 Add to Chrome
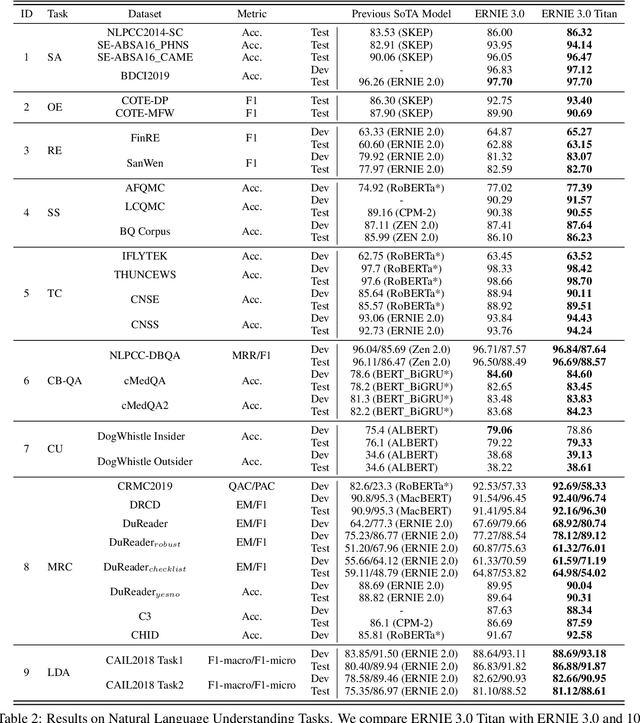
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neonatal Face Detection in Real-world Clinical Settings
Apr 01, 2022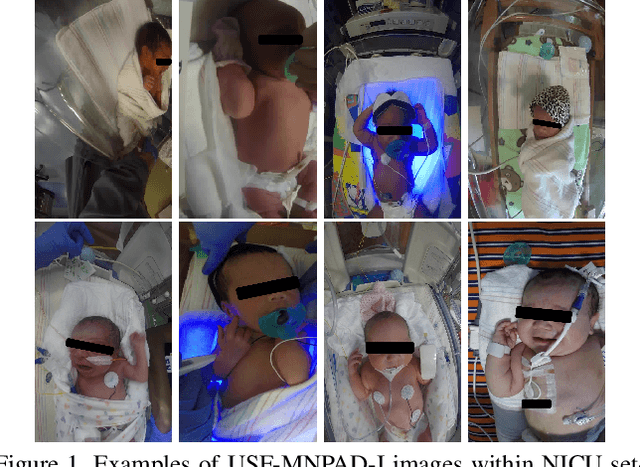

Current face detection algorithms are extremely generalized and can obtain decent accuracy when detecting the adult faces. These approaches are insufficient when handling outlier cases, for example when trying to detect the face of a neonate infant whose face composition and expressions are relatively different than that of the adult. It is furthermore difficult when applied to detect faces in a complicated setting such as the Neonate Intensive Care Unit. By training a state-of-the-art face detection model, You-Only-Look-Once, on a proprietary dataset containing labelled neonate faces in a clinical setting, this work achieves near real time neonate face detection. Our preliminary findings show an accuracy of 68.7%, compared to the off the shelf solution which detected neonate faces with an accuracy of 7.37%. Although further experiments are needed to validate our model, our results are promising and prove the feasibility of detecting neonatal faces in challenging real-world settings. The robust and real-time detection of neonatal faces would benefit wide range of automated systems (e.g., pain recognition and surveillance) who currently suffer from the time and effort due to the necessity of manual annotations. To benefit the research community, we make our trained weights publicly available at github(https://github.com/ja05haus/trained_neonate_face).
ERNIE-SPARSE: Learning Hierarchical Efficient Transformer Through Regularized Self-Attention
Mar 23, 2022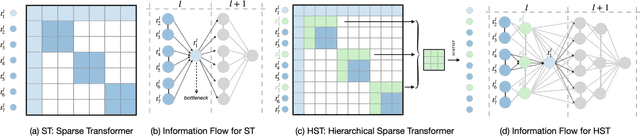
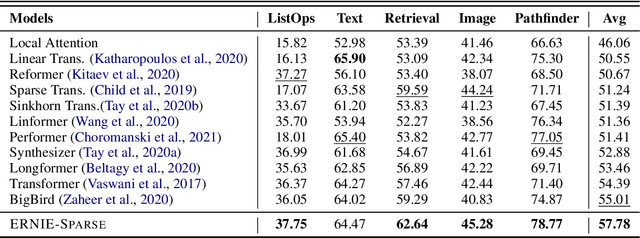
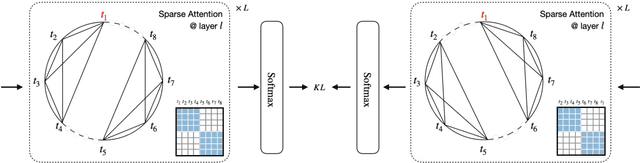
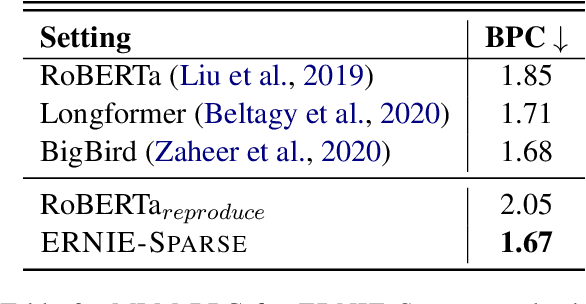
Sparse Transformer has recently attracted a lot of attention since the ability for reducing the quadratic dependency on the sequence length. We argue that two factors, information bottleneck sensitivity and inconsistency between different attention topologies, could affect the performance of the Sparse Transformer. This paper proposes a well-designed model named ERNIE-Sparse. It consists of two distinctive parts: (i) Hierarchical Sparse Transformer (HST) to sequentially unify local and global information. (ii) Self-Attention Regularization (SAR) method, a novel regularization designed to minimize the distance for transformers with different attention topologies. To evaluate the effectiveness of ERNIE-Sparse, we perform extensive evaluations. Firstly, we perform experiments on a multi-modal long sequence modeling task benchmark, Long Range Arena (LRA). Experimental results demonstrate that ERNIE-Sparse significantly outperforms a variety of strong baseline methods including the dense attention and other efficient sparse attention methods and achieves improvements by 2.77% (57.78% vs. 55.01%). Secondly, to further show the effectiveness of our method, we pretrain ERNIE-Sparse and verified it on 3 text classification and 2 QA downstream tasks, achieve improvements on classification benchmark by 0.83% (92.46% vs. 91.63%), on QA benchmark by 3.24% (74.67% vs. 71.43%). Experimental results continue to demonstrate its superior performance.
Learning Cross-Video Neural Representations for High-Quality Frame Interpolation
Feb 28, 2022
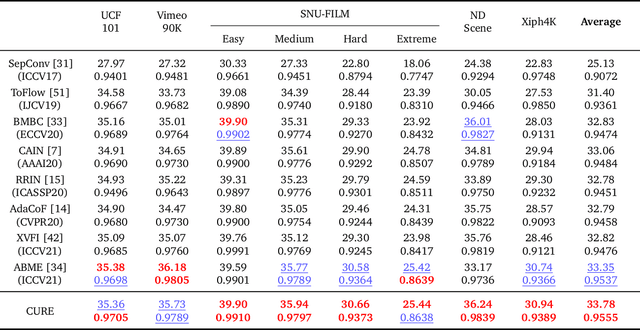
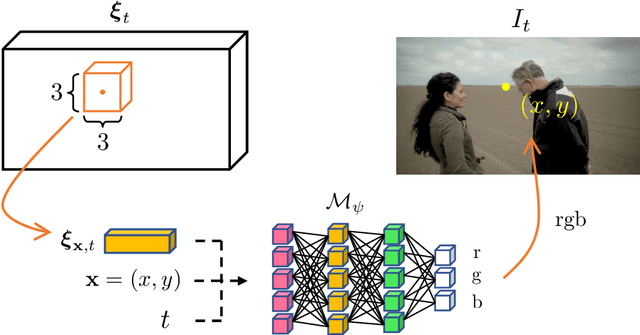
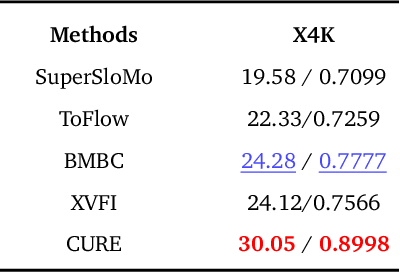
This paper considers the problem of temporal video interpolation, where the goal is to synthesize a new video frame given its two neighbors. We propose Cross-Video Neural Representation (CURE) as the first video interpolation method based on neural fields (NF). NF refers to the recent class of methods for the neural representation of complex 3D scenes that has seen widespread success and application across computer vision. CURE represents the video as a continuous function parameterized by a coordinate-based neural network, whose inputs are the spatiotemporal coordinates and outputs are the corresponding RGB values. CURE introduces a new architecture that conditions the neural network on the input frames for imposing space-time consistency in the synthesized video. This not only improves the final interpolation quality, but also enables CURE to learn a prior across multiple videos. Experimental evaluations show that CURE achieves the state-of-the-art performance on video interpolation on several benchmark datasets.
Graph Neural Networks for Double-Strand DNA Breaks Prediction
Jan 04, 2022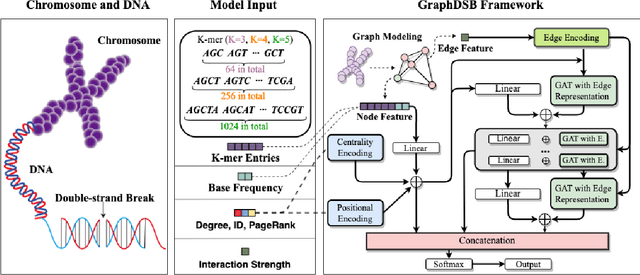
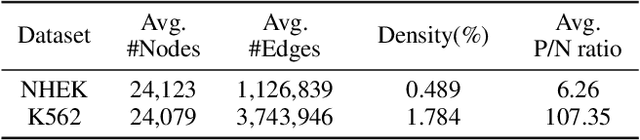

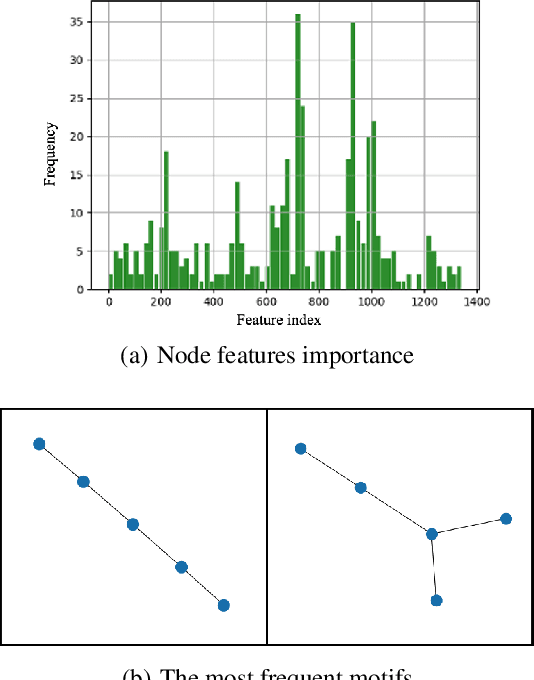
Double-strand DNA breaks (DSBs) are a form of DNA damage that can cause abnormal chromosomal rearrangements. Recent technologies based on high-throughput experiments have obvious high costs and technical challenges.Therefore, we design a graph neural network based method to predict DSBs (GraphDSB), using DNA sequence features and chromosome structure information. In order to improve the expression ability of the model, we introduce Jumping Knowledge architecture and several effective structural encoding methods. The contribution of structural information to the prediction of DSBs is verified by the experiments on datasets from normal human epidermal keratinocytes (NHEK) and chronic myeloid leukemia cell line (K562), and the ablation studies further demonstrate the effectiveness of the designed components in the proposed GraphDSB framework. Finally, we use GNNExplainer to analyze the contribution of node features and topology to DSBs prediction, and proved the high contribution of 5-mer DNA sequence features and two chromatin interaction modes.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021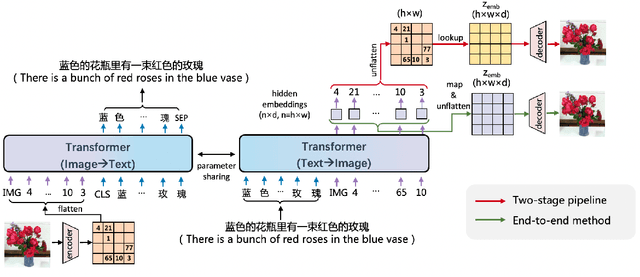
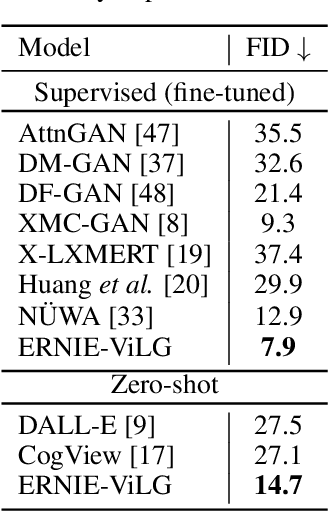
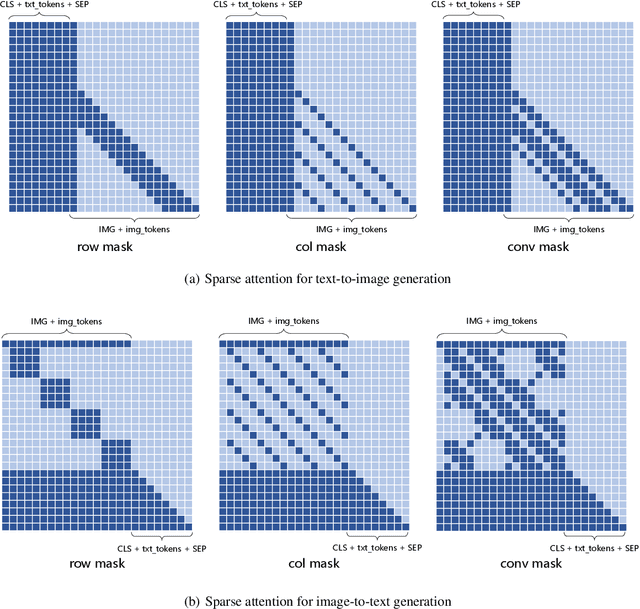

Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021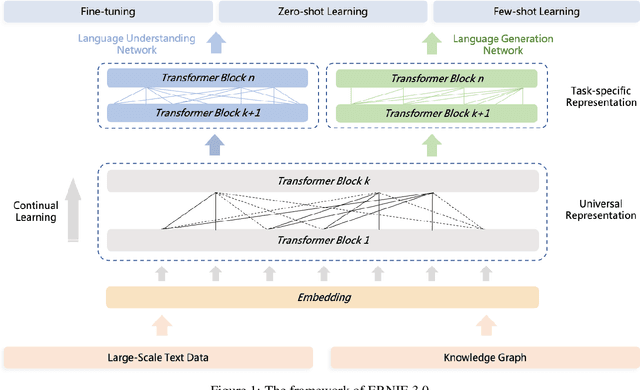
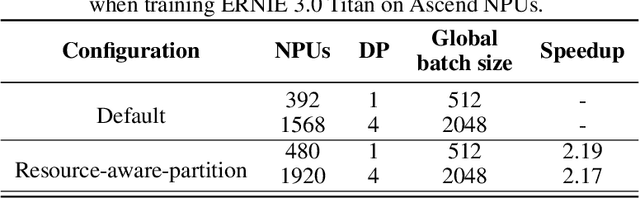
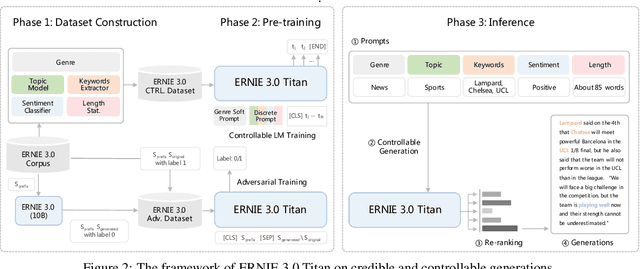
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
Calorie Aware Automatic Meal Kit Generation from an Image
Dec 18, 2021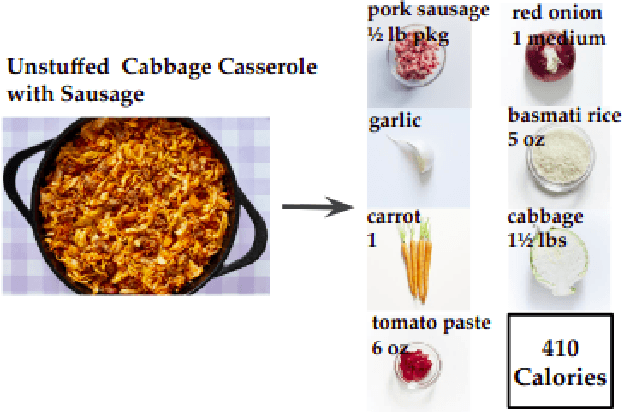
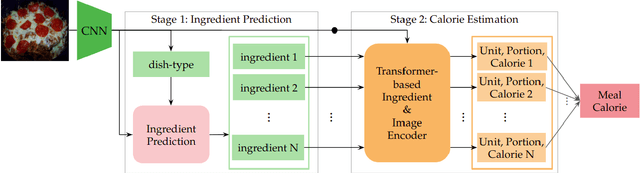
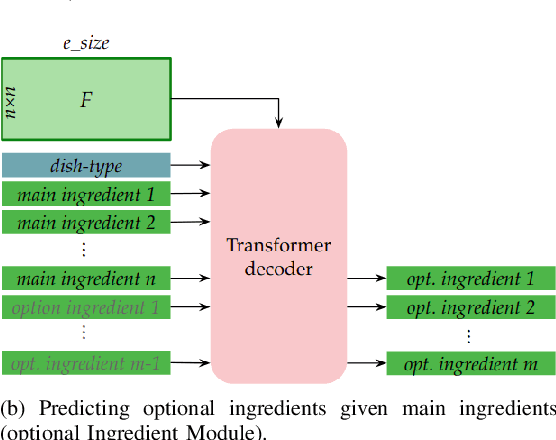
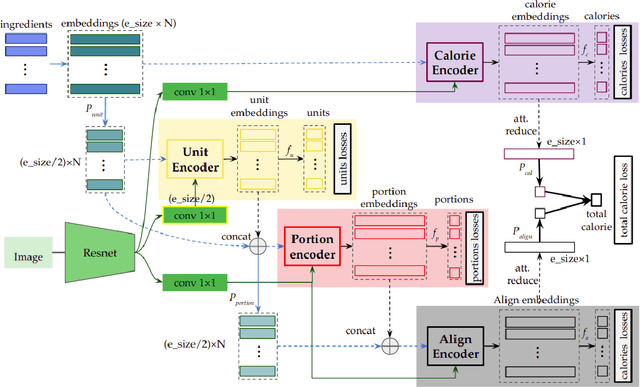
Calorie and nutrition research has attained increased interest in recent years. But, due to the complexity of the problem, literature in this area focuses on a limited subset of ingredients or dish types and simple convolutional neural networks or traditional machine learning. Simultaneously, estimation of ingredient portions can help improve calorie estimation and meal re-production from a given image. In this paper, given a single cooking image, a pipeline for calorie estimation and meal re-production for different servings of the meal is proposed. The pipeline contains two stages. In the first stage, a set of ingredients associated with the meal in the given image are predicted. In the second stage, given image features and ingredients, portions of the ingredients and finally the total meal calorie are simultaneously estimated using a deep transformer-based model. Portion estimation introduced in the model helps improve calorie estimation and is also beneficial for meal re-production in different serving sizes. To demonstrate the benefits of the pipeline, the model can be used for meal kits generation. To evaluate the pipeline, the large scale dataset Recipe1M is used. Prior to experiments, the Recipe1M dataset is parsed and explicitly annotated with portions of ingredients. Experiments show that using ingredients and their portions significantly improves calorie estimation. Also, a visual interface is created in which a user can interact with the pipeline to reach accurate calorie estimations and generate a meal kit for cooking purposes.
Multi-Object Grasping -- Generating Efficient Robotic Picking and Transferring Policy
Dec 18, 2021
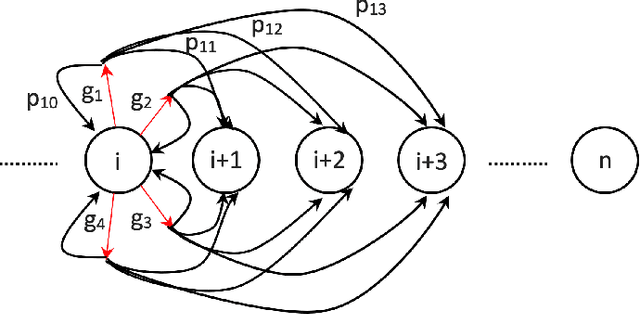

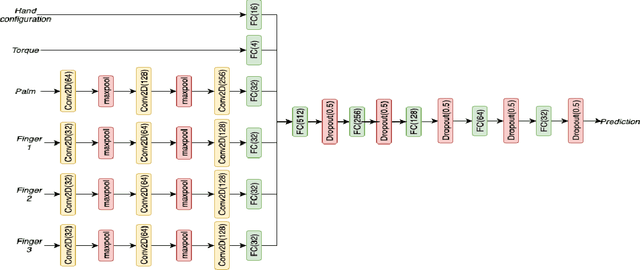
Transferring multiple objects between bins is a common task for many applications. In robotics, a standard approach is to pick up one object and transfer it at a time. However, grasping and picking up multiple objects and transferring them together at once is more efficient. This paper presents a set of novel strategies for efficiently grasping multiple objects in a bin to transfer them to another. The strategies enable a robotic hand to identify an optimal ready hand configuration (pre-grasp) and calculate a flexion synergy based on the desired quantity of objects to be grasped. This paper also presents an approach that uses the Markov decision process (MDP) to model the pick-transfer routines when the required quantity is larger than the capability of a single grasp. Using the MDP model, the proposed approach can generate an optimal pick-transfer routine that minimizes the number of transfers, representing efficiency. The proposed approach has been evaluated in both a simulation environment and on a real robotic system. The results show the approach reduces the number of transfers by 59% and the number of lifts by 58% compared to an optimal single object pick-transfer solution.
Putting People in their Place: Monocular Regression of 3D People in Depth
Dec 15, 2021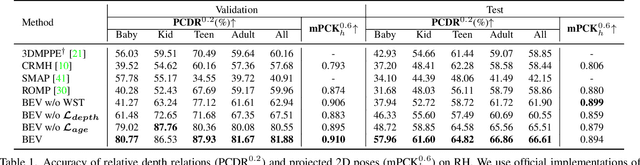
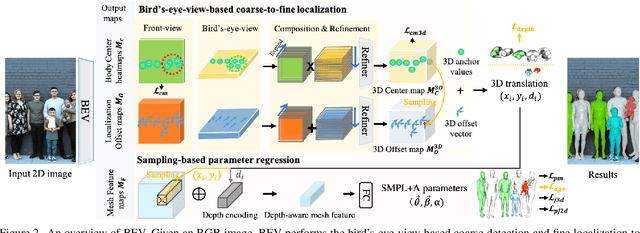
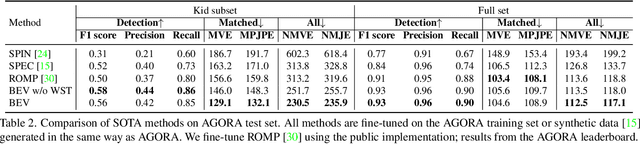

Given an image with multiple people, our goal is to directly regress the pose and shape of all the people as well as their relative depth. Inferring the depth of a person in an image, however, is fundamentally ambiguous without knowing their height. This is particularly problematic when the scene contains people of very different sizes, e.g. from infants to adults. To solve this, we need several things. First, we develop a novel method to infer the poses and depth of multiple people in a single image. While previous work that estimates multiple people does so by reasoning in the image plane, our method, called BEV, adds an additional imaginary Bird's-Eye-View representation to explicitly reason about depth. BEV reasons simultaneously about body centers in the image and in depth and, by combing these, estimates 3D body position. Unlike prior work, BEV is a single-shot method that is end-to-end differentiable. Second, height varies with age, making it impossible to resolve depth without also estimating the age of people in the image. To do so, we exploit a 3D body model space that lets BEV infer shapes from infants to adults. Third, to train BEV, we need a new dataset. Specifically, we create a "Relative Human" (RH) dataset that includes age labels and relative depth relationships between the people in the images. Extensive experiments on RH and AGORA demonstrate the effectiveness of the model and training scheme. BEV outperforms existing methods on depth reasoning, child shape estimation, and robustness to occlusion. The code and dataset will be released for research purposes.
Graph4Rec: A Universal Toolkit with Graph Neural Networks for Recommender Systems
Dec 08, 2021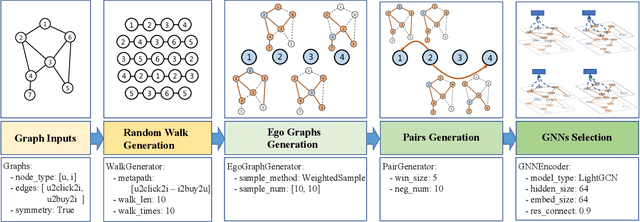
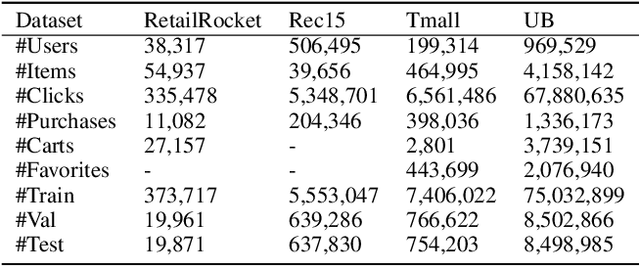
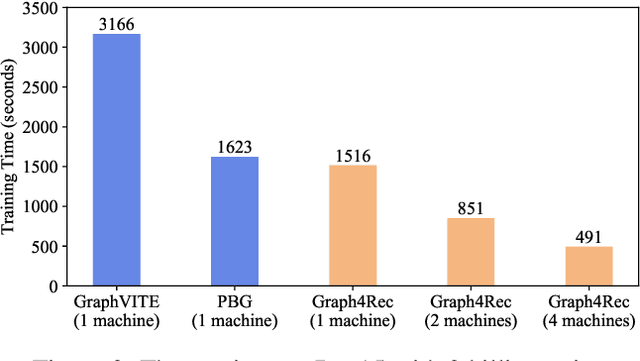

In recent years, owing to the outstanding performance in graph representation learning, graph neural network (GNN) techniques have gained considerable interests in many real-world scenarios, such as recommender systems and social networks. In recommender systems, the main challenge is to learn the effective user/item representations from their interactions. However, many recent publications using GNNs for recommender systems cannot be directly compared, due to their difference on datasets and evaluation metrics. Furthermore, many of them only provide a demo to conduct experiments on small datasets, which is far away to be applied in real-world recommender systems. To address this problem, we introduce Graph4Rec, a universal toolkit that unifies the paradigm to train GNN models into the following parts: graphs input, random walk generation, ego graphs generation, pairs generation and GNNs selection. From this training pipeline, one can easily establish his own GNN model with a few configurations. Besides, we develop a large-scale graph engine and a parameter server to support distributed GNN training. We conduct a systematic and comprehensive experiment to compare the performance of different GNN models on several scenarios in different scale. Extensive experiments are demonstrated to identify the key components of GNNs. We also try to figure out how the sparse and dense parameters affect the performance of GNNs. Finally, we investigate methods including negative sampling, ego graph construction order, and warm start strategy to find a more effective and efficient GNNs practice on recommender systems. Our toolkit is based on PGL https://github.com/PaddlePaddle/PGL and the code is opened source in https://github.com/PaddlePaddle/PGL/tree/main/apps/Graph4Rec.