context of 3D objects, blurry boundaries are generated when segmenting objects with complex backgrounds. In this paper, we propose a geometry-aware 3D salient object detection network that explicitly clusters points into superpoints to enhance the geometric boundaries of objects, thereby segmenting complete objects with clear boundaries. Specifically, we first propose a simple yet effective superpoint partition module to cluster points into superpoints. In order to improve the quality of superpoints, we present a point cloud class-agnostic loss to learn discriminative point features for clustering superpoints from the object. After obtaining superpoints, we then propose a geometry enhancement module that utilizes superpoint-point attention to aggregate geometric information into point features for predicting the salient map of the object with clear boundaries. Extensive experiments show that our method achieves new state-of-the-art performance on the PCSOD dataset.
Instance-Level Moving Object Segmentation from a Single Image with Events
Feb 18, 2025Moving object segmentation plays a crucial role in understanding dynamic scenes involving multiple moving objects, while the difficulties lie in taking into account both spatial texture structures and temporal motion cues. Existing methods based on video frames encounter difficulties in distinguishing whether pixel displacements of an object are caused by camera motion or object motion due to the complexities of accurate image-based motion modeling. Recent advances exploit the motion sensitivity of novel event cameras to counter conventional images' inadequate motion modeling capabilities, but instead lead to challenges in segmenting pixel-level object masks due to the lack of dense texture structures in events. To address these two limitations imposed by unimodal settings, we propose the first instance-level moving object segmentation framework that integrates complementary texture and motion cues. Our model incorporates implicit cross-modal masked attention augmentation, explicit contrastive feature learning, and flow-guided motion enhancement to exploit dense texture information from a single image and rich motion information from events, respectively. By leveraging the augmented texture and motion features, we separate mask segmentation from motion classification to handle varying numbers of independently moving objects. Through extensive evaluations on multiple datasets, as well as ablation experiments with different input settings and real-time efficiency analysis of the proposed framework, we believe that our first attempt to incorporate image and event data for practical deployment can provide new insights for future work in event-based motion related works. The source code with model training and pre-trained weights is released at https://npucvr.github.io/EvInsMOS
3D Focusing-and-Matching Network for Multi-Instance Point Cloud Registration
Nov 12, 2024



Multi-instance point cloud registration aims to estimate the pose of all instances of a model point cloud in the whole scene. Existing methods all adopt the strategy of first obtaining the global correspondence and then clustering to obtain the pose of each instance. However, due to the cluttered and occluded objects in the scene, it is difficult to obtain an accurate correspondence between the model point cloud and all instances in the scene. To this end, we propose a simple yet powerful 3D focusing-and-matching network for multi-instance point cloud registration by learning the multiple pair-wise point cloud registration. Specifically, we first present a 3D multi-object focusing module to locate the center of each object and generate object proposals. By using self-attention and cross-attention to associate the model point cloud with structurally similar objects, we can locate potential matching instances by regressing object centers. Then, we propose a 3D dual masking instance matching module to estimate the pose between the model point cloud and each object proposal. It performs instance mask and overlap mask masks to accurately predict the pair-wise correspondence. Extensive experiments on two public benchmarks, Scan2CAD and ROBI, show that our method achieves a new state-of-the-art performance on the multi-instance point cloud registration task. Code is available at https://github.com/zlynpu/3DFMNet.
Deep Height Decoupling for Precise Vision-based 3D Occupancy Prediction
Sep 12, 2024



The task of vision-based 3D occupancy prediction aims to reconstruct 3D geometry and estimate its semantic classes from 2D color images, where the 2D-to-3D view transformation is an indispensable step. Most previous methods conduct forward projection, such as BEVPooling and VoxelPooling, both of which map the 2D image features into 3D grids. However, the current grid representing features within a certain height range usually introduces many confusing features that belong to other height ranges. To address this challenge, we present Deep Height Decoupling (DHD), a novel framework that incorporates explicit height prior to filter out the confusing features. Specifically, DHD first predicts height maps via explicit supervision. Based on the height distribution statistics, DHD designs Mask Guided Height Sampling (MGHS) to adaptively decoupled the height map into multiple binary masks. MGHS projects the 2D image features into multiple subspaces, where each grid contains features within reasonable height ranges. Finally, a Synergistic Feature Aggregation (SFA) module is deployed to enhance the feature representation through channel and spatial affinities, enabling further occupancy refinement. On the popular Occ3D-nuScenes benchmark, our method achieves state-of-the-art performance even with minimal input frames. Code is available at https://github.com/yanzq95/DHD.
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Apr 14, 2024



In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
SPGroup3D: Superpoint Grouping Network for Indoor 3D Object Detection
Dec 21, 2023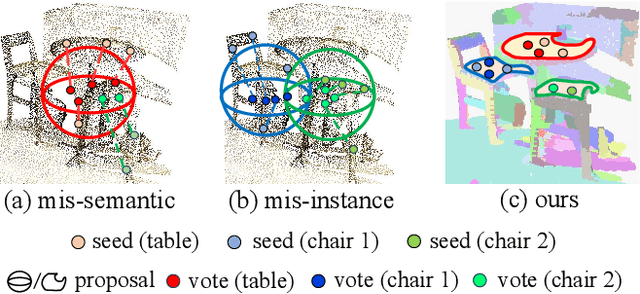
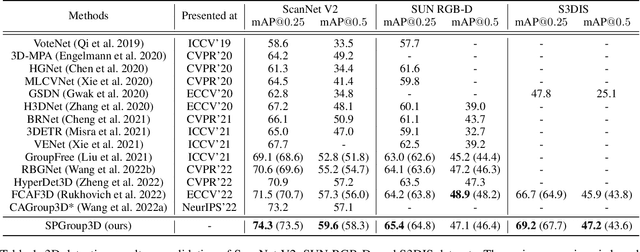
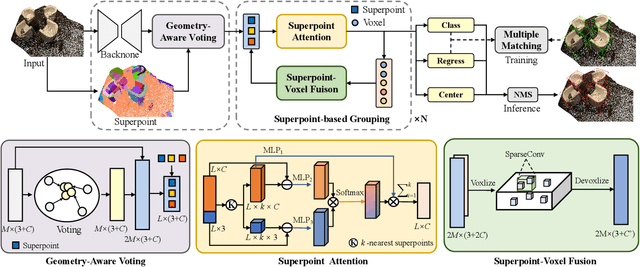
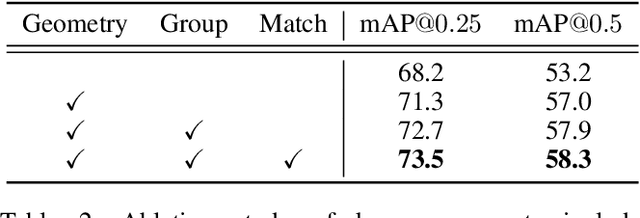
Current 3D object detection methods for indoor scenes mainly follow the voting-and-grouping strategy to generate proposals. However, most methods utilize instance-agnostic groupings, such as ball query, leading to inconsistent semantic information and inaccurate regression of the proposals. To this end, we propose a novel superpoint grouping network for indoor anchor-free one-stage 3D object detection. Specifically, we first adopt an unsupervised manner to partition raw point clouds into superpoints, areas with semantic consistency and spatial similarity. Then, we design a geometry-aware voting module that adapts to the centerness in anchor-free detection by constraining the spatial relationship between superpoints and object centers. Next, we present a superpoint-based grouping module to explore the consistent representation within proposals. This module includes a superpoint attention layer to learn feature interaction between neighboring superpoints, and a superpoint-voxel fusion layer to propagate the superpoint-level information to the voxel level. Finally, we employ effective multiple matching to capitalize on the dynamic receptive fields of proposals based on superpoints during the training. Experimental results demonstrate our method achieves state-of-the-art performance on ScanNet V2, SUN RGB-D, and S3DIS datasets in the indoor one-stage 3D object detection. Source code is available at https://github.com/zyrant/SPGroup3D.