 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
Dec 20, 2025Real-world software engineering tasks require coding agents that can operate over massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK integrates a unified orchestrator with hierarchical working memory for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the synthesis, evaluation, and refinement of agent configurations through a build-test-improve loop, enabling rapid adaptation to new tasks, environments, and tool stacks. Instantiated with these mechanisms, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results, under identical repositories, model backends, and tool access.
Extending Context Window of Large Language Models via Positional Interpolation
Jun 28, 2023



We present Position Interpolation (PI) that extends the context window sizes of RoPE-based pretrained LLMs such as LLaMA models to up to 32768 with minimal fine-tuning (within 1000 steps), while demonstrating strong empirical results on various tasks that require long context, including passkey retrieval, language modeling, and long document summarization from LLaMA 7B to 65B. Meanwhile, the extended model by Position Interpolation preserve quality relatively well on tasks within its original context window. To achieve this goal, Position Interpolation linearly down-scales the input position indices to match the original context window size, rather than extrapolating beyond the trained context length which may lead to catastrophically high attention scores that completely ruin the self-attention mechanism. Our theoretical study shows that the upper bound of interpolation is at least $\sim 600 \times$ smaller than that of extrapolation, further demonstrating its stability. Models extended via Position Interpolation retain its original architecture and can reuse most pre-existing optimization and infrastructure.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021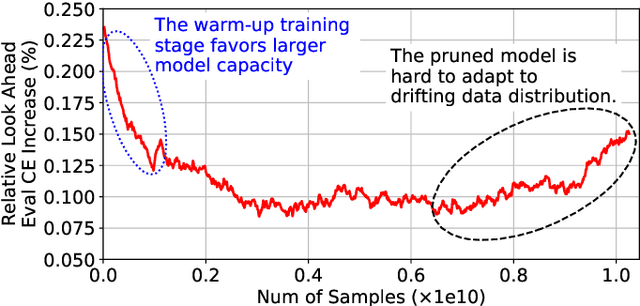

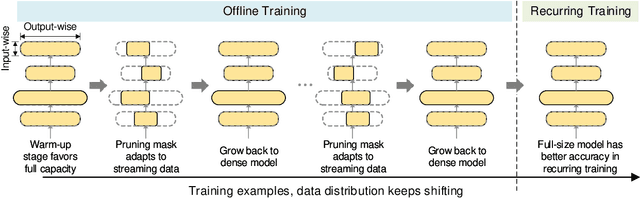

Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.