 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongjian Wu
Dynamic Prototype Mask for Occluded Person Re-Identification
Jul 19, 2022
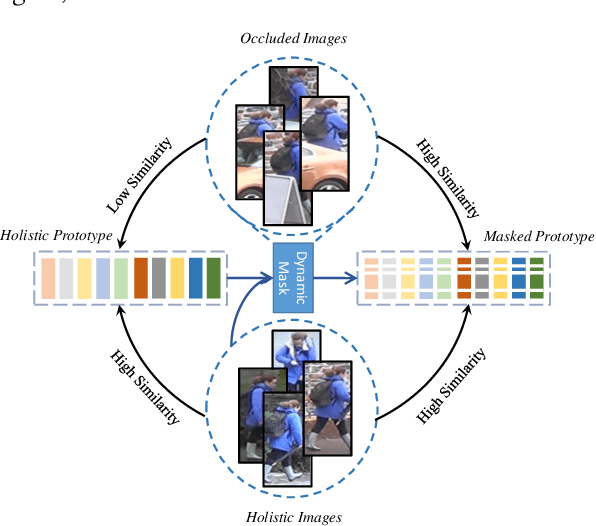
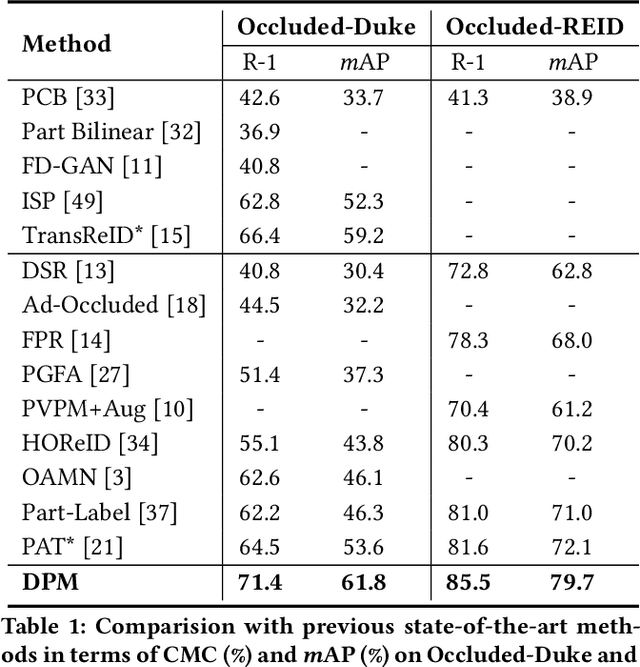
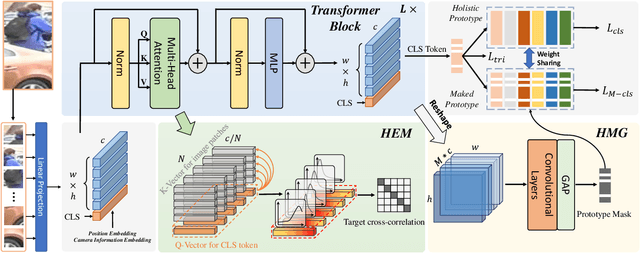
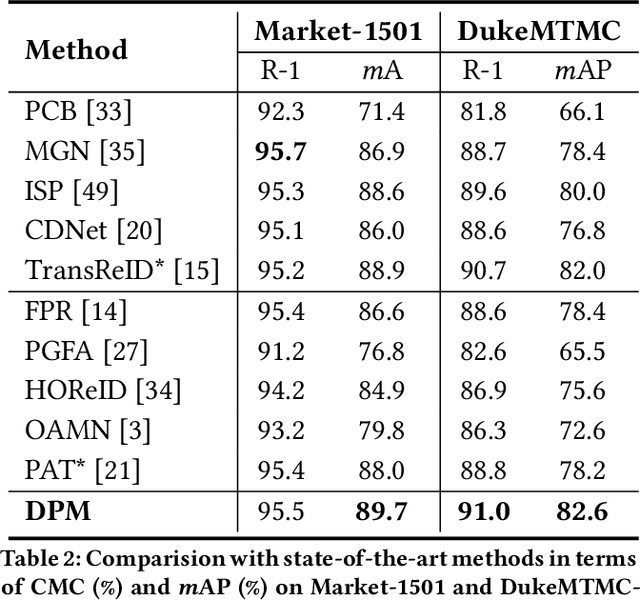
Although person re-identification has achieved an impressive improvement in recent years, the common occlusion case caused by different obstacles is still an unsettled issue in real application scenarios. Existing methods mainly address this issue by employing body clues provided by an extra network to distinguish the visible part. Nevertheless, the inevitable domain gap between the assistant model and the ReID datasets has highly increased the difficulty to obtain an effective and efficient model. To escape from the extra pre-trained networks and achieve an automatic alignment in an end-to-end trainable network, we propose a novel Dynamic Prototype Mask (DPM) based on two self-evident prior knowledge. Specifically, we first devise a Hierarchical Mask Generator which utilizes the hierarchical semantic to select the visible pattern space between the high-quality holistic prototype and the feature representation of the occluded input image. Under this condition, the occluded representation could be well aligned in a selected subspace spontaneously. Then, to enrich the feature representation of the high-quality holistic prototype and provide a more complete feature space, we introduce a Head Enrich Module to encourage different heads to aggregate different patterns representation in the whole image. Extensive experimental evaluations conducted on occluded and holistic person re-identification benchmarks demonstrate the superior performance of the DPM over the state-of-the-art methods. The code is released at https://github.com/stone96123/DPM.
Learning Best Combination for Efficient N:M Sparsity
Jun 14, 2022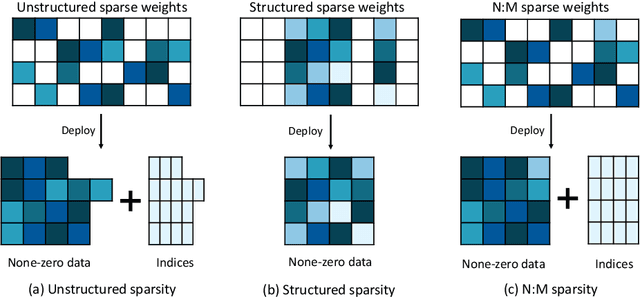
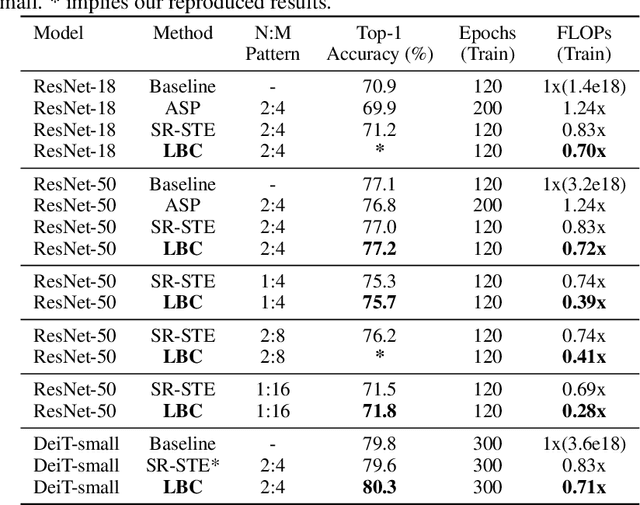
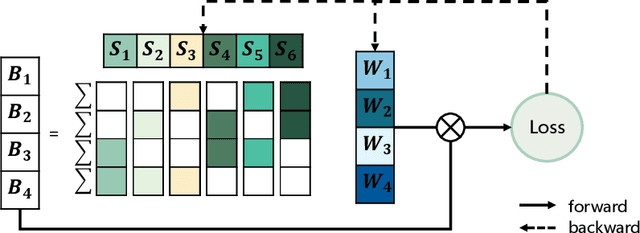
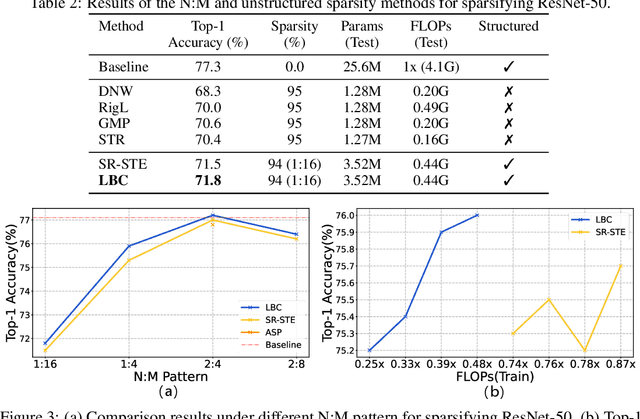
By forcing at most N out of M consecutive weights to be non-zero, the recent N:M network sparsity has received increasing attention for its two attractive advantages: 1) Promising performance at a high sparsity. 2) Significant speedups on NVIDIA A100 GPUs. Recent studies require an expensive pre-training phase or a heavy dense-gradient computation. In this paper, we show that the N:M learning can be naturally characterized as a combinatorial problem which searches for the best combination candidate within a finite collection. Motivated by this characteristic, we solve N:M sparsity in an efficient divide-and-conquer manner. First, we divide the weight vector into $C_{\text{M}}^{\text{N}}$ combination subsets of a fixed size N. Then, we conquer the combinatorial problem by assigning each combination a learnable score that is jointly optimized with its associate weights. We prove that the introduced scoring mechanism can well model the relative importance between combination subsets. And by gradually removing low-scored subsets, N:M fine-grained sparsity can be efficiently optimized during the normal training phase. Comprehensive experiments demonstrate that our learning best combination (LBC) performs consistently better than off-the-shelf N:M sparsity methods across various networks. Our code is released at \url{https://github.com/zyxxmu/LBC}.
Occlusion-Resistant Instance Segmentation of Piglets in Farrowing Pens Using Center Clustering Network
Jun 04, 2022Computer vision enables the development of new approaches to monitor the behavior, health, and welfare of animals. Instance segmentation is a high-precision method in computer vision for detecting individual animals of interest. This method can be used for in-depth analysis of animals, such as examining their subtle interactive behaviors, from videos and images. However, existing deep-learning-based instance segmentation methods have been mostly developed based on public datasets, which largely omit heavy occlusion problems; therefore, these methods have limitations in real-world applications involving object occlusions, such as farrowing pen systems used on pig farms in which the farrowing crates often impede the sow and piglets. In this paper, we propose a novel occlusion-resistant Center Clustering Network for instance segmentation, dubbed as CClusnet-Inseg. Specifically, CClusnet-Inseg uses each pixel to predict object centers and trace these centers to form masks based on clustering results, which consists of a network for segmentation and center offset vector map, Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, Centers-to-Mask (C2M) and Remain-Centers-to-Mask (RC2M) algorithms, and a pseudo-occlusion generator (POG). In all, 4,600 images were extracted from six videos collected from six farrowing pens to train and validate our method. CClusnet-Inseg achieves a mean average precision (mAP) of 83.6; it outperformed YOLACT++ and Mask R-CNN, which had mAP values of 81.2 and 74.7, respectively. We conduct comprehensive ablation studies to demonstrate the advantages and effectiveness of core modules of our method. In addition, we apply CClusnet-Inseg to multi-object tracking for animal monitoring, and the predicted object center that is a conjunct output could serve as an occlusion-resistant representation of the location of an object.
What Goes beyond Multi-modal Fusion in One-stage Referring Expression Comprehension: An Empirical Study
Apr 17, 2022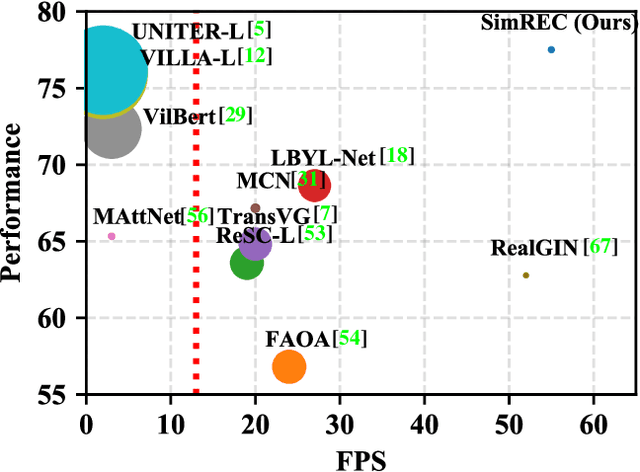
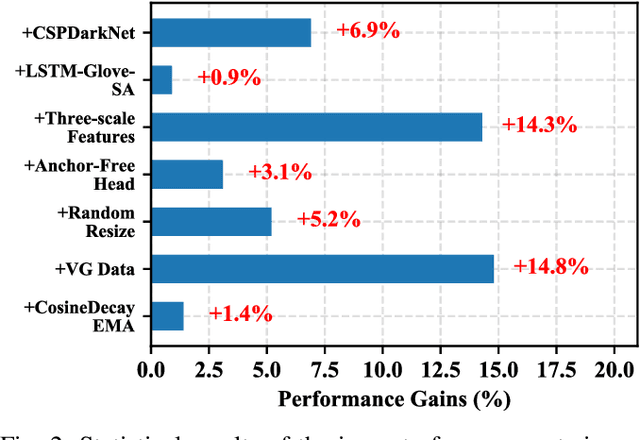
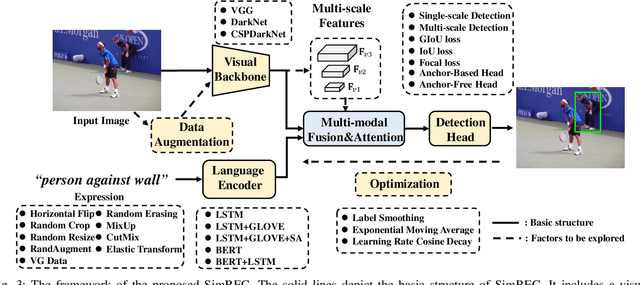
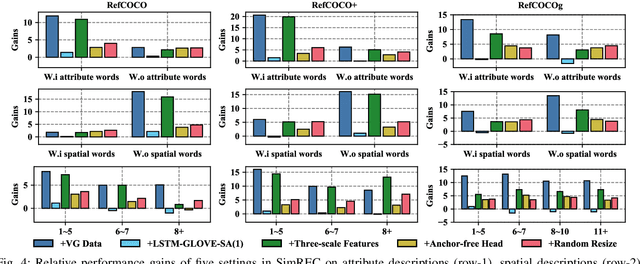
Most of the existing work in one-stage referring expression comprehension (REC) mainly focuses on multi-modal fusion and reasoning, while the influence of other factors in this task lacks in-depth exploration. To fill this gap, we conduct an empirical study in this paper. Concretely, we first build a very simple REC network called SimREC, and ablate 42 candidate designs/settings, which covers the entire process of one-stage REC from network design to model training. Afterwards, we conduct over 100 experimental trials on three benchmark datasets of REC. The extensive experimental results not only show the key factors that affect REC performance in addition to multi-modal fusion, e.g., multi-scale features and data augmentation, but also yield some findings that run counter to conventional understanding. For example, as a vision and language (V&L) task, REC does is less impacted by language prior. In addition, with a proper combination of these findings, we can improve the performance of SimREC by a large margin, e.g., +27.12% on RefCOCO+, which outperforms all existing REC methods. But the most encouraging finding is that with much less training overhead and parameters, SimREC can still achieve better performance than a set of large-scale pre-trained models, e.g., UNITER and VILLA, portraying the special role of REC in existing V&L research.
Towards Lightweight Transformer via Group-wise Transformation for Vision-and-Language Tasks
Apr 16, 2022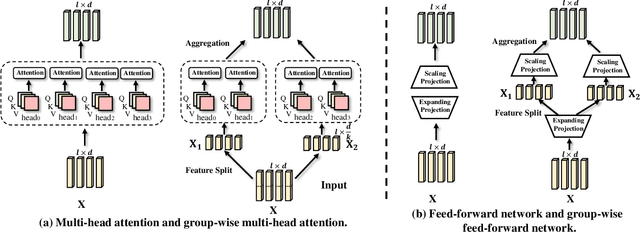


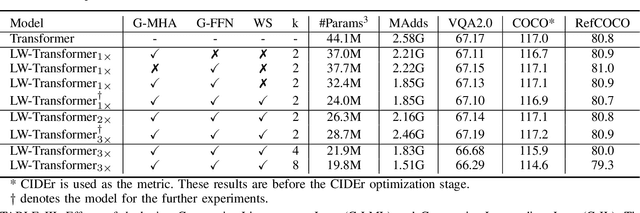
Despite the exciting performance, Transformer is criticized for its excessive parameters and computation cost. However, compressing Transformer remains as an open problem due to its internal complexity of the layer designs, i.e., Multi-Head Attention (MHA) and Feed-Forward Network (FFN). To address this issue, we introduce Group-wise Transformation towards a universal yet lightweight Transformer for vision-and-language tasks, termed as LW-Transformer. LW-Transformer applies Group-wise Transformation to reduce both the parameters and computations of Transformer, while also preserving its two main properties, i.e., the efficient attention modeling on diverse subspaces of MHA, and the expanding-scaling feature transformation of FFN. We apply LW-Transformer to a set of Transformer-based networks, and quantitatively measure them on three vision-and-language tasks and six benchmark datasets. Experimental results show that while saving a large number of parameters and computations, LW-Transformer achieves very competitive performance against the original Transformer networks for vision-and-language tasks. To examine the generalization ability, we also apply our optimization strategy to a recently proposed image Transformer called Swin-Transformer for image classification, where the effectiveness can be also confirmed
Global2Local: A Joint-Hierarchical Attention for Video Captioning
Mar 13, 2022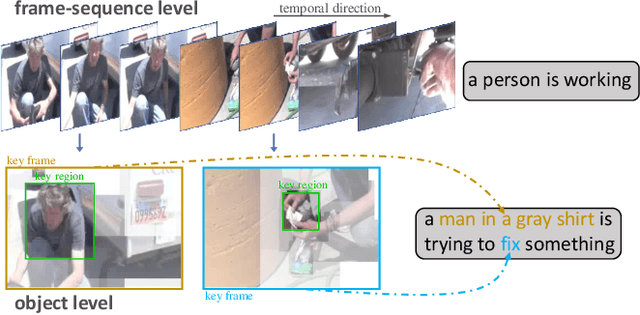
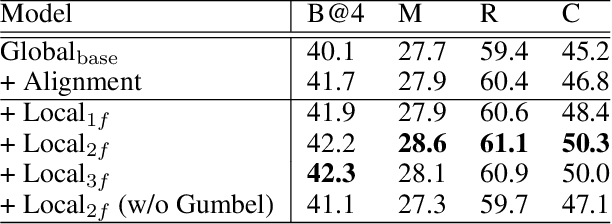
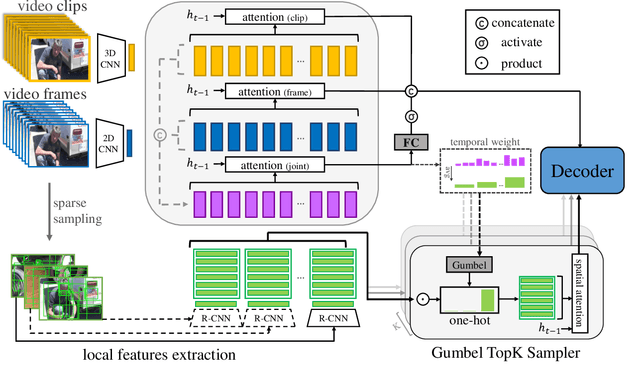
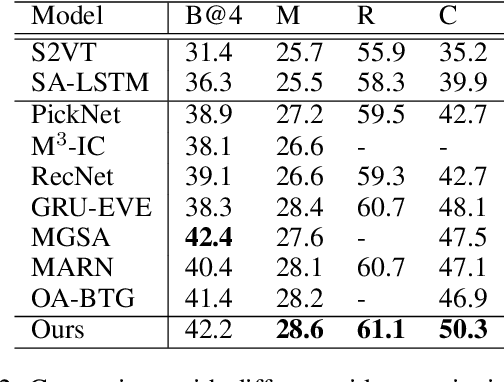
Recently, automatic video captioning has attracted increasing attention, where the core challenge lies in capturing the key semantic items, like objects and actions as well as their spatial-temporal correlations from the redundant frames and semantic content. To this end, existing works select either the key video clips in a global level~(across multi frames), or key regions within each frame, which, however, neglect the hierarchical order, i.e., key frames first and key regions latter. In this paper, we propose a novel joint-hierarchical attention model for video captioning, which embeds the key clips, the key frames and the key regions jointly into the captioning model in a hierarchical manner. Such a joint-hierarchical attention model first conducts a global selection to identify key frames, followed by a Gumbel sampling operation to identify further key regions based on the key frames, achieving an accurate global-to-local feature representation to guide the captioning. Extensive quantitative evaluations on two public benchmark datasets MSVD and MSR-VTT demonstrates the superiority of the proposed method over the state-of-the-art methods.
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022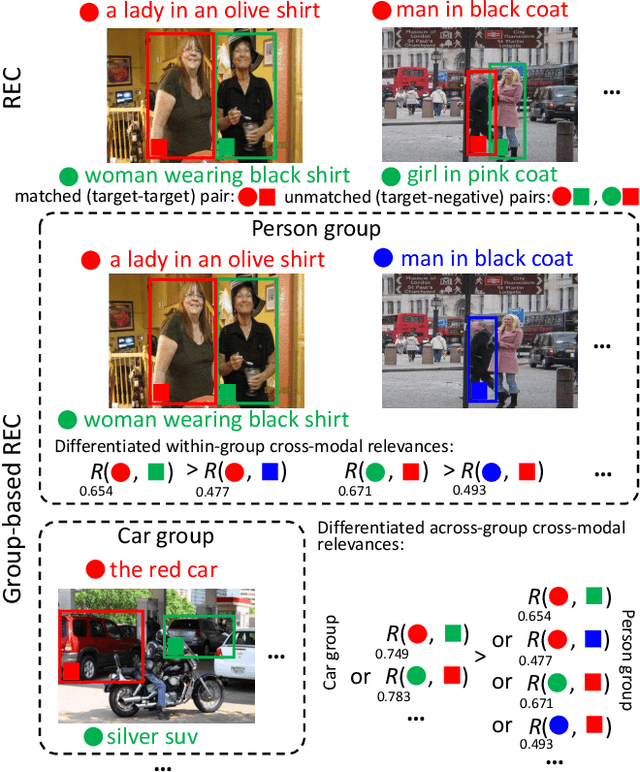
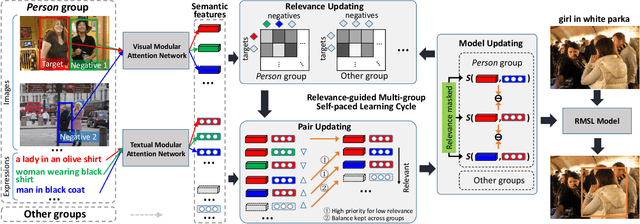

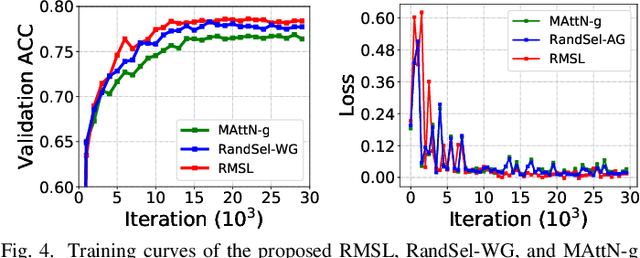
Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
Mar 10, 2022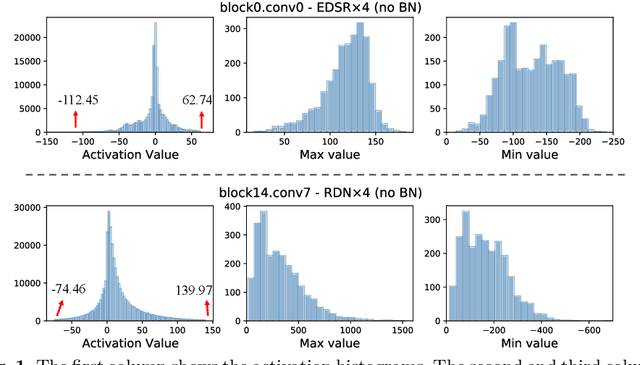
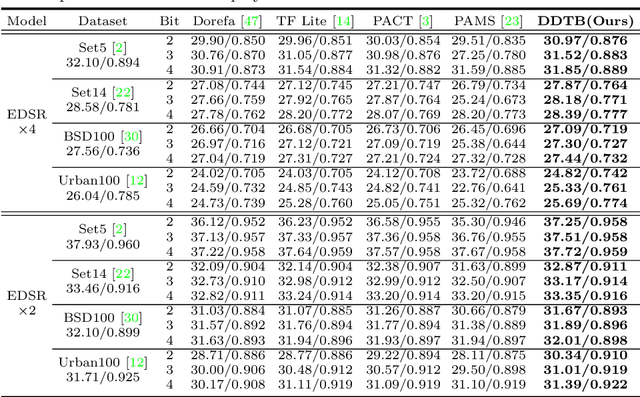
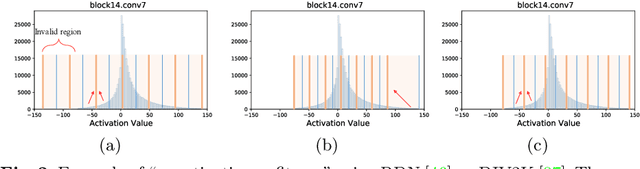
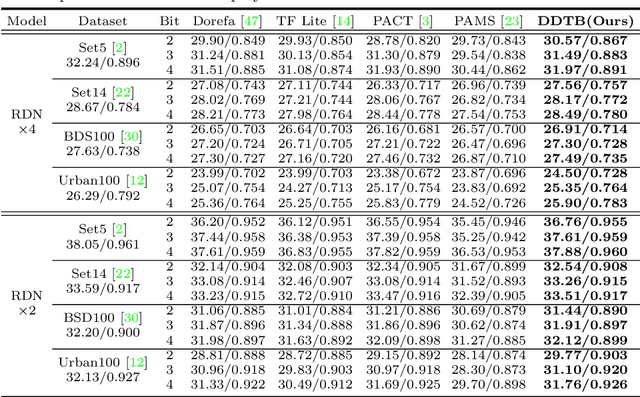
Light-weight super-resolution (SR) models have received considerable attention for their serviceability in mobile devices. Many efforts employ network quantization to compress SR models. However, these methods suffer from severe performance degradation when quantizing the SR models to ultra-low precision (e.g., 2-bit and 3-bit) with the low-cost layer-wise quantizer. In this paper, we identify that the performance drop comes from the contradiction between the layer-wise symmetric quantizer and the highly asymmetric activation distribution in SR models. This discrepancy leads to either a waste on the quantization levels or detail loss in reconstructed images. Therefore, we propose a novel activation quantizer, referred to as Dynamic Dual Trainable Bounds (DDTB), to accommodate the asymmetry of the activations. Specifically, DDTB innovates in: 1) A layer-wise quantizer with trainable upper and lower bounds to tackle the highly asymmetric activations. 2) A dynamic gate controller to adaptively adjust the upper and lower bounds at runtime to overcome the drastically varying activation ranges over different samples.To reduce the extra overhead, the dynamic gate controller is quantized to 2-bit and applied to only part of the SR networks according to the introduced dynamic intensity. Extensive experiments demonstrate that our DDTB exhibits significant performance improvements in ultra-low precision. For example, our DDTB achieves a 0.70dB PSNR increase on Urban100 benchmark when quantizing EDSR to 2-bit and scaling up output images to x4. Code is at \url{https://github.com/zysxmu/DDTB}.
Coarse-to-Fine Vision Transformer
Mar 08, 2022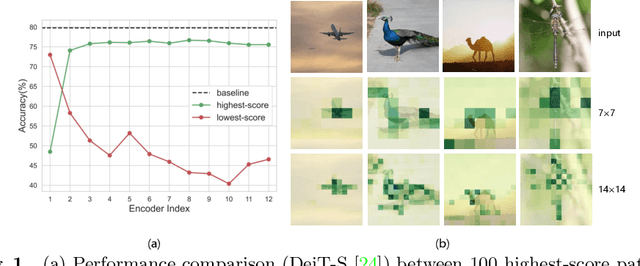
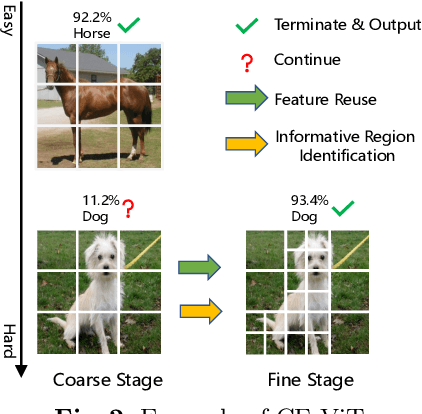
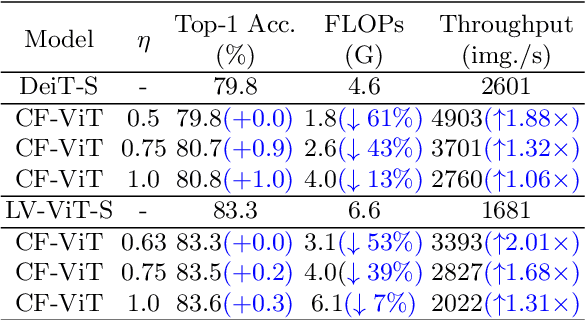
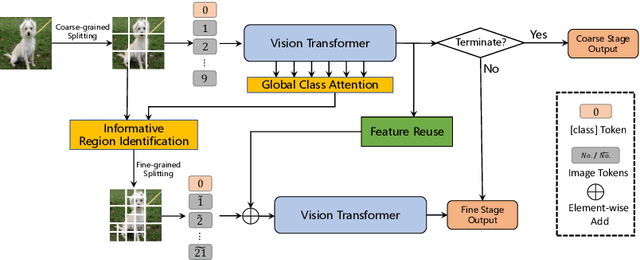
Vision Transformers (ViT) have made many breakthroughs in computer vision tasks. However, considerable redundancy arises in the spatial dimension of an input image, leading to massive computational costs. Therefore, We propose a coarse-to-fine vision transformer (CF-ViT) to relieve computational burden while retaining performance in this paper. Our proposed CF-ViT is motivated by two important observations in modern ViT models: (1) The coarse-grained patch splitting can locate informative regions of an input image. (2) Most images can be well recognized by a ViT model in a small-length token sequence. Therefore, our CF-ViT implements network inference in a two-stage manner. At coarse inference stage, an input image is split into a small-length patch sequence for a computationally economical classification. If not well recognized, the informative patches are identified and further re-split in a fine-grained granularity. Extensive experiments demonstrate the efficacy of our CF-ViT. For example, without any compromise on performance, CF-ViT reduces 53% FLOPs of LV-ViT, and also achieves 2.01x throughput.
Optimizing Gradient-driven Criteria in Network Sparsity: Gradient is All You Need
Jan 30, 2022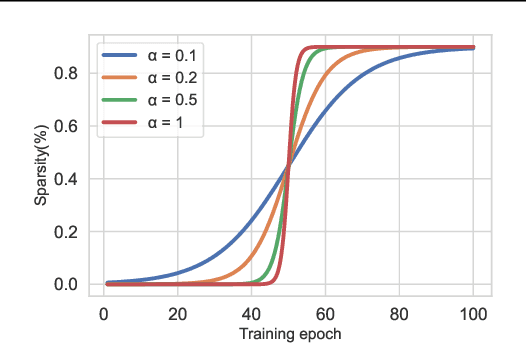
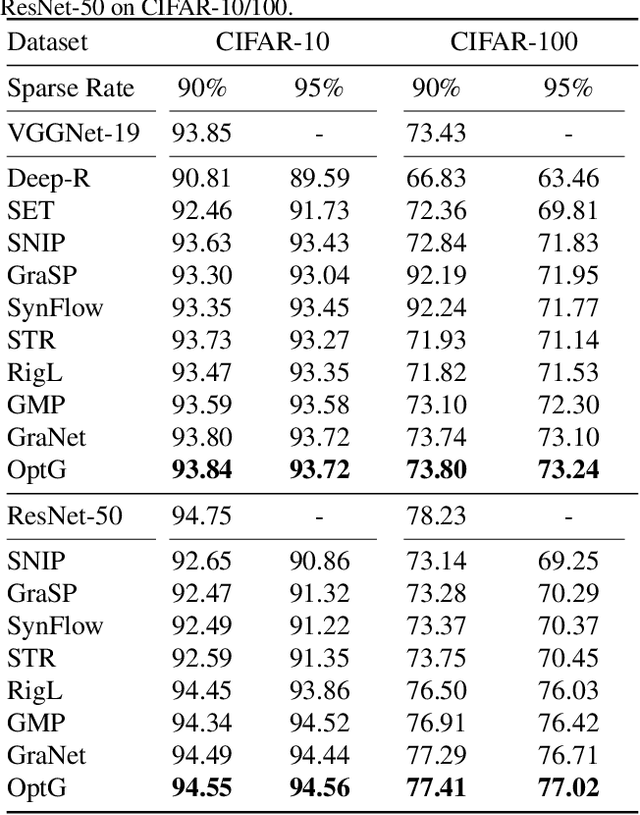
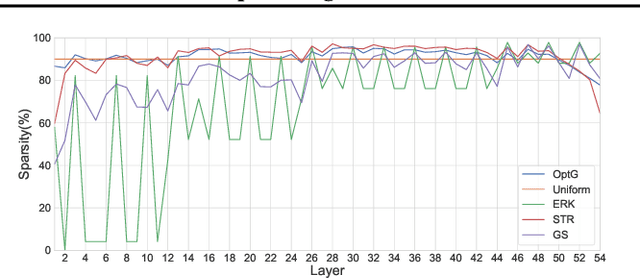
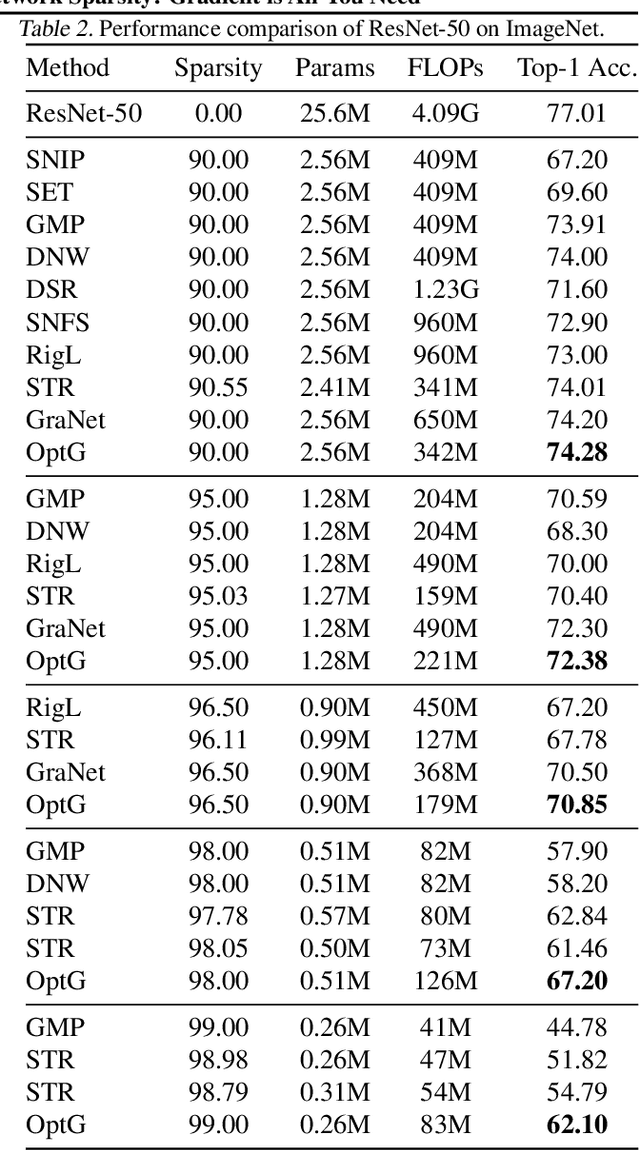
Network sparsity receives popularity mostly due to its capability to reduce the network complexity. Extensive studies excavate gradient-driven sparsity. Typically, these methods are constructed upon premise of weight independence, which however, is contrary to the fact that weights are mutually influenced. Thus, their performance remains to be improved. In this paper, we propose to further optimize gradient-driven sparsity (OptG) by solving this independence paradox. Our motive comes from the recent advances on supermask training which shows that sparse subnetworks can be located in a randomly initialized network by simply updating mask values without modifying any weight. We prove that supermask training is to accumulate the weight gradients and can partly solve the independence paradox. Consequently, OptG integrates supermask training into gradient-driven sparsity, and a specialized mask optimizer is designed to solve the independence paradox. Experiments show that OptG can well surpass many existing state-of-the-art competitors. Our code is available at \url{https://github.com/zyxxmu/OptG}.