 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploy-Master: Automating the Deployment of 50,000+ Agent-Ready Scientific Tools in One Day
Jan 07, 2026Open-source scientific software is abundant, yet most tools remain difficult to compile, configure, and reuse, sustaining a small-workshop mode of scientific computing. This deployment bottleneck limits reproducibility, large-scale evaluation, and the practical integration of scientific tools into modern AI-for-Science (AI4S) and agentic workflows. We present Deploy-Master, a one-stop agentic workflow for large-scale tool discovery, build specification inference, execution-based validation, and publication. Guided by a taxonomy spanning 90+ scientific and engineering domains, our discovery stage starts from a recall-oriented pool of over 500,000 public repositories and progressively filters it to 52,550 executable tool candidates under license- and quality-aware criteria. Deploy-Master transforms heterogeneous open-source repositories into runnable, containerized capabilities grounded in execution rather than documentation claims. In a single day, we performed 52,550 build attempts and constructed reproducible runtime environments for 50,112 scientific tools. Each successful tool is validated by a minimal executable command and registered in SciencePedia for search and reuse, enabling direct human use and optional agent-based invocation. Beyond delivering runnable tools, we report a deployment trace at the scale of 50,000 tools, characterizing throughput, cost profiles, failure surfaces, and specification uncertainty that become visible only at scale. These results explain why scientific software remains difficult to operationalize and motivate shared, observable execution substrates as a foundation for scalable AI4S and agentic science.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025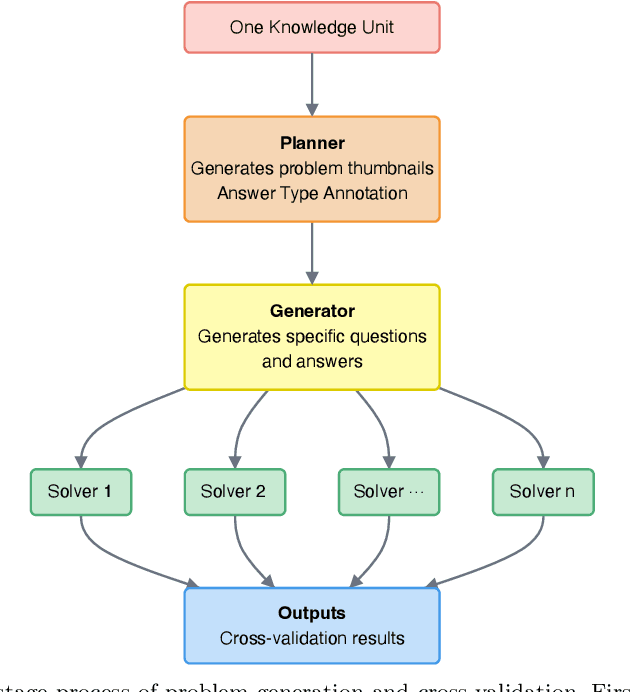
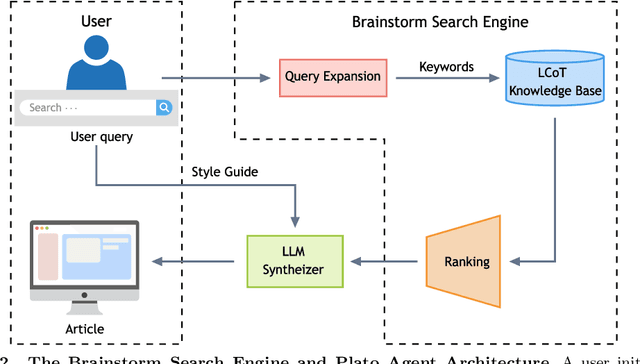
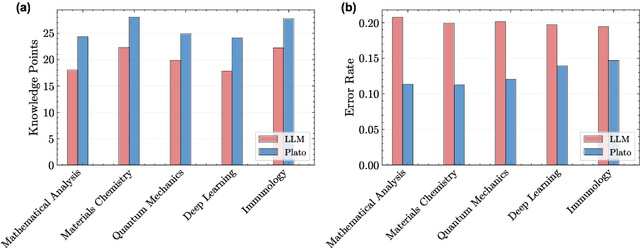
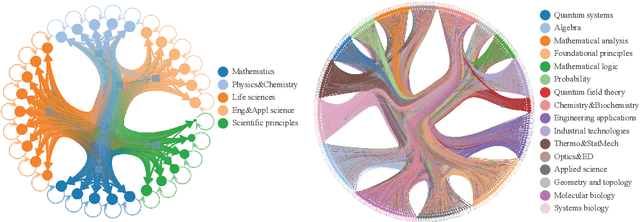
Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
UrbanCraft: Urban View Extrapolation via Hierarchical Sem-Geometric Priors
May 29, 2025



Existing neural rendering-based urban scene reconstruction methods mainly focus on the Interpolated View Synthesis (IVS) setting that synthesizes from views close to training camera trajectory. However, IVS can not guarantee the on-par performance of the novel view outside the training camera distribution (\textit{e.g.}, looking left, right, or downwards), which limits the generalizability of the urban reconstruction application. Previous methods have optimized it via image diffusion, but they fail to handle text-ambiguous or large unseen view angles due to coarse-grained control of text-only diffusion. In this paper, we design UrbanCraft, which surmounts the Extrapolated View Synthesis (EVS) problem using hierarchical sem-geometric representations serving as additional priors. Specifically, we leverage the partially observable scene to reconstruct coarse semantic and geometric primitives, establishing a coarse scene-level prior through an occupancy grid as the base representation. Additionally, we incorporate fine instance-level priors from 3D bounding boxes to enhance object-level details and spatial relationships. Building on this, we propose the \textbf{H}ierarchical \textbf{S}emantic-Geometric-\textbf{G}uided Variational Score Distillation (HSG-VSD), which integrates semantic and geometric constraints from pretrained UrbanCraft2D into the score distillation sampling process, forcing the distribution to be consistent with the observable scene. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS problem.
Geolocation with Real Human Gameplay Data: A Large-Scale Dataset and Human-Like Reasoning Framework
Feb 19, 2025



Geolocation, the task of identifying an image's location, requires complex reasoning and is crucial for navigation, monitoring, and cultural preservation. However, current methods often produce coarse, imprecise, and non-interpretable localization. A major challenge lies in the quality and scale of existing geolocation datasets. These datasets are typically small-scale and automatically constructed, leading to noisy data and inconsistent task difficulty, with images that either reveal answers too easily or lack sufficient clues for reliable inference. To address these challenges, we introduce a comprehensive geolocation framework with three key components: GeoComp, a large-scale dataset; GeoCoT, a novel reasoning method; and GeoEval, an evaluation metric, collectively designed to address critical challenges and drive advancements in geolocation research. At the core of this framework is GeoComp (Geolocation Competition Dataset), a large-scale dataset collected from a geolocation game platform involving 740K users over two years. It comprises 25 million entries of metadata and 3 million geo-tagged locations spanning much of the globe, with each location annotated thousands to tens of thousands of times by human users. The dataset offers diverse difficulty levels for detailed analysis and highlights key gaps in current models. Building on this dataset, we propose Geographical Chain-of-Thought (GeoCoT), a novel multi-step reasoning framework designed to enhance the reasoning capabilities of Large Vision Models (LVMs) in geolocation tasks. GeoCoT improves performance by integrating contextual and spatial cues through a multi-step process that mimics human geolocation reasoning. Finally, using the GeoEval metric, we demonstrate that GeoCoT significantly boosts geolocation accuracy by up to 25% while enhancing interpretability.
Range and Bird's Eye View Fused Cross-Modal Visual Place Recognition
Feb 17, 2025



Image-to-point cloud cross-modal Visual Place Recognition (VPR) is a challenging task where the query is an RGB image, and the database samples are LiDAR point clouds. Compared to single-modal VPR, this approach benefits from the widespread availability of RGB cameras and the robustness of point clouds in providing accurate spatial geometry and distance information. However, current methods rely on intermediate modalities that capture either the vertical or horizontal field of view, limiting their ability to fully exploit the complementary information from both sensors. In this work, we propose an innovative initial retrieval + re-rank method that effectively combines information from range (or RGB) images and Bird's Eye View (BEV) images. Our approach relies solely on a computationally efficient global descriptor similarity search process to achieve re-ranking. Additionally, we introduce a novel similarity label supervision technique to maximize the utility of limited training data. Specifically, we employ points average distance to approximate appearance similarity and incorporate an adaptive margin, based on similarity differences, into the vanilla triplet loss. Experimental results on the KITTI dataset demonstrate that our method significantly outperforms state-of-the-art approaches.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
GSGTrack: Gaussian Splatting-Guided Object Pose Tracking from RGB Videos
Dec 03, 2024



Tracking the 6DoF pose of unknown objects in monocular RGB video sequences is crucial for robotic manipulation. However, existing approaches typically rely on accurate depth information, which is non-trivial to obtain in real-world scenarios. Although depth estimation algorithms can be employed, geometric inaccuracy can lead to failures in RGBD-based pose tracking methods. To address this challenge, we introduce GSGTrack, a novel RGB-based pose tracking framework that jointly optimizes geometry and pose. Specifically, we adopt 3D Gaussian Splatting to create an optimizable 3D representation, which is learned simultaneously with a graph-based geometry optimization to capture the object's appearance features and refine its geometry. However, the joint optimization process is susceptible to perturbations from noisy pose and geometry data. Thus, we propose an object silhouette loss to address the issue of pixel-wise loss being overly sensitive to pose noise during tracking. To mitigate the geometric ambiguities caused by inaccurate depth information, we propose a geometry-consistent image pair selection strategy, which filters out low-confidence pairs and ensures robust geometric optimization. Extensive experiments on the OnePose and HO3D datasets demonstrate the effectiveness of GSGTrack in both 6DoF pose tracking and object reconstruction.
Empirical curvelet based Fully Convolutional Network for supervised texture image segmentation
Oct 28, 2024



In this paper, we propose a new approach to perform supervised texture classification/segmentation. The proposed idea is to feed a Fully Convolutional Network with specific texture descriptors. These texture features are extracted from images by using an empirical curvelet transform. We propose a method to build a unique empirical curvelet filter bank adapted to a given dictionary of textures. We then show that the output of these filters can be used to build efficient texture descriptors utilized to finally feed deep learning networks. Our approach is finally evaluated on several datasets and compare the results to various state-of-the-art algorithms and show that the proposed method dramatically outperform all existing ones.
Review of wavelet-based unsupervised texture segmentation, advantage of adaptive wavelets
Oct 24, 2024Wavelet-based segmentation approaches are widely used for texture segmentation purposes because of their ability to characterize different textures. In this paper, we assess the influence of the chosen wavelet and propose to use the recently introduced empirical wavelets. We show that the adaptability of the empirical wavelet permits to reach better results than classic wavelets. In order to focus only on the textural information, we also propose to perform a cartoon + texture decomposition step before applying the segmentation algorithm. The proposed method is tested on six classic benchmarks, based on several popular texture images.