 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASP: Topology-aware Sequence Parallelism
Sep 30, 2025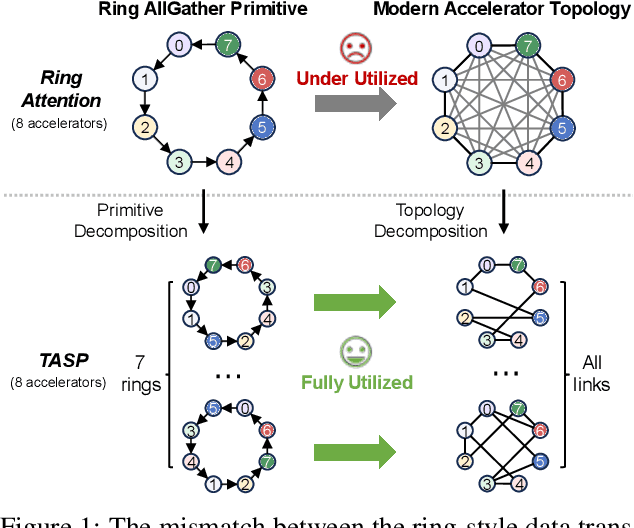


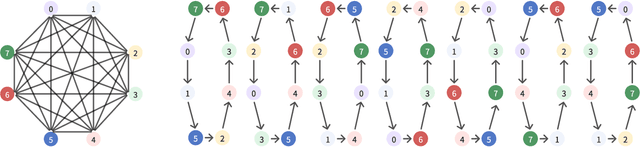
Long-context large language models (LLMs) face constraints due to the quadratic complexity of the self-attention mechanism. The mainstream sequence parallelism (SP) method, Ring Attention, attempts to solve this by distributing the query into multiple query chunks across accelerators and enable each Q tensor to access all KV tensors from other accelerators via the Ring AllGather communication primitive. However, it exhibits low communication efficiency, restricting its practical applicability. This inefficiency stems from the mismatch between the Ring AllGather communication primitive it adopts and the AlltoAll topology of modern accelerators. A Ring AllGather primitive is composed of iterations of ring-styled data transfer, which can only utilize a very limited fraction of an AlltoAll topology. Inspired by the Hamiltonian decomposition of complete directed graphs, we identify that modern accelerator topology can be decomposed into multiple orthogonal ring datapaths which can concurrently transfer data without interference. Based on this, we further observe that the Ring AllGather primitive can also be decomposed into the same number of concurrent ring-styled data transfer at every iteration. Based on these insights, we propose TASP, a topology-aware SP method for long-context LLMs that fully utilizes the communication capacity of modern accelerators via topology decomposition and primitive decomposition. Experimental results on both single-node and multi-node NVIDIA H100 systems and a single-node AMD MI300X system demonstrate that TASP achieves higher communication efficiency than Ring Attention on these modern accelerator topologies and achieves up to 3.58 speedup than Ring Attention and its variant Zigzag-Ring Attention. The code is available at https://github.com/infinigence/HamiltonAttention.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025
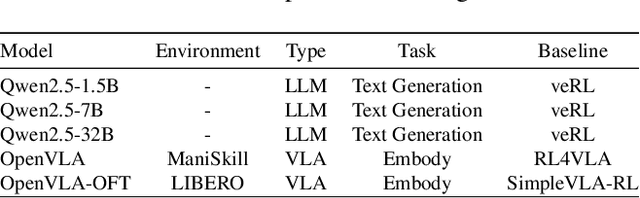

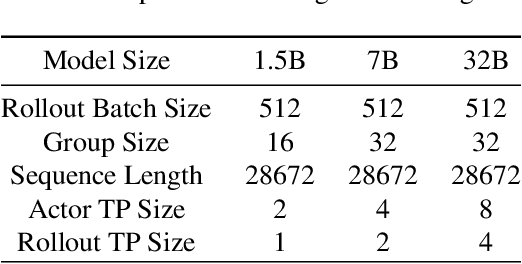
Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Discovering Mathematical Equations with Diffusion Language Model
Sep 16, 2025Discovering valid and meaningful mathematical equations from observed data plays a crucial role in scientific discovery. While this task, symbolic regression, remains challenging due to the vast search space and the trade-off between accuracy and complexity. In this paper, we introduce DiffuSR, a pre-training framework for symbolic regression built upon a continuous-state diffusion language model. DiffuSR employs a trainable embedding layer within the diffusion process to map discrete mathematical symbols into a continuous latent space, modeling equation distributions effectively. Through iterative denoising, DiffuSR converts an initial noisy sequence into a symbolic equation, guided by numerical data injected via a cross-attention mechanism. We also design an effective inference strategy to enhance the accuracy of the diffusion-based equation generator, which injects logit priors into genetic programming. Experimental results on standard symbolic regression benchmarks demonstrate that DiffuSR achieves competitive performance with state-of-the-art autoregressive methods and generates more interpretable and diverse mathematical expressions.
Positional Encoding via Token-Aware Phase Attention
Sep 16, 2025We prove under practical assumptions that Rotary Positional Embedding (RoPE) introduces an intrinsic distance-dependent bias in attention scores that limits RoPE's ability to model long-context. RoPE extension methods may alleviate this issue, but they typically require post-hoc adjustments after pretraining, such as rescaling or hyperparameters retuning. This paper introduces Token-Aware Phase Attention (TAPA), a new positional encoding method that incorporates a learnable phase function into the attention mechanism. TAPA preserves token interactions over long range, extends to longer contexts with direct and light fine-tuning, extrapolates to unseen lengths, and attains significantly lower perplexity on long-context than RoPE families.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
FinZero: Launching Multi-modal Financial Time Series Forecast with Large Reasoning Model
Sep 10, 2025Financial time series forecasting is both highly significant and challenging. Previous approaches typically standardized time series data before feeding it into forecasting models, but this encoding process inherently leads to a loss of important information. Moreover, past time series models generally require fixed numbers of variables or lookback window lengths, which further limits the scalability of time series forecasting. Besides, the interpretability and the uncertainty in forecasting remain areas requiring further research, as these factors directly impact the reliability and practical value of predictions. To address these issues, we first construct a diverse financial image-text dataset (FVLDB) and develop the Uncertainty-adjusted Group Relative Policy Optimization (UARPO) method to enable the model not only output predictions but also analyze the uncertainty of those predictions. We then proposed FinZero, a multimodal pre-trained model finetuned by UARPO to perform reasoning, prediction, and analytical understanding on the FVLDB financial time series. Extensive experiments validate that FinZero exhibits strong adaptability and scalability. After fine-tuning with UARPO, FinZero achieves an approximate 13.48\% improvement in prediction accuracy over GPT-4o in the high-confidence group, demonstrating the effectiveness of reinforcement learning fine-tuning in multimodal large model, including in financial time series forecasting tasks.
TemporalFlowViz: Parameter-Aware Visual Analytics for Interpreting Scramjet Combustion Evolution
Sep 05, 2025



Understanding the complex combustion dynamics within scramjet engines is critical for advancing high-speed propulsion technologies. However, the large scale and high dimensionality of simulation-generated temporal flow field data present significant challenges for visual interpretation, feature differentiation, and cross-case comparison. In this paper, we present TemporalFlowViz, a parameter-aware visual analytics workflow and system designed to support expert-driven clustering, visualization, and interpretation of temporal flow fields from scramjet combustion simulations. Our approach leverages hundreds of simulated combustion cases with varying initial conditions, each producing time-sequenced flow field images. We use pretrained Vision Transformers to extract high-dimensional embeddings from these frames, apply dimensionality reduction and density-based clustering to uncover latent combustion modes, and construct temporal trajectories in the embedding space to track the evolution of each simulation over time. To bridge the gap between latent representations and expert reasoning, domain specialists annotate representative cluster centroids with descriptive labels. These annotations are used as contextual prompts for a vision-language model, which generates natural-language summaries for individual frames and full simulation cases. The system also supports parameter-based filtering, similarity-based case retrieval, and coordinated multi-view exploration to facilitate in-depth analysis. We demonstrate the effectiveness of TemporalFlowViz through two expert-informed case studies and expert feedback, showing TemporalFlowViz enhances hypothesis generation, supports interpretable pattern discovery, and enhances knowledge discovery in large-scale scramjet combustion analysis.
VocabTailor: Dynamic Vocabulary Selection for Downstream Tasks in Small Language Models
Aug 21, 2025Small Language Models (SLMs) provide computational advantages in resource-constrained environments, yet memory limitations remain a critical bottleneck for edge device deployment. A substantial portion of SLMs' memory footprint stems from vocabulary-related components, particularly embeddings and language modeling (LM) heads, due to large vocabulary sizes. Existing static vocabulary pruning, while reducing memory usage, suffers from rigid, one-size-fits-all designs that cause information loss from the prefill stage and a lack of flexibility. In this work, we identify two key principles underlying the vocabulary reduction challenge: the lexical locality principle, the observation that only a small subset of tokens is required during any single inference, and the asymmetry in computational characteristics between vocabulary-related components of SLM. Based on these insights, we introduce VocabTailor, a novel decoupled dynamic vocabulary selection framework that addresses memory constraints through offloading embedding and implements a hybrid static-dynamic vocabulary selection strategy for LM Head, enabling on-demand loading of vocabulary components. Comprehensive experiments across diverse downstream tasks demonstrate that VocabTailor achieves a reduction of up to 99% in the memory usage of vocabulary-related components with minimal or no degradation in task performance, substantially outperforming existing static vocabulary pruning.
Img2ST-Net: Efficient High-Resolution Spatial Omics Prediction from Whole Slide Histology Images via Fully Convolutional Image-to-Image Learning
Aug 20, 2025



Recent advances in multi-modal AI have demonstrated promising potential for generating the currently expensive spatial transcriptomics (ST) data directly from routine histology images, offering a means to reduce the high cost and time-intensive nature of ST data acquisition. However, the increasing resolution of ST, particularly with platforms such as Visium HD achieving 8um or finer, introduces significant computational and modeling challenges. Conventional spot-by-spot sequential regression frameworks become inefficient and unstable at this scale, while the inherent extreme sparsity and low expression levels of high-resolution ST further complicate both prediction and evaluation. To address these limitations, we propose Img2ST-Net, a novel histology-to-ST generation framework for efficient and parallel high-resolution ST prediction. Unlike conventional spot-by-spot inference methods, Img2ST-Net employs a fully convolutional architecture to generate dense, HD gene expression maps in a parallelized manner. By modeling HD ST data as super-pixel representations, the task is reformulated from image-to-omics inference into a super-content image generation problem with hundreds or thousands of output channels. This design not only improves computational efficiency but also better preserves the spatial organization intrinsic to spatial omics data. To enhance robustness under sparse expression patterns, we further introduce SSIM-ST, a structural-similarity-based evaluation metric tailored for high-resolution ST analysis. We present a scalable, biologically coherent framework for high-resolution ST prediction. Img2ST-Net offers a principled solution for efficient and accurate ST inference at scale. Our contributions lay the groundwork for next-generation ST modeling that is robust and resolution-aware. The source code has been made publicly available at https://github.com/hrlblab/Img2ST-Net.
ZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025



Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.