 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Optimal Choice for Generative Processes in Diffusion Models: Ordinary vs Stochastic Differential Equations
Jun 03, 2023The diffusion model has shown remarkable success in computer vision, but it remains unclear whether ODE-based probability flow or SDE-based diffusion models are superior and under what circumstances. Comparing the two is challenging due to dependencies on data distribution, score training, and other numerical factors. In this paper, we examine the problem mathematically by examining two limiting scenarios: the ODE case and the large diffusion case. We first introduce a pulse-shape error to perturb the score function and analyze error accumulation, with a generalization to arbitrary error. Our findings indicate that when the perturbation occurs at the end of the generative process, the ODE model outperforms the SDE model (with a large diffusion coefficient). However, when the perturbation occurs earlier, the SDE model outperforms the ODE model, and we demonstrate that the error of sample generation due to pulse-shape error can be exponentially suppressed as the diffusion term's magnitude increases to infinity. Numerical validation of this phenomenon is provided using toy models such as Gaussian, Gaussian mixture models, and Swiss roll. Finally, we experiment with MNIST and observe that varying the diffusion coefficient can improve sample quality even when the score function is not well trained.
DETR-based Layered Clothing Segmentation and Fine-Grained Attribute Recognition
Apr 17, 2023



Clothing segmentation and fine-grained attribute recognition are challenging tasks at the crossing of computer vision and fashion, which segment the entire ensemble clothing instances as well as recognize detailed attributes of the clothing products from any input human images. Many new models have been developed for the tasks in recent years, nevertheless the segmentation accuracy is less than satisfactory in case of layered clothing or fashion products in different scales. In this paper, a new DEtection TRansformer (DETR) based method is proposed to segment and recognize fine-grained attributes of ensemble clothing instances with high accuracy. In this model, we propose a \textbf{multi-layered attention module} by aggregating features of different scales, determining the various scale components of a single instance, and merging them together. We train our model on the Fashionpedia dataset and demonstrate our method surpasses SOTA models in tasks of layered clothing segmentation and fine-grained attribute recognition.
AnimeDiffusion: Anime Face Line Drawing Colorization via Diffusion Models
Mar 20, 2023It is a time-consuming and tedious work for manually colorizing anime line drawing images, which is an essential stage in cartoon animation creation pipeline. Reference-based line drawing colorization is a challenging task that relies on the precise cross-domain long-range dependency modelling between the line drawing and reference image. Existing learning methods still utilize generative adversarial networks (GANs) as one key module of their model architecture. In this paper, we propose a novel method called AnimeDiffusion using diffusion models that performs anime face line drawing colorization automatically. To the best of our knowledge, this is the first diffusion model tailored for anime content creation. In order to solve the huge training consumption problem of diffusion models, we design a hybrid training strategy, first pre-training a diffusion model with classifier-free guidance and then fine-tuning it with image reconstruction guidance. We find that with a few iterations of fine-tuning, the model shows wonderful colorization performance, as illustrated in Fig. 1. For training AnimeDiffusion, we conduct an anime face line drawing colorization benchmark dataset, which contains 31696 training data and 579 testing data. We hope this dataset can fill the gap of no available high resolution anime face dataset for colorization method evaluation. Through multiple quantitative metrics evaluated on our dataset and a user study, we demonstrate AnimeDiffusion outperforms state-of-the-art GANs-based models for anime face line drawing colorization. We also collaborate with professional artists to test and apply our AnimeDiffusion for their creation work. We release our code on https://github.com/xq-meng/AnimeDiffusion.
Attention-Aware Anime Line Drawing Colorization
Jan 05, 2023Automatic colorization of anime line drawing has attracted much attention in recent years since it can substantially benefit the animation industry. User-hint based methods are the mainstream approach for line drawing colorization, while reference-based methods offer a more intuitive approach. Nevertheless, although reference-based methods can improve feature aggregation of the reference image and the line drawing, the colorization results are not compelling in terms of color consistency or semantic correspondence. In this paper, we introduce an attention-based model for anime line drawing colorization, in which a channel-wise and spatial-wise Convolutional Attention module is used to improve the ability of the encoder for feature extraction and key area perception, and a Stop-Gradient Attention module with cross-attention and self-attention is used to tackle the cross-domain long-range dependency problem. Extensive experiments show that our method outperforms other SOTA methods, with more accurate line structure and semantic color information.
TASA: Deceiving Question Answering Models by Twin Answer Sentences Attack
Oct 27, 2022We present Twin Answer Sentences Attack (TASA), an adversarial attack method for question answering (QA) models that produces fluent and grammatical adversarial contexts while maintaining gold answers. Despite phenomenal progress on general adversarial attacks, few works have investigated the vulnerability and attack specifically for QA models. In this work, we first explore the biases in the existing models and discover that they mainly rely on keyword matching between the question and context, and ignore the relevant contextual relations for answer prediction. Based on two biases above, TASA attacks the target model in two folds: (1) lowering the model's confidence on the gold answer with a perturbed answer sentence; (2) misguiding the model towards a wrong answer with a distracting answer sentence. Equipped with designed beam search and filtering methods, TASA can generate more effective attacks than existing textual attack methods while sustaining the quality of contexts, in extensive experiments on five QA datasets and human evaluations.
SpikeSim: An end-to-end Compute-in-Memory Hardware Evaluation Tool for Benchmarking Spiking Neural Networks
Oct 24, 2022SNNs are an active research domain towards energy efficient machine intelligence. Compared to conventional ANNs, SNNs use temporal spike data and bio-plausible neuronal activation functions such as Leaky-Integrate Fire/Integrate Fire (LIF/IF) for data processing. However, SNNs incur significant dot-product operations causing high memory and computation overhead in standard von-Neumann computing platforms. Today, In-Memory Computing (IMC) architectures have been proposed to alleviate the "memory-wall bottleneck" prevalent in von-Neumann architectures. Although recent works have proposed IMC-based SNN hardware accelerators, the following have been overlooked- 1) the adverse effects of crossbar non-ideality on SNN performance due to repeated analog dot-product operations over multiple time-steps, 2) hardware overheads of essential SNN-specific components such as the LIF/IF and data communication modules. To this end, we propose SpikeSim, a tool that can perform realistic performance, energy, latency and area evaluation of IMC-mapped SNNs. SpikeSim consists of a practical monolithic IMC architecture called SpikeFlow for mapping SNNs. Additionally, the non-ideality computation engine (NICE) and energy-latency-area (ELA) engine performs hardware-realistic evaluation of SpikeFlow-mapped SNNs. Based on 65nm CMOS implementation and experiments on CIFAR10, CIFAR100 and TinyImagenet datasets, we find that the LIF/IF neuronal module has significant area contribution (>11% of the total hardware area). We propose SNN topological modifications leading to 1.24x and 10x reduction in the neuronal module's area and the overall energy-delay-product value, respectively. Furthermore, in this work, we perform a holistic comparison between IMC implemented ANN and SNNs and conclude that lower number of time-steps are the key to achieve higher throughput and energy-efficiency for SNNs compared to 4-bit ANNs.
On the Complementarity between Pre-Training and Random-Initialization for Resource-Rich Machine Translation
Sep 15, 2022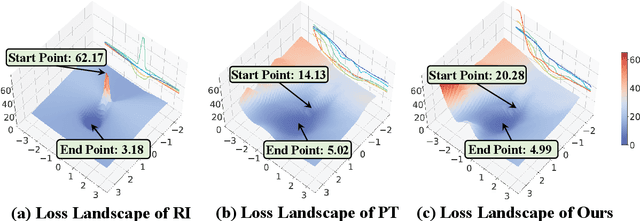
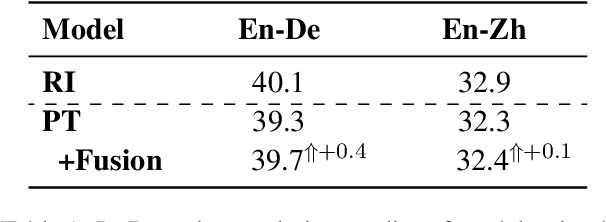
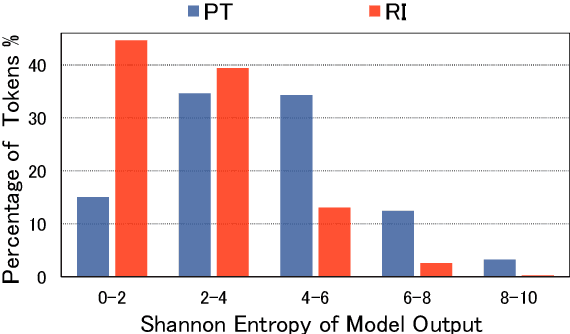
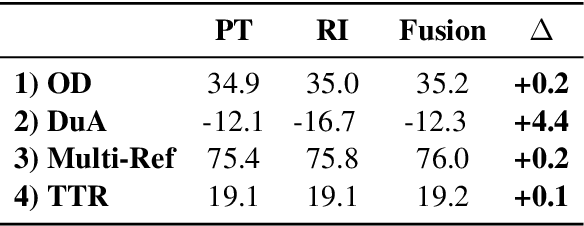
Pre-Training (PT) of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains (sometimes, even worse) on resource-rich NMT on par with its Random-Initialization (RI) counterpart. We take the first step to investigate the complementarity between PT and RI in resource-rich scenarios via two probing analyses, and find that: 1) PT improves NOT the accuracy, but the generalization by achieving flatter loss landscapes than that of RI; 2) PT improves NOT the confidence of lexical choice, but the negative diversity by assigning smoother lexical probability distributions than that of RI. Based on these insights, we propose to combine their complementarities with a model fusion algorithm that utilizes optimal transport to align neurons between PT and RI. Experiments on two resource-rich translation benchmarks, WMT'17 English-Chinese (20M) and WMT'19 English-German (36M), show that PT and RI could be nicely complementary to each other, achieving substantial improvements considering both translation accuracy, generalization, and negative diversity. Probing tools and code are released at: https://github.com/zanchangtong/PTvsRI.
FEC: Fast Euclidean Clustering for Point Cloud Segmentation
Aug 16, 2022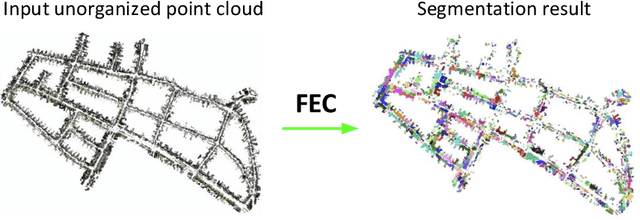

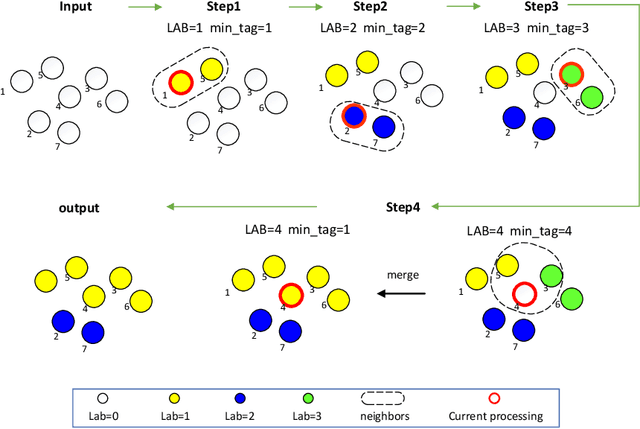
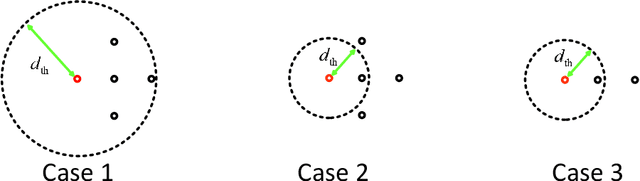
Segmentation from point cloud data is essential in many applications such as remote sensing, mobile robots, or autonomous cars. However, the point clouds captured by the 3D range sensor are commonly sparse and unstructured, challenging efficient segmentation. In this paper, we present a fast solution to point cloud instance segmentation with small computational demands. To this end, we propose a novel fast Euclidean clustering (FEC) algorithm which applies a pointwise scheme over the clusterwise scheme used in existing works. Our approach is conceptually simple, easy to implement (40 lines in C++), and achieves two orders of magnitudes faster against the classical segmentation methods while producing high-quality results.
DeePKS+ABACUS as a Bridge between Expensive Quantum Mechanical Models and Machine Learning Potentials
Jun 21, 2022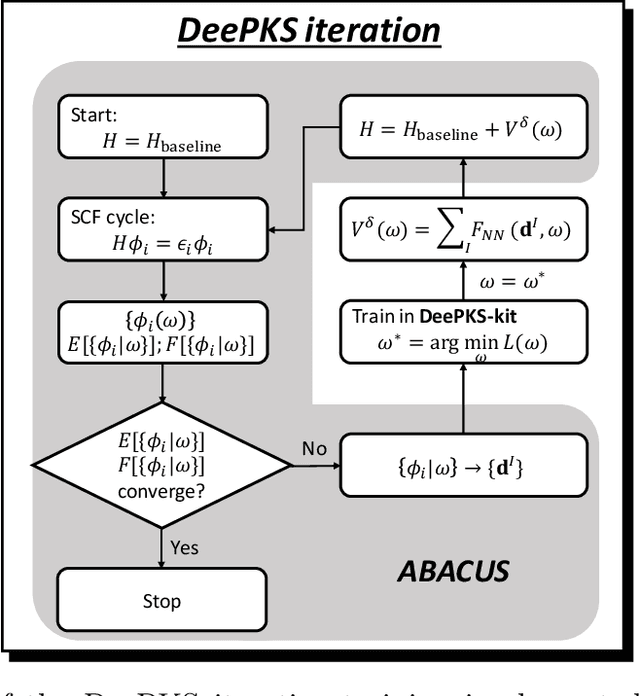
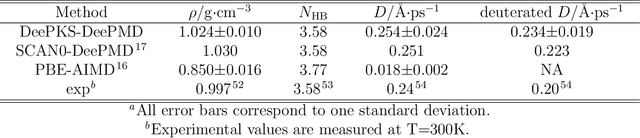
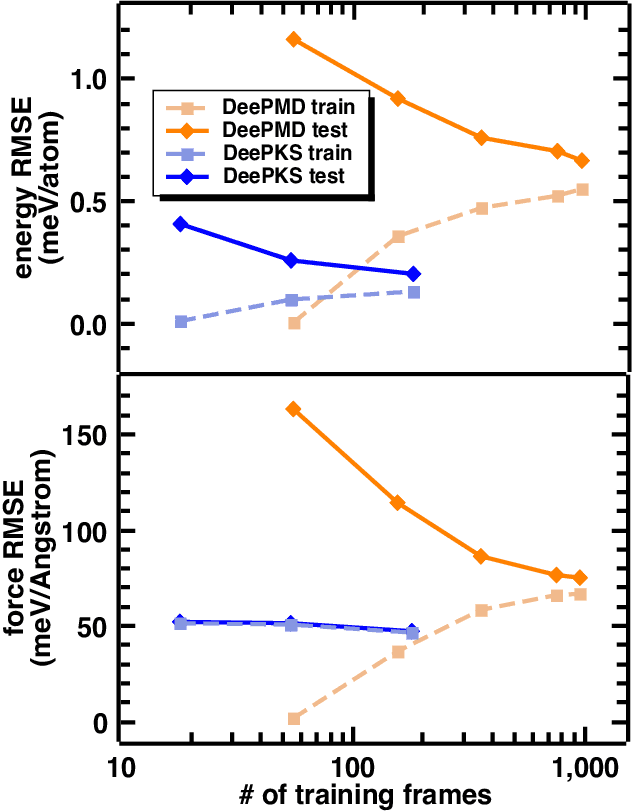
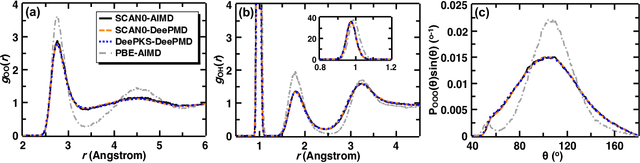
Recently, the development of machine learning (ML) potentials has made it possible to perform large-scale and long-time molecular simulations with the accuracy of quantum mechanical (QM) models. However, for high-level QM methods, such as density functional theory (DFT) at the meta-GGA level and/or with exact exchange, quantum Monte Carlo, etc., generating a sufficient amount of data for training a ML potential has remained computationally challenging due to their high cost. In this work, we demonstrate that this issue can be largely alleviated with Deep Kohn-Sham (DeePKS), a ML-based DFT model. DeePKS employs a computationally efficient neural network-based functional model to construct a correction term added upon a cheap DFT model. Upon training, DeePKS offers closely-matched energies and forces compared with high-level QM method, but the number of training data required is orders of magnitude less than that required for training a reliable ML potential. As such, DeePKS can serve as a bridge between expensive QM models and ML potentials: one can generate a decent amount of high-accuracy QM data to train a DeePKS model, and then use the DeePKS model to label a much larger amount of configurations to train a ML potential. This scheme for periodic systems is implemented in a DFT package ABACUS, which is open-source and ready for use in various applications.
Learning Optimal Flows for Non-Equilibrium Importance Sampling
Jun 20, 2022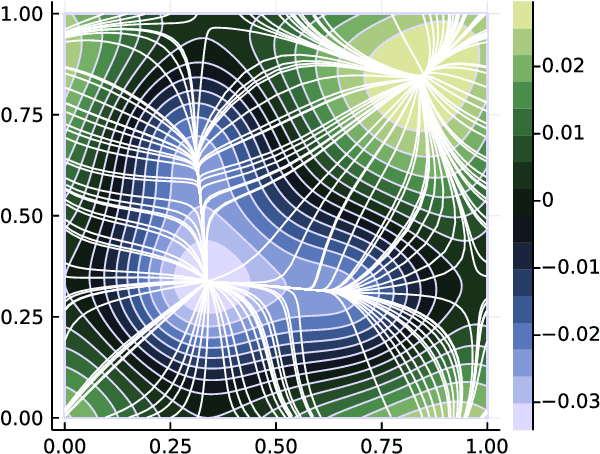

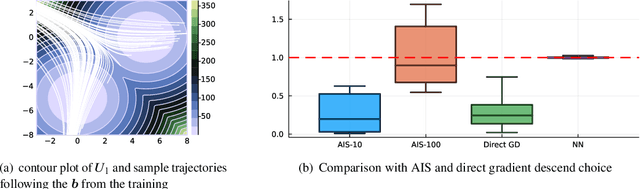
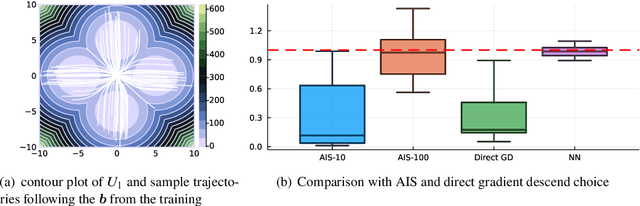
Many applications in computational sciences and statistical inference require the computation of expectations with respect to complex high-dimensional distributions with unknown normalization constants, as well as the estimation of these constants. Here we develop a method to perform these calculations based on generating samples from a simple base distribution, transporting them along the flow generated by a velocity field, and performing averages along these flowlines. This non-equilibrium importance sampling (NEIS) strategy is straightforward to implement, and can be used for calculations with arbitrary target distributions. On the theory side we discuss how to tailor the velocity field to the target and establish general conditions under which the proposed estimator is a perfect estimator, with zero-variance. We also draw connections between NEIS and approaches based on mapping a base distribution onto a target via a transport map. On the computational side we show how to use deep learning to represent the velocity field by a neural network and train it towards the zero variance optimum. These results are illustrated numerically on high dimensional examples, where we show that training the velocity field can decrease the variance of the NEIS estimator by up to 6 order of magnitude compared to a vanilla estimator. We also show that NEIS performs better on these examples than Neal's annealed importance sampling (AIS).