 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN3H-Core: Neuron-designed Neural Network Accelerator via FPGA-based Heterogeneous Computing Cores
Dec 15, 2021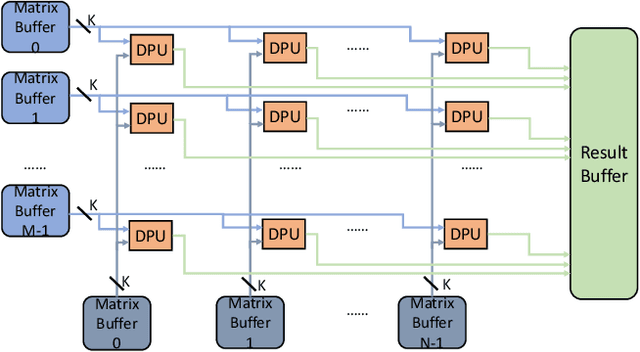
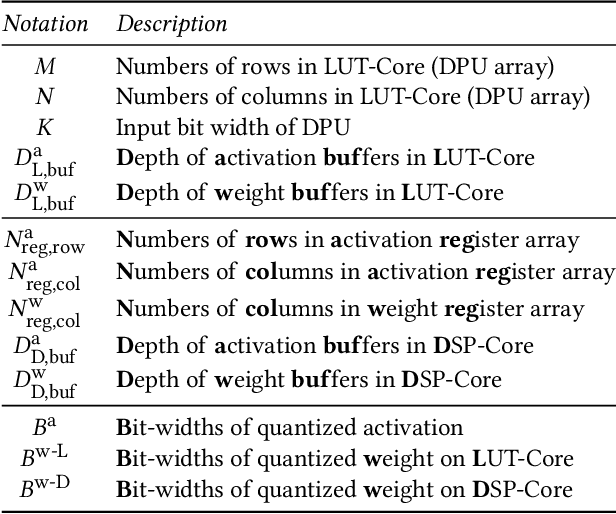
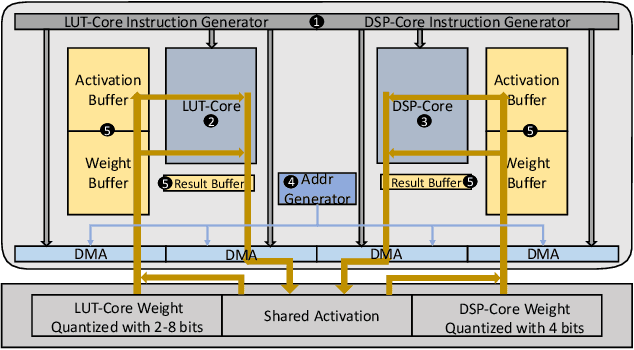
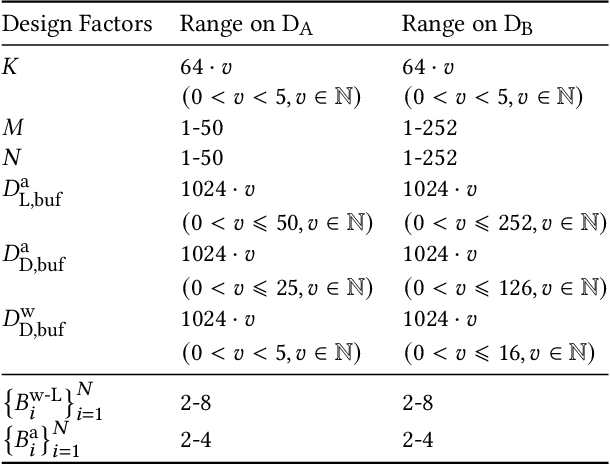
Accelerating the neural network inference by FPGA has emerged as a popular option, since the reconfigurability and high performance computing capability of FPGA intrinsically satisfies the computation demand of the fast-evolving neural algorithms. However, the popular neural accelerators on FPGA (e.g., Xilinx DPU) mainly utilize the DSP resources for constructing their processing units, while the rich LUT resources are not well exploited. Via the software-hardware co-design approach, in this work, we develop an FPGA-based heterogeneous computing system for neural network acceleration. From the hardware perspective, the proposed accelerator consists of DSP- and LUT-based GEneral Matrix-Multiplication (GEMM) computing cores, which forms the entire computing system in a heterogeneous fashion. The DSP- and LUT-based GEMM cores are computed w.r.t a unified Instruction Set Architecture (ISA) and unified buffers. Along the data flow of the neural network inference path, the computation of the convolution/fully-connected layer is split into two portions, handled by the DSP- and LUT-based GEMM cores asynchronously. From the software perspective, we mathematically and systematically model the latency and resource utilization of the proposed heterogeneous accelerator, regarding varying system design configurations. Through leveraging the reinforcement learning technique, we construct a framework to achieve end-to-end selection and optimization of the design specification of target heterogeneous accelerator, including workload split strategy, mixed-precision quantization scheme, and resource allocation of DSP- and LUT-core. In virtue of the proposed design framework and heterogeneous computing system, our design outperforms the state-of-the-art Mix&Match design with latency reduced by 1.12-1.32x with higher inference accuracy. The N3H-core is open-sourced at: https://github.com/elliothe/N3H_Core.
MUSE: Feature Self-Distillation with Mutual Information and Self-Information
Oct 25, 2021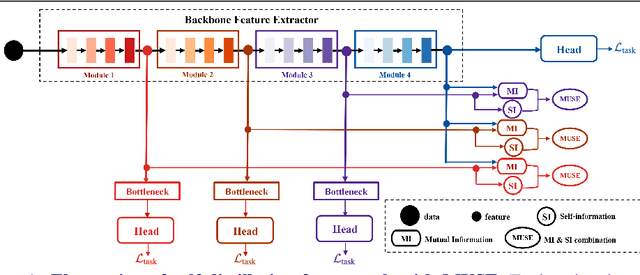
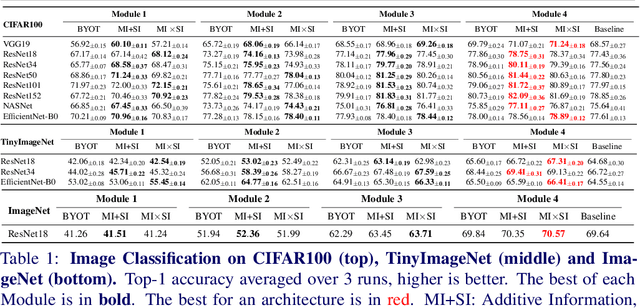

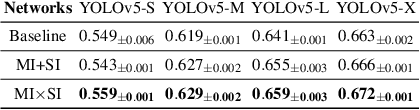
We present a novel information-theoretic approach to introduce dependency among features of a deep convolutional neural network (CNN). The core idea of our proposed method, called MUSE, is to combine MUtual information and SElf-information to jointly improve the expressivity of all features extracted from different layers in a CNN. We present two variants of the realization of MUSE -- Additive Information and Multiplicative Information. Importantly, we argue and empirically demonstrate that MUSE, compared to other feature discrepancy functions, is a more functional proxy to introduce dependency and effectively improve the expressivity of all features in the knowledge distillation framework. MUSE achieves superior performance over a variety of popular architectures and feature discrepancy functions for self-distillation and online distillation, and performs competitively with the state-of-the-art methods for offline distillation. MUSE is also demonstrably versatile that enables it to be easily extended to CNN-based models on tasks other than image classification such as object detection.
Blind Image Quality Assessment for MRI with A Deep Three-dimensional content-adaptive Hyper-Network
Jul 13, 2021



Image Quality Assessment (IQA) is of great value in the workflow of Magnetic Resonance Imaging (MRI)-based analysis. Blind IQA (BIQA) methods are especially required since high-quality reference MRI images are usually not available. Recently, many efforts have been devoted to developing deep learning-based BIQA approaches. However, the performance of these methods is limited due to the utilization of simple content-non-adaptive network parameters and the waste of the important 3D spatial information of the medical images. To address these issues, we design a 3D content-adaptive hyper-network for MRI BIQA. The overall 3D configuration enables the exploration of comprehensive 3D spatial information from MRI images, while the developed content-adaptive hyper-network contributes to the self-adaptive capacity of network parameters and thus, facilitates better BIQA performance. The effectiveness of the proposed method is extensively evaluated on the open dataset, MRIQC. Promising performance is achieved compared with the corresponding baseline and 4 state-of-the-art BIQA methods. We make our code available at \url{https://git.openi.org.cn/SIAT_Wangshanshan/HyS-Net}.
GRN: Generative Rerank Network for Context-wise Recommendation
Apr 07, 2021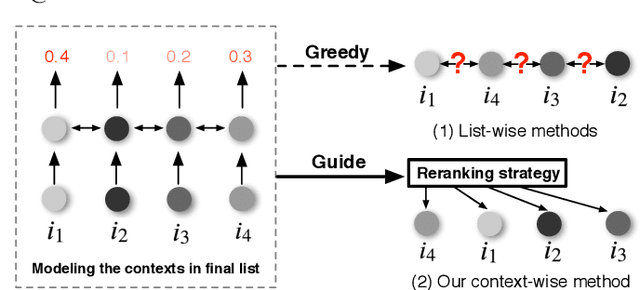
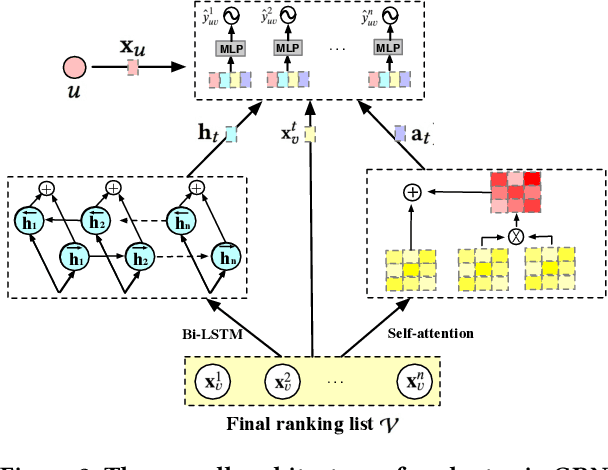
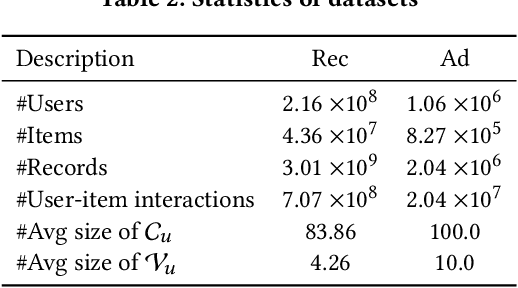
Reranking is attracting incremental attention in the recommender systems, which rearranges the input ranking list into the final rank-ing list to better meet user demands. Most existing methods greedily rerank candidates through the rating scores from point-wise or list-wise models. Despite effectiveness, neglecting the mutual influence between each item and its contexts in the final ranking list often makes the greedy strategy based reranking methods sub-optimal. In this work, we propose a new context-wise reranking framework named Generative Rerank Network (GRN). Specifically, we first design the evaluator, which applies Bi-LSTM and self-attention mechanism to model the contextual information in the labeled final ranking list and predict the interaction probability of each item more precisely. Afterwards, we elaborate on the generator, equipped with GRU, attention mechanism and pointer network to select the item from the input ranking list step by step. Finally, we apply cross-entropy loss to train the evaluator and, subsequently, policy gradient to optimize the generator under the guidance of the evaluator. Empirical results show that GRN consistently and significantly outperforms state-of-the-art point-wise and list-wise methods. Moreover, GRN has achieved a performance improvement of 5.2% on PV and 6.1% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.
Variational Selective Autoencoder: Learning from Partially-Observed Heterogeneous Data
Feb 25, 2021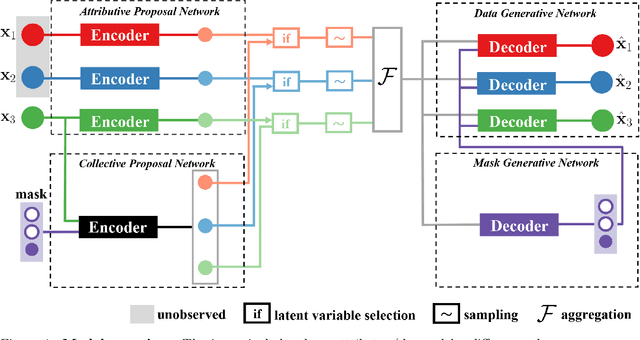
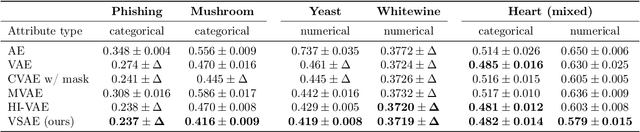
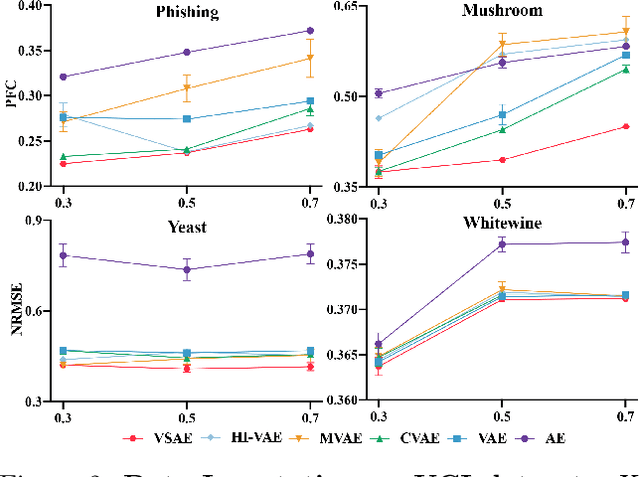
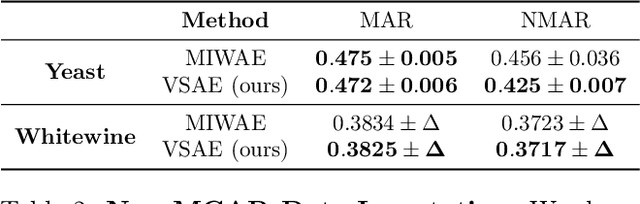
Learning from heterogeneous data poses challenges such as combining data from various sources and of different types. Meanwhile, heterogeneous data are often associated with missingness in real-world applications due to heterogeneity and noise of input sources. In this work, we propose the variational selective autoencoder (VSAE), a general framework to learn representations from partially-observed heterogeneous data. VSAE learns the latent dependencies in heterogeneous data by modeling the joint distribution of observed data, unobserved data, and the imputation mask which represents how the data are missing. It results in a unified model for various downstream tasks including data generation and imputation. Evaluation on both low-dimensional and high-dimensional heterogeneous datasets for these two tasks shows improvement over state-of-the-art models.
Revisit Recommender System in the Permutation Prospective
Feb 24, 2021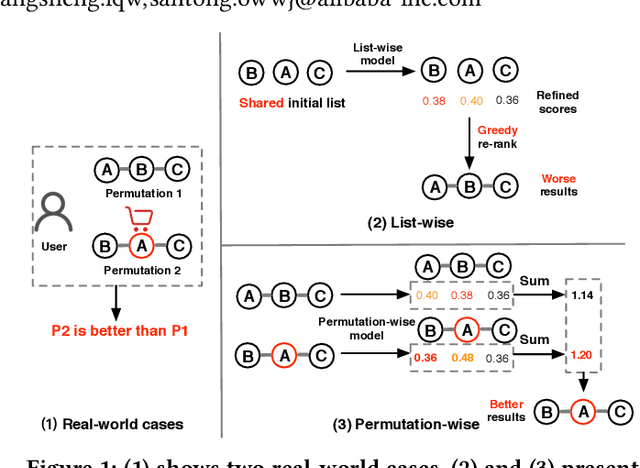
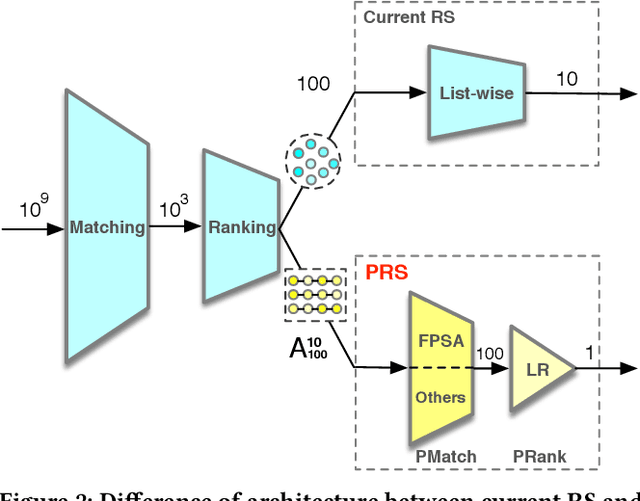
Recommender systems (RS) work effective at alleviating information overload and matching user interests in various web-scale applications. Most RS retrieve the user's favorite candidates and then rank them by the rating scores in the greedy manner. In the permutation prospective, however, current RS come to reveal the following two limitations: 1) They neglect addressing the permutation-variant influence within the recommended results; 2) Permutation consideration extends the latent solution space exponentially, and current RS lack the ability to evaluate the permutations. Both drive RS away from the permutation-optimal recommended results and better user experience. To approximate the permutation-optimal recommended results effectively and efficiently, we propose a novel permutation-wise framework PRS in the re-ranking stage of RS, which consists of Permutation-Matching (PMatch) and Permutation-Ranking (PRank) stages successively. Specifically, the PMatch stage is designed to obtain the candidate list set, where we propose the FPSA algorithm to generate multiple candidate lists via the permutation-wise and goal-oriented beam search algorithm. Afterwards, for the candidate list set, the PRank stage provides a unified permutation-wise ranking criterion named LR metric, which is calculated by the rating scores of elaborately designed permutation-wise model DPWN. Finally, the list with the highest LR score is recommended to the user. Empirical results show that PRS consistently and significantly outperforms state-of-the-art methods. Moreover, PRS has achieved a performance improvement of 11.0% on PV metric and 8.7% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.
Personalized Adaptive Meta Learning for Cold-start User Preference Prediction
Dec 22, 2020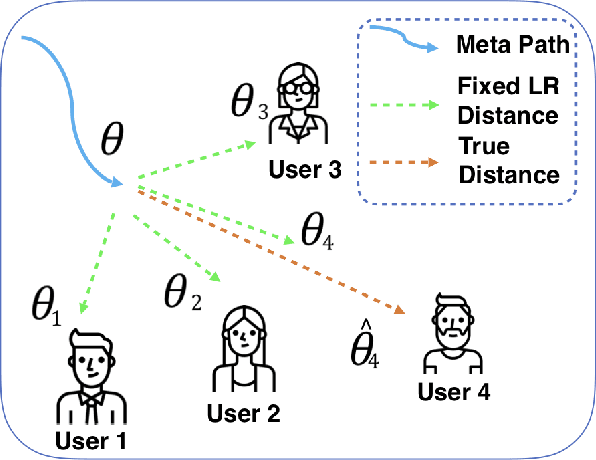
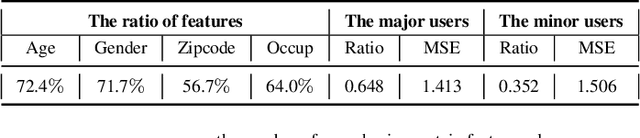
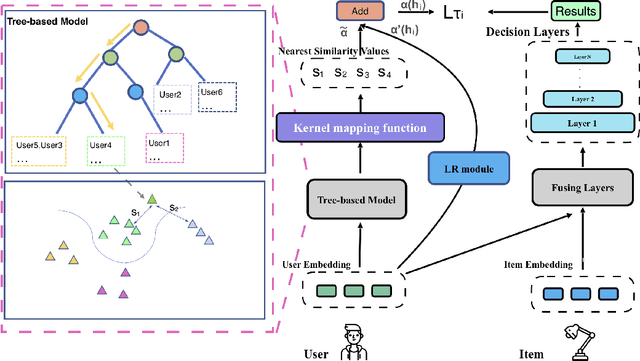

A common challenge in personalized user preference prediction is the cold-start problem. Due to the lack of user-item interactions, directly learning from the new users' log data causes serious over-fitting problem. Recently, many existing studies regard the cold-start personalized preference prediction as a few-shot learning problem, where each user is the task and recommended items are the classes, and the gradient-based meta learning method (MAML) is leveraged to address this challenge. However, in real-world application, the users are not uniformly distributed (i.e., different users may have different browsing history, recommended items, and user profiles. We define the major users as the users in the groups with large numbers of users sharing similar user information, and other users are the minor users), existing MAML approaches tend to fit the major users and ignore the minor users. To address this cold-start task-overfitting problem, we propose a novel personalized adaptive meta learning approach to consider both the major and the minor users with three key contributions: 1) We are the first to present a personalized adaptive learning rate meta-learning approach to improve the performance of MAML by focusing on both the major and minor users. 2) To provide better personalized learning rates for each user, we introduce a similarity-based method to find similar users as a reference and a tree-based method to store users' features for fast search. 3) To reduce the memory usage, we design a memory agnostic regularizer to further reduce the space complexity to constant while maintain the performance. Experiments on MovieLens, BookCrossing, and real-world production datasets reveal that our method outperforms the state-of-the-art methods dramatically for both the minor and major users.
Multi-task MR Imaging with Iterative Teacher Forcing and Re-weighted Deep Learning
Nov 27, 2020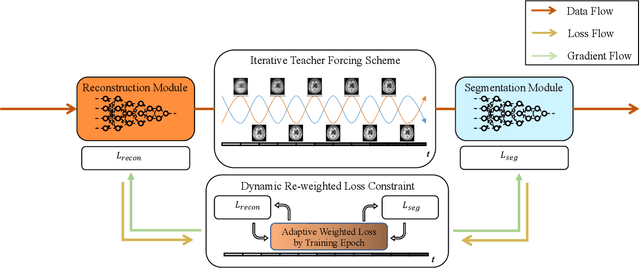

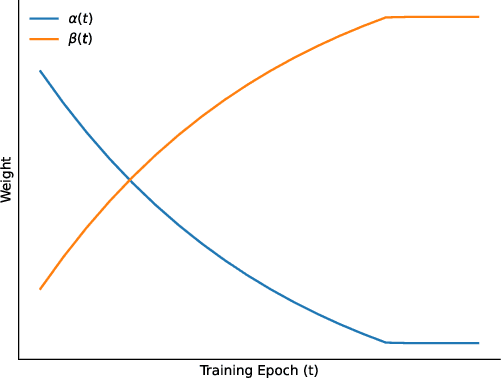
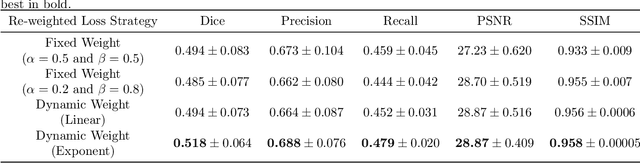
Noises, artifacts, and loss of information caused by the magnetic resonance (MR) reconstruction may compromise the final performance of the downstream applications. In this paper, we develop a re-weighted multi-task deep learning method to learn prior knowledge from the existing big dataset and then utilize them to assist simultaneous MR reconstruction and segmentation from the under-sampled k-space data. The multi-task deep learning framework is equipped with two network sub-modules, which are integrated and trained by our designed iterative teacher forcing scheme (ITFS) under the dynamic re-weighted loss constraint (DRLC). The ITFS is designed to avoid error accumulation by injecting the fully-sampled data into the training process. The DRLC is proposed to dynamically balance the contributions from the reconstruction and segmentation sub-modules so as to co-prompt the multi-task accuracy. The proposed method has been evaluated on two open datasets and one in vivo in-house dataset and compared to six state-of-the-art methods. Results show that the proposed method possesses encouraging capabilities for simultaneous and accurate MR reconstruction and segmentation.
Distant Supervision for E-commerce Query Segmentation via Attention Network
Nov 09, 2020
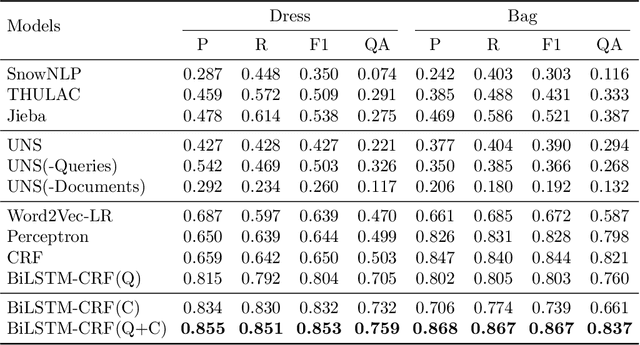
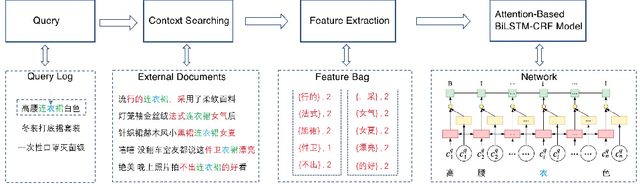
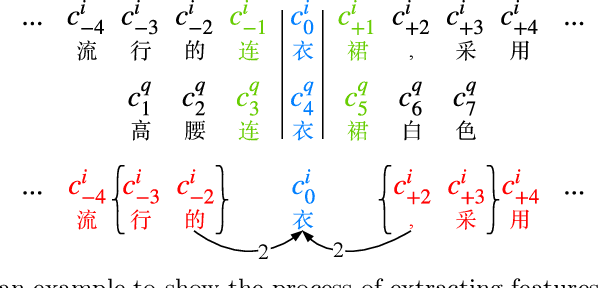
The booming online e-commerce platforms demand highly accurate approaches to segment queries that carry the product requirements of consumers. Recent works have shown that the supervised methods, especially those based on deep learning, are attractive for achieving better performance on the problem of query segmentation. However, the lack of labeled data is still a big challenge for training a deep segmentation network, and the problem of Out-of-Vocabulary (OOV) also adversely impacts the performance of query segmentation. Different from query segmentation task in an open domain, e-commerce scenario can provide external documents that are closely related to these queries. Thus, to deal with the two challenges, we employ the idea of distant supervision and design a novel method to find contexts in external documents and extract features from these contexts. In this work, we propose a BiLSTM-CRF based model with an attention module to encode external features, such that external contexts information, which can be utilized naturally and effectively to help query segmentation. Experiments on two datasets show the effectiveness of our approach compared with several kinds of baselines.
Balanced Order Batching with Task-Oriented Graph Clustering
Aug 19, 2020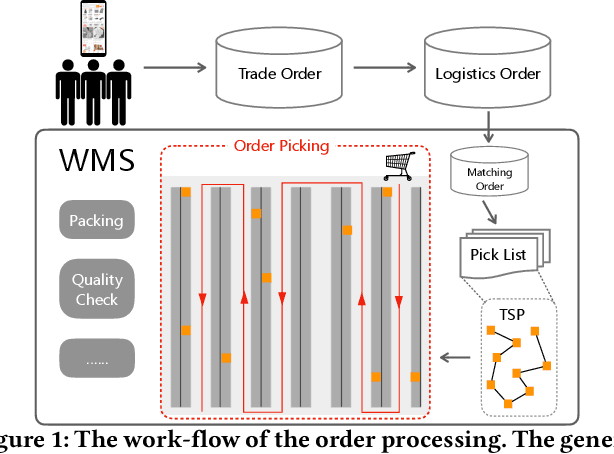
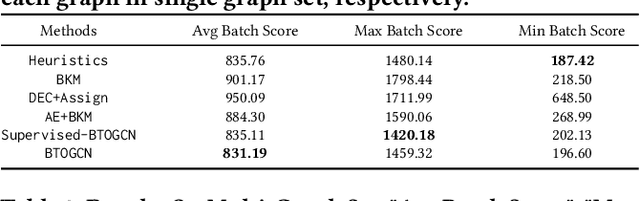
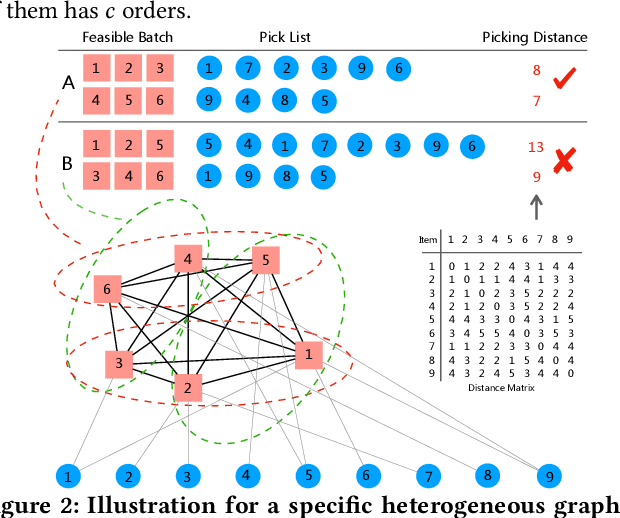
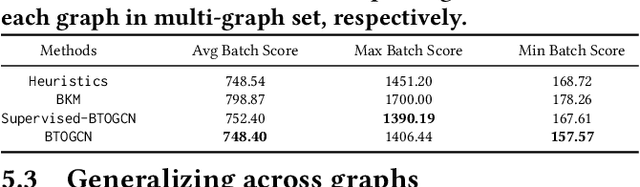
Balanced order batching problem (BOBP) arises from the process of warehouse picking in Cainiao, the largest logistics platform in China. Batching orders together in the picking process to form a single picking route, reduces travel distance. The reason for its importance is that order picking is a labor intensive process and, by using good batching methods, substantial savings can be obtained. The BOBP is a NP-hard combinational optimization problem and designing a good problem-specific heuristic under the quasi-real-time system response requirement is non-trivial. In this paper, rather than designing heuristics, we propose an end-to-end learning and optimization framework named Balanced Task-orientated Graph Clustering Network (BTOGCN) to solve the BOBP by reducing it to balanced graph clustering optimization problem. In BTOGCN, a task-oriented estimator network is introduced to guide the type-aware heterogeneous graph clustering networks to find a better clustering result related to the BOBP objective. Through comprehensive experiments on single-graph and multi-graphs, we show: 1) our balanced task-oriented graph clustering network can directly utilize the guidance of target signal and outperforms the two-stage deep embedding and deep clustering method; 2) our method obtains an average 4.57m and 0.13m picking distance ("m" is the abbreviation of the meter (the SI base unit of length)) reduction than the expert-designed algorithm on single and multi-graph set and has a good generalization ability to apply in practical scenario.