 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPSolver: Neural Poisson Solver with Iterative Physics Supervision
May 25, 2026Efficiently solving Poisson equations on complex, irregular domains remains a fundamental challenge in scientific computing, as classical iterative solvers often suffer from prohibitive runtime due to ill-conditioned systems. While neural operators offer a fast alternative, they typically rely on large-scale labeled datasets or struggle with unstable training dynamics when using physics-informed residual losses. We propose \textsc{NPSolver}, a neural Poisson solver trained without solution labels via iterative physics supervision. Instead of relying on fully converged numerical solutions or raw PDE residuals, \textsc{NPSolver} utilizes a small number of preconditioned conjugate gradient (PCG) steps to refine its own predictions, providing a more stable and well-scaled training signal. Theoretical analysis confirms that this iterative supervision serves as a well-conditioned error proxy and that a stop-gradient design is essential for optimization stability. To better capture boundary-driven features under mixed boundary conditions, we further introduce the Boundary-Aware Transolver (\textsc{BA-Transolver}) architecture that explicitly separates interior and boundary tokenization. Extensive evaluations on 2D and 3D irregular geometries demonstrate that \textsc{NPSolver} outperforms both physics-informed and data-driven baselines. Furthermore, a downstream thermal control task highlights the model's capability for conducting efficient and reliable gradient-based boundary control. We will release our codes and data at https://github.com/intell-sci-comput/NPSolver.
A unified foundational framework for knowledge injection and evaluation of Large Language Models in Combustion Science
Feb 27, 2026To advance foundation Large Language Models (LLMs) for combustion science, this study presents the first end-to-end framework for developing domain-specialized models for the combustion community. The framework comprises an AI-ready multimodal knowledge base at the 3.5 billion-token scale, extracted from over 200,000 peer-reviewed articles, 8,000 theses and dissertations, and approximately 400,000 lines of combustion CFD code; a rigorous and largely automated evaluation benchmark (CombustionQA, 436 questions across eight subfields); and a three-stage knowledge-injection pathway that progresses from lightweight retrieval-augmented generation (RAG) to knowledge-graph-enhanced retrieval and continued pretraining. We first quantitatively validate Stage 1 (naive RAG) and find a hard ceiling: standard RAG accuracy peaks at 60%, far surpassing zero-shot performance (23%) yet well below the theoretical upper bound (87%). We further demonstrate that this stage's performance is severely constrained by context contamination. Consequently, building a domain foundation model requires structured knowledge graphs and continued pretraining (Stages 2 and 3).
Towards LLM-enabled autonomous combustion research: A literature-aware agent for self-corrective modeling workflows
Jan 04, 2026The rapid evolution of large language models (LLMs) is transforming artificial intelligence into autonomous research partners, yet a critical gap persists in complex scientific domains such as combustion modeling. Here, practical AI assistance requires the seamless integration of domain literature knowledge with robust execution capabilities for expertise-intensive tools such as computational fluid dynamics (CFD) codes. To bridge this gap, we introduce FlamePilot, an LLM agent designed to empower combustion modeling research through automated and self-corrective CFD workflows. FlamePilot differentiates itself through an architecture that leverages atomic tools to ensure the robust setup and execution of complex simulations in both OpenFOAM and extended frameworks such as DeepFlame. The system is also capable of learning from scientific articles, extracting key information to guide the simulation from initial setup to optimized results. Validation on a public benchmark shows FlamePilot achieved a perfect 1.0 executability score and a 0.438 success rate, surpassing the prior best reported agent scores of 0.625 and 0.250, respectively. Furthermore, a detailed case study on Moderate or Intense Low-oxygen Dilution (MILD) combustion simulation demonstrates its efficacy as a collaborative research copilot, where FlamePilot autonomously translated a research paper into a configured simulation, conducted the simulation, post-processed the results, proposed evidence-based refinements, and managed a multi-step parameter study to convergence under minimal human intervention. By adopting a transparent and interpretable paradigm, FlamePilot establishes a foundational framework for AI-empowered combustion modeling, fostering a collaborative partnership where the agent manages workflow orchestration, freeing the researcher for high-level analysis.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Benchmarking neural surrogates on realistic spatiotemporal multiphysics flows
Dec 21, 2025Predicting multiphysics dynamics is computationally expensive and challenging due to the severe coupling of multi-scale, heterogeneous physical processes. While neural surrogates promise a paradigm shift, the field currently suffers from an "illusion of mastery", as repeatedly emphasized in top-tier commentaries: existing evaluations overly rely on simplified, low-dimensional proxies, which fail to expose the models' inherent fragility in realistic regimes. To bridge this critical gap, we present REALM (REalistic AI Learning for Multiphysics), a rigorous benchmarking framework designed to test neural surrogates on challenging, application-driven reactive flows. REALM features 11 high-fidelity datasets spanning from canonical multiphysics problems to complex propulsion and fire safety scenarios, alongside a standardized end-to-end training and evaluation protocol that incorporates multiphysics-aware preprocessing and a robust rollout strategy. Using this framework, we systematically benchmark over a dozen representative surrogate model families, including spectral operators, convolutional models, Transformers, pointwise operators, and graph/mesh networks, and identify three robust trends: (i) a scaling barrier governed jointly by dimensionality, stiffness, and mesh irregularity, leading to rapidly growing rollout errors; (ii) performance primarily controlled by architectural inductive biases rather than parameter count; and (iii) a persistent gap between nominal accuracy metrics and physically trustworthy behavior, where models with high correlations still miss key transient structures and integral quantities. Taken together, REALM exposes the limits of current neural surrogates on realistic multiphysics flows and offers a rigorous testbed to drive the development of next-generation physics-aware architectures.
A multi-scale sampling method for accurate and robust deep neural network to predict combustion chemical kinetics
Jan 09, 2022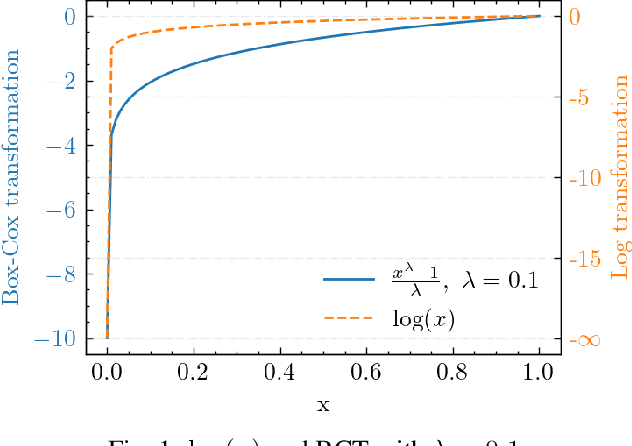
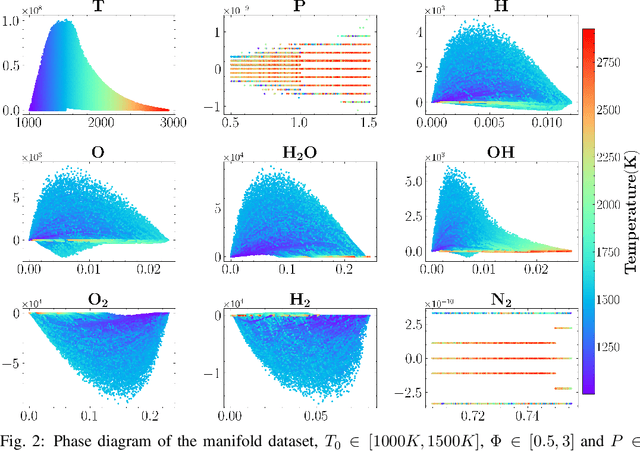
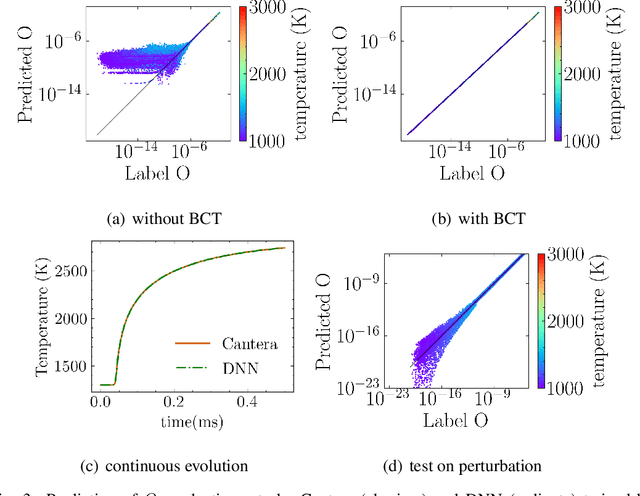
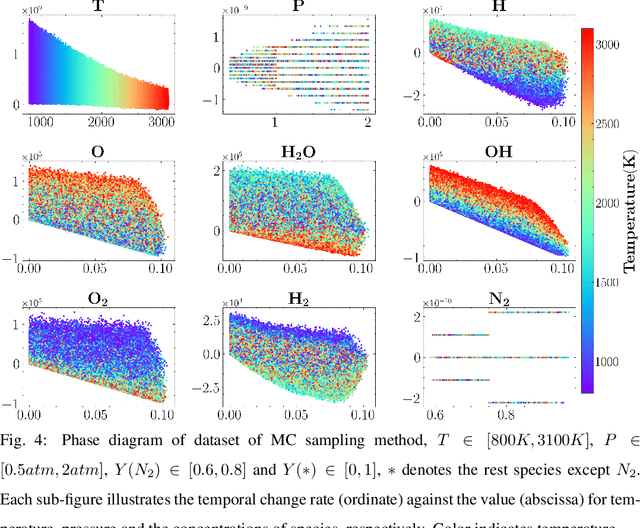
Machine learning has long been considered as a black box for predicting combustion chemical kinetics due to the extremely large number of parameters and the lack of evaluation standards and reproducibility. The current work aims to understand two basic questions regarding the deep neural network (DNN) method: what data the DNN needs and how general the DNN method can be. Sampling and preprocessing determine the DNN training dataset, further affect DNN prediction ability. The current work proposes using Box-Cox transformation (BCT) to preprocess the combustion data. In addition, this work compares different sampling methods with or without preprocessing, including the Monte Carlo method, manifold sampling, generative neural network method (cycle-GAN), and newly-proposed multi-scale sampling. Our results reveal that the DNN trained by the manifold data can capture the chemical kinetics in limited configurations but cannot remain robust toward perturbation, which is inevitable for the DNN coupled with the flow field. The Monte Carlo and cycle-GAN samplings can cover a wider phase space but fail to capture small-scale intermediate species, producing poor prediction results. A three-hidden-layer DNN, based on the multi-scale method without specific flame simulation data, allows predicting chemical kinetics in various scenarios and being stable during the temporal evolutions. This single DNN is readily implemented with several CFD codes and validated in various combustors, including (1). zero-dimensional autoignition, (2). one-dimensional freely propagating flame, (3). two-dimensional jet flame with triple-flame structure, and (4). three-dimensional turbulent lifted flames. The results demonstrate the satisfying accuracy and generalization ability of the pre-trained DNN. The Fortran and Python versions of DNN and example code are attached in the supplementary for reproducibility.