 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
May 27, 2025



Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
Skrr: Skip and Re-use Text Encoder Layers for Memory Efficient Text-to-Image Generation
Feb 12, 2025



Large-scale text encoders in text-to-image (T2I) diffusion models have demonstrated exceptional performance in generating high-quality images from textual prompts. Unlike denoising modules that rely on multiple iterative steps, text encoders require only a single forward pass to produce text embeddings. However, despite their minimal contribution to total inference time and floating-point operations (FLOPs), text encoders demand significantly higher memory usage, up to eight times more than denoising modules. To address this inefficiency, we propose Skip and Re-use layers (Skrr), a simple yet effective pruning strategy specifically designed for text encoders in T2I diffusion models. Skrr exploits the inherent redundancy in transformer blocks by selectively skipping or reusing certain layers in a manner tailored for T2I tasks, thereby reducing memory consumption without compromising performance. Extensive experiments demonstrate that Skrr maintains image quality comparable to the original model even under high sparsity levels, outperforming existing blockwise pruning methods. Furthermore, Skrr achieves state-of-the-art memory efficiency while preserving performance across multiple evaluation metrics, including the FID, CLIP, DreamSim, and GenEval scores.
Context-Aware Token Selection and Packing for Enhanced Vision Transformer
Oct 31, 2024



In recent years, the long-range attention mechanism of vision transformers has driven significant performance breakthroughs across various computer vision tasks. However, the traditional self-attention mechanism, which processes both informative and non-informative tokens, suffers from inefficiency and inaccuracies. While sparse attention mechanisms have been introduced to mitigate these issues by pruning tokens involved in attention, they often lack context-awareness and intelligence. These mechanisms frequently apply a uniform token selection strategy across different inputs for batch training or optimize efficiency only for the inference stage. To overcome these challenges, we propose a novel algorithm: Select and Pack Attention (SPA). SPA dynamically selects informative tokens using a low-cost gating layer supervised by selection labels and packs these tokens into new batches, enabling a variable number of tokens to be used in parallelized GPU batch training and inference. Extensive experiments across diverse datasets and computer vision tasks demonstrate that SPA delivers superior performance and efficiency, including a 0.6 mAP improvement in object detection and a 16.4% reduction in computational costs.
BBS: Bi-directional Bit-level Sparsity for Deep Learning Acceleration
Sep 08, 2024



Bit-level sparsity methods skip ineffectual zero-bit operations and are typically applicable within bit-serial deep learning accelerators. This type of sparsity at the bit-level is especially interesting because it is both orthogonal and compatible with other deep neural network (DNN) efficiency methods such as quantization and pruning. In this work, we improve the practicality and efficiency of bitlevel sparsity through a novel algorithmic bit-pruning, averaging, and compression method, and a co-designed efficient bit-serial hardware accelerator. On the algorithmic side, we introduce bidirectional bit sparsity (BBS). The key insight of BBS is that we can leverage bit sparsity in a symmetrical way to prune either zero-bits or one-bits. This significantly improves the load balance of bit-serial computing and guarantees the level of sparsity to be more than 50%. On top of BBS, we further propose two bit-level binary pruning methods that require no retraining, and can be seamlessly applied to quantized DNNs. Combining binary pruning with a new tensor encoding scheme, BBS can both skip computation and reduce the memory footprint associated with bi-directional sparse bit columns. On the hardware side, we demonstrate the potential of BBS through BitVert, a bitserial architecture with an efficient PE design to accelerate DNNs with low overhead, exploiting our proposed binary pruning. Evaluation on seven representative DNN models shows that our approach achieves: (1) on average 1.66$\times$ reduction in model sizewith negligible accuracy loss of < 0.5%; (2) up to 3.03$\times$ speedupand 2.44$\times$ energy saving compared to prior DNN accelerators.
Torch2Chip: An End-to-end Customizable Deep Neural Network Compression and Deployment Toolkit for Prototype Hardware Accelerator Design
May 06, 2024



The development of model compression is continuously motivated by the evolution of various neural network accelerators with ASIC or FPGA. On the algorithm side, the ultimate goal of quantization or pruning is accelerating the expensive DNN computations on low-power hardware. However, such a "design-and-deploy" workflow faces under-explored challenges in the current hardware-algorithm co-design community. First, although the state-of-the-art quantization algorithm can achieve low precision with negligible degradation of accuracy, the latest deep learning framework (e.g., PyTorch) can only support non-customizable 8-bit precision, data format, and parameter extraction. Secondly, the objective of quantization is to enable the computation with low-precision data. However, the current SoTA algorithm treats the quantized integer as an intermediate result, while the final output of the quantizer is the "discretized" floating-point values, ignoring the practical needs and adding additional workload to hardware designers for integer parameter extraction and layer fusion. Finally, the compression toolkits designed by the industry are constrained to their in-house product or a handful of algorithms. The limited degree of freedom in the current toolkit and the under-explored customization hinder the prototype ASIC or FPGA-based accelerator design. To resolve these challenges, we propose Torch2Chip, an open-sourced, fully customizable, and high-performance toolkit that supports user-designed compression followed by automatic model fusion and parameter extraction. Torch2Chip incorporates the hierarchical design workflow, and the user-customized compression algorithm will be directly packed into the deployment-ready format for prototype chip verification with either CNN or vision transformer (ViT). The code is available at https://github.com/SeoLabCornell/torch2chip.
Transformer-based Selective Super-Resolution for Efficient Image Refinement
Dec 10, 2023



Conventional super-resolution methods suffer from two drawbacks: substantial computational cost in upscaling an entire large image, and the introduction of extraneous or potentially detrimental information for downstream computer vision tasks during the refinement of the background. To solve these issues, we propose a novel transformer-based algorithm, Selective Super-Resolution (SSR), which partitions images into non-overlapping tiles, selects tiles of interest at various scales with a pyramid architecture, and exclusively reconstructs these selected tiles with deep features. Experimental results on three datasets demonstrate the efficiency and robust performance of our approach for super-resolution. Compared to the state-of-the-art methods, the FID score is reduced from 26.78 to 10.41 with 40% reduction in computation cost for the BDD100K dataset. The source code is available at https://github.com/destiny301/SSR.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
SIAM: Chiplet-based Scalable In-Memory Acceleration with Mesh for Deep Neural Networks
Aug 14, 2021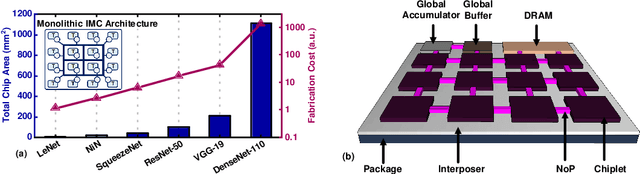
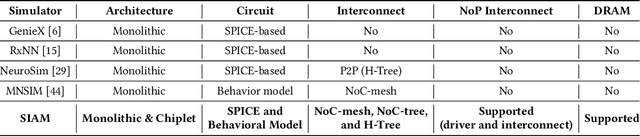
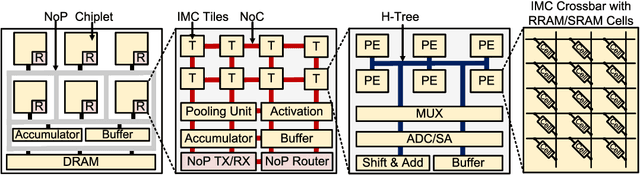
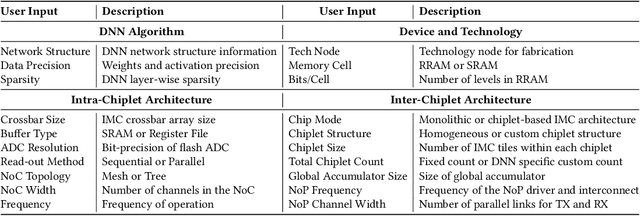
In-memory computing (IMC) on a monolithic chip for deep learning faces dramatic challenges on area, yield, and on-chip interconnection cost due to the ever-increasing model sizes. 2.5D integration or chiplet-based architectures interconnect multiple small chips (i.e., chiplets) to form a large computing system, presenting a feasible solution beyond a monolithic IMC architecture to accelerate large deep learning models. This paper presents a new benchmarking simulator, SIAM, to evaluate the performance of chiplet-based IMC architectures and explore the potential of such a paradigm shift in IMC architecture design. SIAM integrates device, circuit, architecture, network-on-chip (NoC), network-on-package (NoP), and DRAM access models to realize an end-to-end system. SIAM is scalable in its support of a wide range of deep neural networks (DNNs), customizable to various network structures and configurations, and capable of efficient design space exploration. We demonstrate the flexibility, scalability, and simulation speed of SIAM by benchmarking different state-of-the-art DNNs with CIFAR-10, CIFAR-100, and ImageNet datasets. We further calibrate the simulation results with a published silicon result, SIMBA. The chiplet-based IMC architecture obtained through SIAM shows 130$\times$ and 72$\times$ improvement in energy-efficiency for ResNet-50 on the ImageNet dataset compared to Nvidia V100 and T4 GPUs.
Impact of On-Chip Interconnect on In-Memory Acceleration of Deep Neural Networks
Jul 06, 2021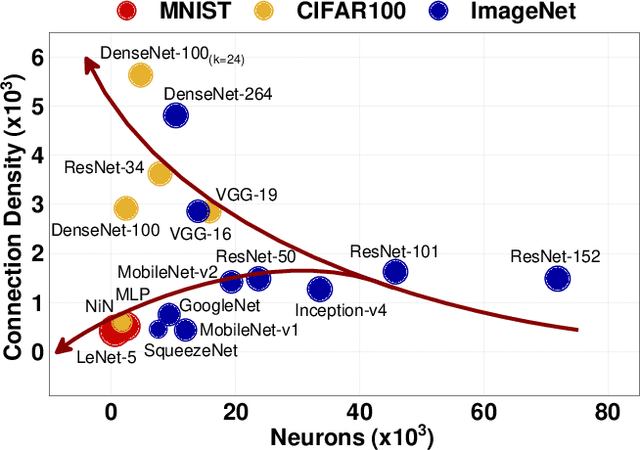
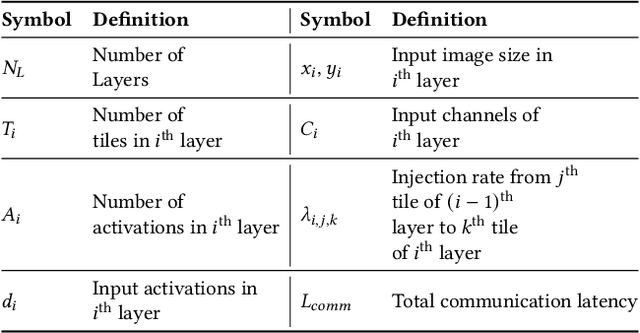
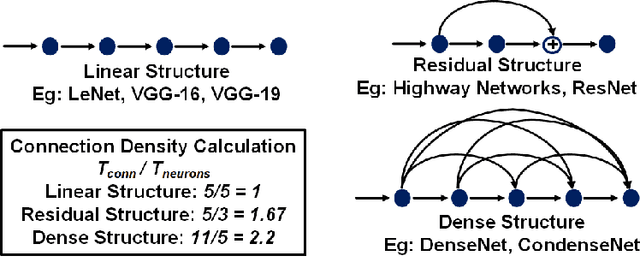

With the widespread use of Deep Neural Networks (DNNs), machine learning algorithms have evolved in two diverse directions -- one with ever-increasing connection density for better accuracy and the other with more compact sizing for energy efficiency. The increase in connection density increases on-chip data movement, which makes efficient on-chip communication a critical function of the DNN accelerator. The contribution of this work is threefold. First, we illustrate that the point-to-point (P2P)-based interconnect is incapable of handling a high volume of on-chip data movement for DNNs. Second, we evaluate P2P and network-on-chip (NoC) interconnect (with a regular topology such as a mesh) for SRAM- and ReRAM-based in-memory computing (IMC) architectures for a range of DNNs. This analysis shows the necessity for the optimal interconnect choice for an IMC DNN accelerator. Finally, we perform an experimental evaluation for different DNNs to empirically obtain the performance of the IMC architecture with both NoC-tree and NoC-mesh. We conclude that, at the tile level, NoC-tree is appropriate for compact DNNs employed at the edge, and NoC-mesh is necessary to accelerate DNNs with high connection density. Furthermore, we propose a technique to determine the optimal choice of interconnect for any given DNN. In this technique, we use analytical models of NoC to evaluate end-to-end communication latency of any given DNN. We demonstrate that the interconnect optimization in the IMC architecture results in up to 6$\times$ improvement in energy-delay-area product for VGG-19 inference compared to the state-of-the-art ReRAM-based IMC architectures.
RA-BNN: Constructing Robust & Accurate Binary Neural Network to Simultaneously Defend Adversarial Bit-Flip Attack and Improve Accuracy
Mar 22, 2021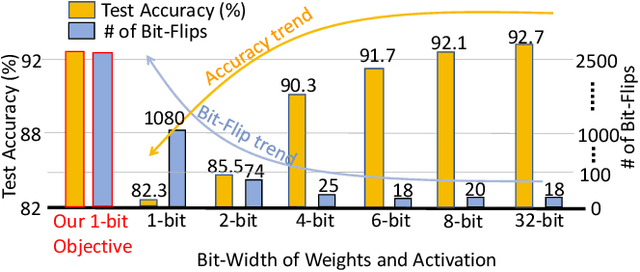
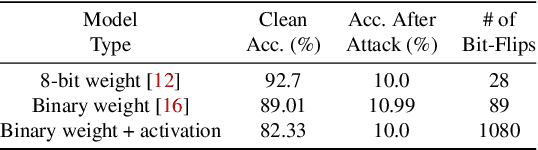
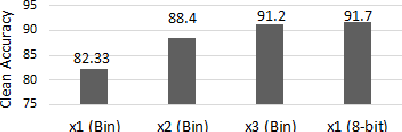

Recently developed adversarial weight attack, a.k.a. bit-flip attack (BFA), has shown enormous success in compromising Deep Neural Network (DNN) performance with an extremely small amount of model parameter perturbation. To defend against this threat, we propose RA-BNN that adopts a complete binary (i.e., for both weights and activation) neural network (BNN) to significantly improve DNN model robustness (defined as the number of bit-flips required to degrade the accuracy to as low as a random guess). However, such an aggressive low bit-width model suffers from poor clean (i.e., no attack) inference accuracy. To counter this, we propose a novel and efficient two-stage network growing method, named Early-Growth. It selectively grows the channel size of each BNN layer based on channel-wise binary masks training with Gumbel-Sigmoid function. Apart from recovering the inference accuracy, our RA-BNN after growing also shows significantly higher resistance to BFA. Our evaluation of the CIFAR-10 dataset shows that the proposed RA-BNN can improve the clean model accuracy by ~2-8 %, compared with a baseline BNN, while simultaneously improving the resistance to BFA by more than 125 x. Moreover, on ImageNet, with a sufficiently large (e.g., 5,000) amount of bit-flips, the baseline BNN accuracy drops to 4.3 % from 51.9 %, while our RA-BNN accuracy only drops to 37.1 % from 60.9 % (9 % clean accuracy improvement).