 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeVid: Toward Safety Aligned Video Large Multimodal Models
May 17, 2025As Video Large Multimodal Models (VLMMs) rapidly advance, their inherent complexity introduces significant safety challenges, particularly the issue of mismatched generalization where static safety alignments fail to transfer to dynamic video contexts. We introduce SafeVid, a framework designed to instill video-specific safety principles in VLMMs. SafeVid uniquely transfers robust textual safety alignment capabilities to the video domain by employing detailed textual video descriptions as an interpretive bridge, facilitating LLM-based rule-driven safety reasoning. This is achieved through a closed-loop system comprising: 1) generation of SafeVid-350K, a novel 350,000-pair video-specific safety preference dataset; 2) targeted alignment of VLMMs using Direct Preference Optimization (DPO); and 3) comprehensive evaluation via our new SafeVidBench benchmark. Alignment with SafeVid-350K significantly enhances VLMM safety, with models like LLaVA-NeXT-Video demonstrating substantial improvements (e.g., up to 42.39%) on SafeVidBench. SafeVid provides critical resources and a structured approach, demonstrating that leveraging textual descriptions as a conduit for safety reasoning markedly improves the safety alignment of VLMMs. We have made SafeVid-350K dataset (https://huggingface.co/datasets/yxwang/SafeVid-350K) publicly available.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025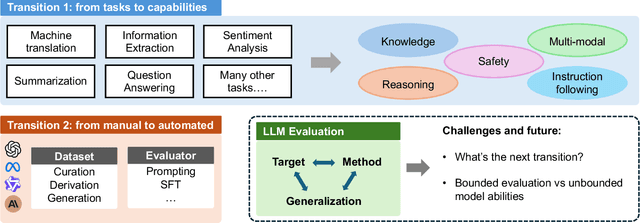
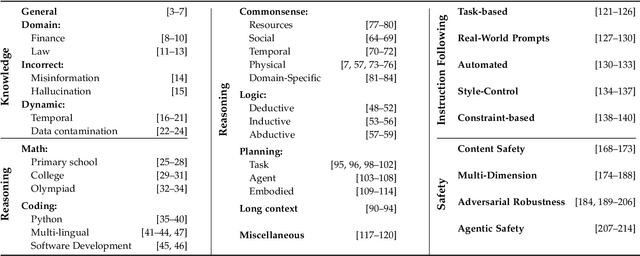
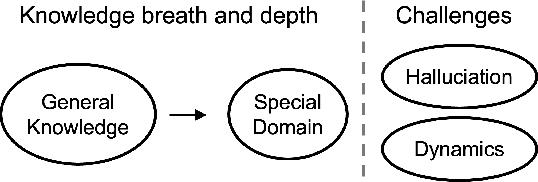
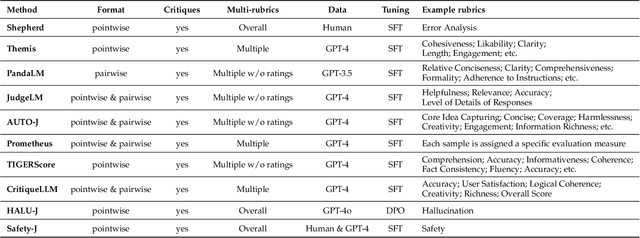
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
Apr 15, 2025This work presents SimpleAR, a vanilla autoregressive visual generation framework without complex architecure modifications. Through careful exploration of training and inference optimization, we demonstrate that: 1) with only 0.5B parameters, our model can generate 1024x1024 resolution images with high fidelity, and achieve competitive results on challenging text-to-image benchmarks, e.g., 0.59 on GenEval and 79.66 on DPG; 2) both supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) training could lead to significant improvements on generation aesthectics and prompt alignment; and 3) when optimized with inference acceleraton techniques like vLLM, the time for SimpleAR to generate an 1024x1024 image could be reduced to around 14 seconds. By sharing these findings and open-sourcing the code, we hope to reveal the potential of autoregressive visual generation and encourage more participation in this research field. Code is available at https://github.com/wdrink/SimpleAR.
Don't Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMs
Apr 13, 2025



Large Multimodal Models (LMMs) have demonstrated remarkable capabilities across a wide range of tasks. However, their vulnerability to user gaslighting-the deliberate use of misleading or contradictory inputs-raises critical concerns about their reliability in real-world applications. In this paper, we address the novel and challenging issue of mitigating the negative impact of negation-based gaslighting on LMMs, where deceptive user statements lead to significant drops in model accuracy. Specifically, we introduce GasEraser, a training-free approach that reallocates attention weights from misleading textual tokens to semantically salient visual regions. By suppressing the influence of "attention sink" tokens and enhancing focus on visually grounded cues, GasEraser significantly improves LMM robustness without requiring retraining or additional supervision. Extensive experimental results demonstrate that GasEraser is effective across several leading open-source LMMs on the GaslightingBench. Notably, for LLaVA-v1.5-7B, GasEraser reduces the misguidance rate by 48.2%, demonstrating its potential for more trustworthy LMMs.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
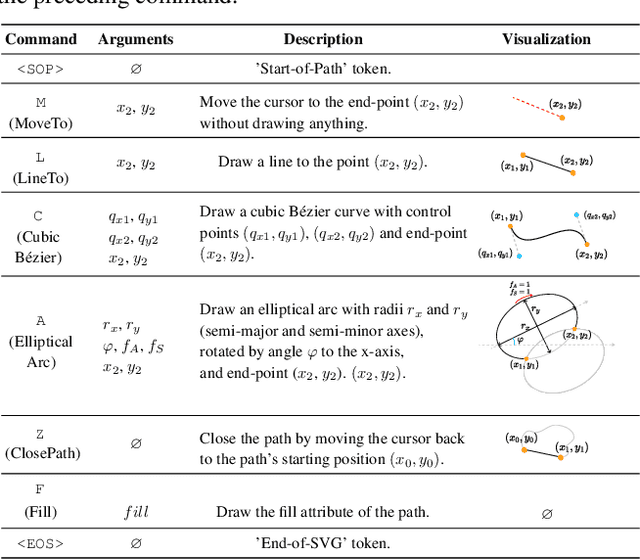


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
UniToken: Harmonizing Multimodal Understanding and Generation through Unified Visual Encoding
Apr 06, 2025We introduce UniToken, an auto-regressive generation model that encodes visual inputs through a combination of discrete and continuous representations, enabling seamless integration of unified visual understanding and image generation tasks. Unlike previous approaches that rely on unilateral visual representations, our unified visual encoding framework captures both high-level semantics and low-level details, delivering multidimensional information that empowers heterogeneous tasks to selectively assimilate domain-specific knowledge based on their inherent characteristics. Through in-depth experiments, we uncover key principles for developing a unified model capable of both visual understanding and image generation. Extensive evaluations across a diverse range of prominent benchmarks demonstrate that UniToken achieves state-of-the-art performance, surpassing existing approaches. These results establish UniToken as a robust foundation for future research in this domain. The code and models are available at https://github.com/SxJyJay/UniToken.
CoMP: Continual Multimodal Pre-training for Vision Foundation Models
Mar 24, 2025Pre-trained Vision Foundation Models (VFMs) provide strong visual representations for a wide range of applications. In this paper, we continually pre-train prevailing VFMs in a multimodal manner such that they can effortlessly process visual inputs of varying sizes and produce visual representations that are more aligned with language representations, regardless of their original pre-training process. To this end, we introduce CoMP, a carefully designed multimodal pre-training pipeline. CoMP uses a Continual Rotary Position Embedding to support native resolution continual pre-training, and an Alignment Loss between visual and textual features through language prototypes to align multimodal representations. By three-stage training, our VFMs achieve remarkable improvements not only in multimodal understanding but also in other downstream tasks such as classification and segmentation. Remarkably, CoMP-SigLIP achieves scores of 66.7 on ChartQA and 75.9 on DocVQA with a 0.5B LLM, while maintaining an 87.4% accuracy on ImageNet-1K and a 49.5 mIoU on ADE20K under frozen chunk evaluation.
Revealing the Implicit Noise-based Imprint of Generative Models
Mar 12, 2025With the rapid advancement of vision generation models, the potential security risks stemming from synthetic visual content have garnered increasing attention, posing significant challenges for AI-generated image detection. Existing methods suffer from inadequate generalization capabilities, resulting in unsatisfactory performance on emerging generative models. To address this issue, this paper presents a novel framework that leverages noise-based model-specific imprint for the detection task. Specifically, we propose a novel noise-based imprint simulator to capture intrinsic patterns imprinted in images generated by different models. By aggregating imprints from various generative models, imprints of future models can be extrapolated to expand training data, thereby enhancing generalization and robustness. Furthermore, we design a new pipeline that pioneers the use of noise patterns, derived from a noise-based imprint extractor, alongside other visual features for AI-generated image detection, resulting in a significant improvement in performance. Our approach achieves state-of-the-art performance across three public benchmarks including GenImage, Synthbuster and Chameleon.