 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAST SToP For Modeling Asynchronous Time Series
Feb 04, 2025



We present a novel prompt design for Large Language Models (LLMs) tailored to Asynchronous Time Series. Unlike regular time series, which assume values at evenly spaced time points, asynchronous time series consist of timestamped events occurring at irregular intervals, each described in natural language. Our approach effectively utilizes the rich natural language of event descriptions, allowing LLMs to benefit from their broad world knowledge for reasoning across different domains and tasks. This allows us to extend the scope of asynchronous time series analysis beyond forecasting to include tasks like anomaly detection and data imputation. We further introduce Stochastic Soft Prompting, a novel prompt-tuning mechanism that significantly improves model performance, outperforming existing fine-tuning methods such as QLoRA. Through extensive experiments on real world datasets, we demonstrate that our approach achieves state-of-the-art performance across different tasks and datasets.
Training a Vision Transformer from scratch in less than 24 hours with 1 GPU
Nov 09, 2022


Transformers have become central to recent advances in computer vision. However, training a vision Transformer (ViT) model from scratch can be resource intensive and time consuming. In this paper, we aim to explore approaches to reduce the training costs of ViT models. We introduce some algorithmic improvements to enable training a ViT model from scratch with limited hardware (1 GPU) and time (24 hours) resources. First, we propose an efficient approach to add locality to the ViT architecture. Second, we develop a new image size curriculum learning strategy, which allows to reduce the number of patches extracted from each image at the beginning of the training. Finally, we propose a new variant of the popular ImageNet1k benchmark by adding hardware and time constraints. We evaluate our contributions on this benchmark, and show they can significantly improve performances given the proposed training budget. We will share the code in https://github.com/BorealisAI/efficient-vit-training.
Variational Selective Autoencoder: Learning from Partially-Observed Heterogeneous Data
Feb 25, 2021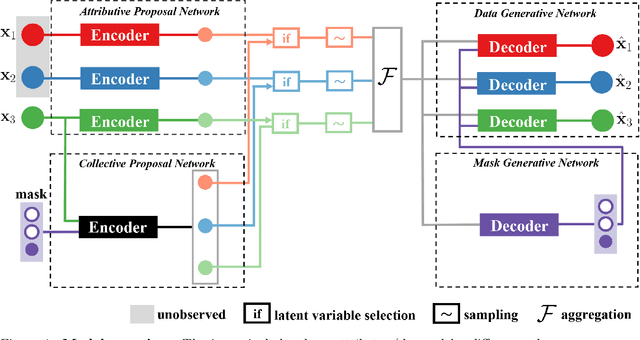
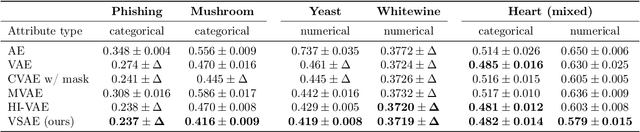
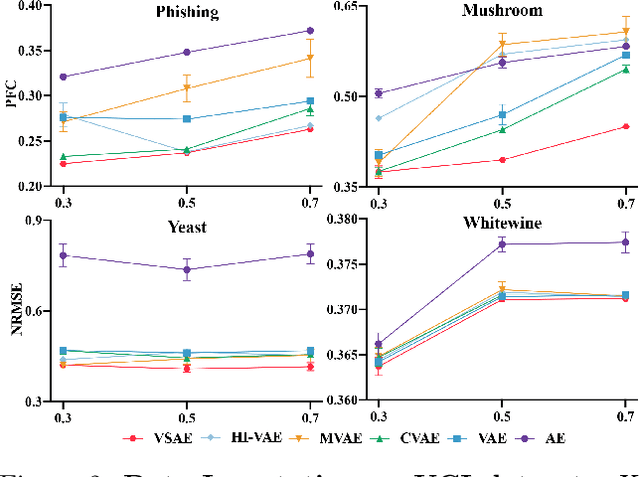
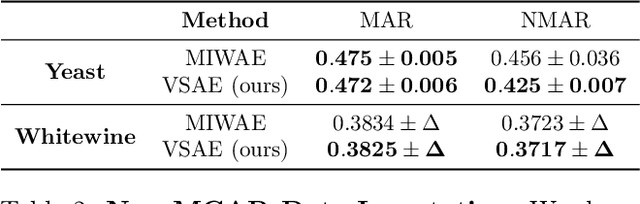
Learning from heterogeneous data poses challenges such as combining data from various sources and of different types. Meanwhile, heterogeneous data are often associated with missingness in real-world applications due to heterogeneity and noise of input sources. In this work, we propose the variational selective autoencoder (VSAE), a general framework to learn representations from partially-observed heterogeneous data. VSAE learns the latent dependencies in heterogeneous data by modeling the joint distribution of observed data, unobserved data, and the imputation mask which represents how the data are missing. It results in a unified model for various downstream tasks including data generation and imputation. Evaluation on both low-dimensional and high-dimensional heterogeneous datasets for these two tasks shows improvement over state-of-the-art models.
Point Process Flows
Oct 31, 2019
Event sequences can be modeled by temporal point processes (TPPs) to capture their asynchronous and probabilistic nature. We propose an intensity-free framework that directly models the point process distribution by utilizing normalizing flows. This approach is capable of capturing highly complex temporal distributions and does not rely on restrictive parametric forms. Comparisons with state-of-the-art baseline models on both synthetic and challenging real-life datasets show that the proposed framework is effective at modeling the stochasticity of discrete event sequences.
LayoutVAE: Stochastic Scene Layout Generation From a Label Set
Aug 13, 2019
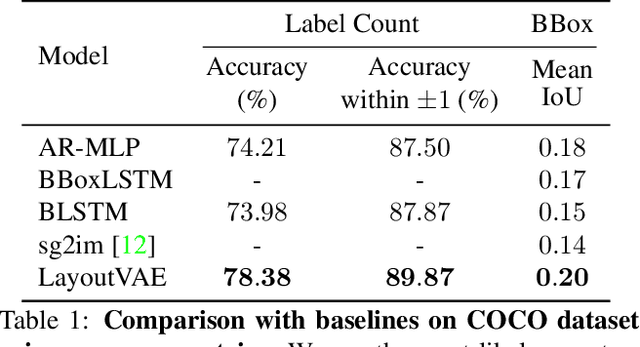
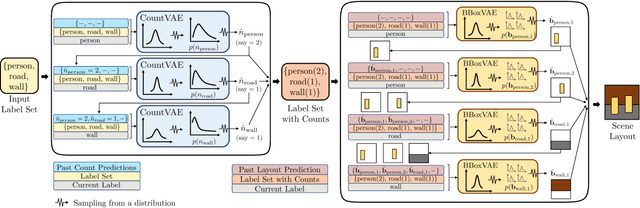
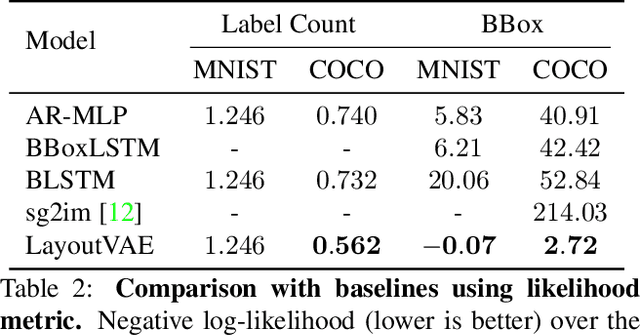
Recently there is an increasing interest in scene generation within the research community. However, models used for generating scene layouts from textual description largely ignore plausible visual variations within the structure dictated by the text. We propose LayoutVAE, a variational autoencoder based framework for generating stochastic scene layouts. LayoutVAE is a versatile modeling framework that allows for generating full image layouts given a label set, or per label layouts for an existing image given a new label. In addition, it is also capable of detecting unusual layouts, potentially providing a way to evaluate layout generation problem. Extensive experiments on MNIST-Layouts and challenging COCO 2017 Panoptic dataset verifies the effectiveness of our proposed framework.
A Variational Auto-Encoder Model for Stochastic Point Processes
Apr 05, 2019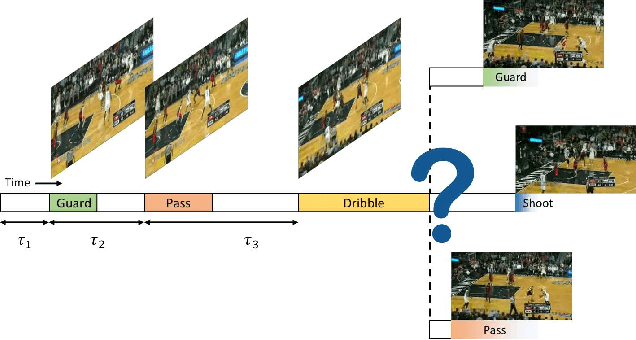

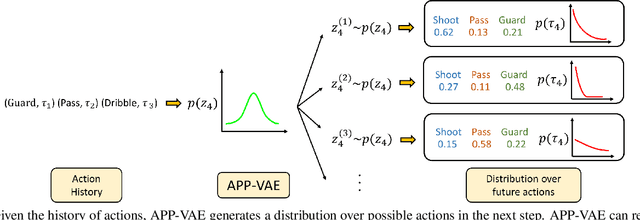
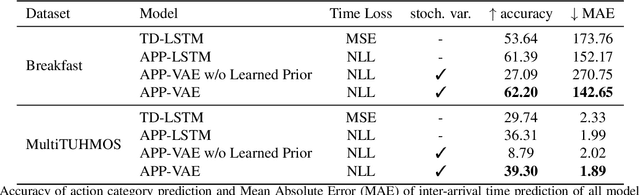
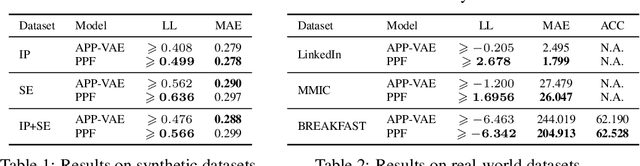
We propose a novel probabilistic generative model for action sequences. The model is termed the Action Point Process VAE (APP-VAE), a variational auto-encoder that can capture the distribution over the times and categories of action sequences. Modeling the variety of possible action sequences is a challenge, which we show can be addressed via the APP-VAE's use of latent representations and non-linear functions to parameterize distributions over which event is likely to occur next in a sequence and at what time. We empirically validate the efficacy of APP-VAE for modeling action sequences on the MultiTHUMOS and Breakfast datasets.
Learning a Deep ConvNet for Multi-label Classification with Partial Labels
Feb 26, 2019
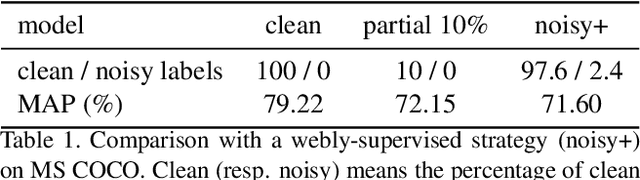
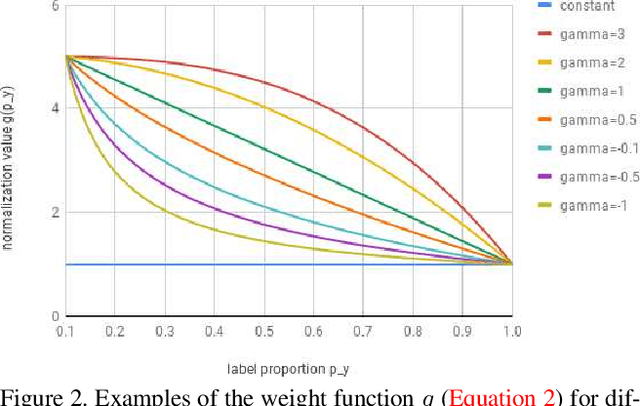
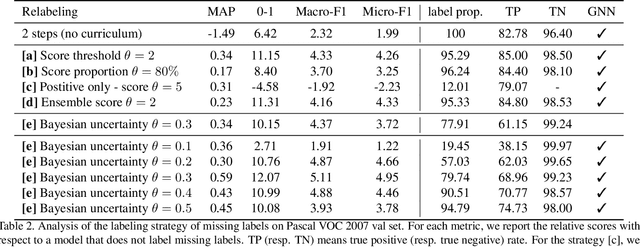
Deep ConvNets have shown great performance for single-label image classification (e.g. ImageNet), but it is necessary to move beyond the single-label classification task because pictures of everyday life are inherently multi-label. Multi-label classification is a more difficult task than single-label classification because both the input images and output label spaces are more complex. Furthermore, collecting clean multi-label annotations is more difficult to scale-up than single-label annotations. To reduce the annotation cost, we propose to train a model with partial labels i.e. only some labels are known per image. We first empirically compare different labeling strategies to show the potential for using partial labels on multi-label datasets. Then to learn with partial labels, we introduce a new classification loss that exploits the proportion of known labels per example. Our approach allows the use of the same training settings as when learning with all the annotations. We further explore several curriculum learning based strategies to predict missing labels. Experiments are performed on three large-scale multi-label datasets: MS COCO, NUS-WIDE and Open Images.