 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-based Out-of-Distribution Detection for Graph Neural Networks
Feb 06, 2023Learning on graphs, where instance nodes are inter-connected, has become one of the central problems for deep learning, as relational structures are pervasive and induce data inter-dependence which hinders trivial adaptation of existing approaches that assume inputs to be i.i.d.~sampled. However, current models mostly focus on improving testing performance of in-distribution data and largely ignore the potential risk w.r.t. out-of-distribution (OOD) testing samples that may cause negative outcome if the prediction is overconfident on them. In this paper, we investigate the under-explored problem, OOD detection on graph-structured data, and identify a provably effective OOD discriminator based on an energy function directly extracted from graph neural networks trained with standard classification loss. This paves a way for a simple, powerful and efficient OOD detection model for GNN-based learning on graphs, which we call GNNSafe. It also has nice theoretical properties that guarantee an overall distinguishable margin between the detection scores for in-distribution and OOD samples, which, more critically, can be further strengthened by a learning-free energy belief propagation scheme. For comprehensive evaluation, we introduce new benchmark settings that evaluate the model for detecting OOD data from both synthetic and real distribution shifts (cross-domain graph shifts and temporal graph shifts). The results show that GNNSafe achieves up to $17.0\%$ AUROC improvement over state-of-the-arts and it could serve as simple yet strong baselines in such an under-developed area.
Robot Cooking with Stir-fry: Bimanual Non-prehensile Manipulation of Semi-fluid Objects
May 12, 2022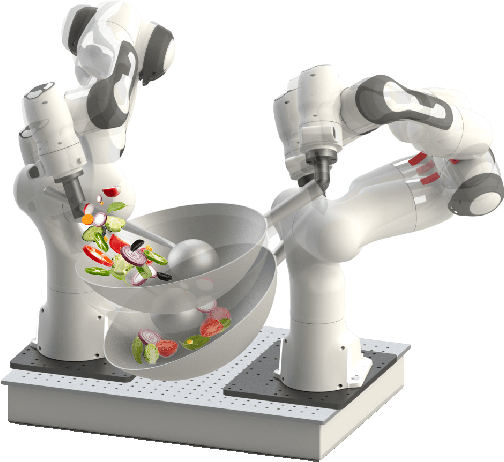
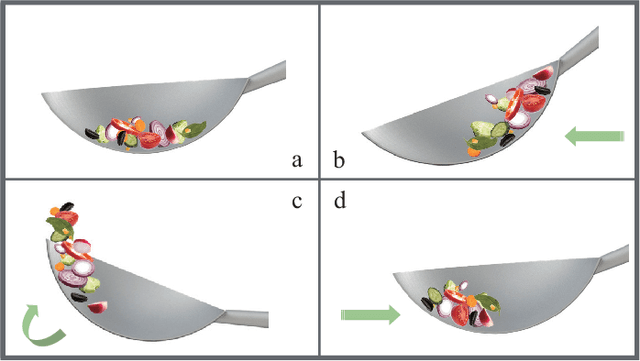
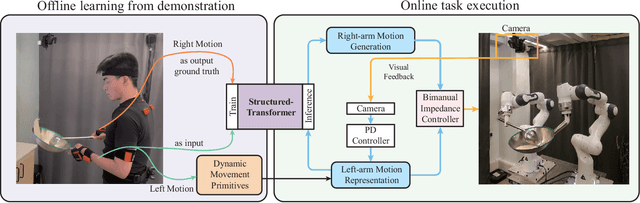
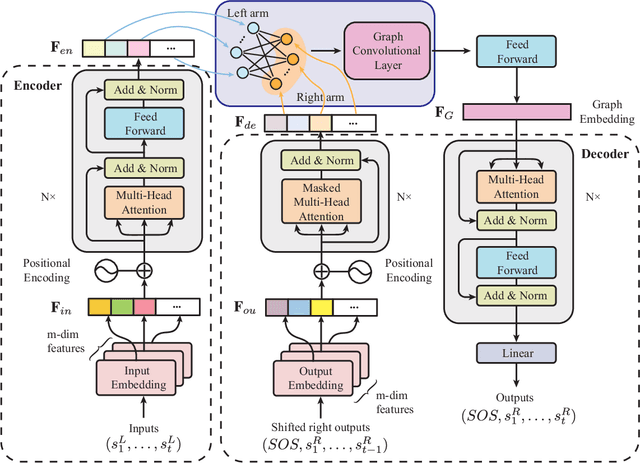
This letter describes an approach to achieve well-known Chinese cooking art stir-fry on a bimanual robot system. Stir-fry requires a sequence of highly dynamic coordinated movements, which is usually difficult to learn for a chef, let alone transfer to robots. In this letter, we define a canonical stir-fry movement, and then propose a decoupled framework for learning this deformable object manipulation from human demonstration. First, the dual arms of the robot are decoupled into different roles (a leader and follower) and learned with classical and neural network-based methods separately, then the bimanual task is transformed into a coordination problem. To obtain general bimanual coordination, we secondly propose a Graph and Transformer based model -- Structured-Transformer, to capture the spatio-temporal relationship between dual-arm movements. Finally, by adding visual feedback of content deformation, our framework can adjust the movements automatically to achieve the desired stir-fry effect. We verify the framework by a simulator and deploy it on a real bimanual Panda robot system. The experimental results validate our framework can realize the bimanual robot stir-fry motion and have the potential to extend to other deformable objects with bimanual coordination.
* 8 pages, 8 figures, published to RA-L
A Unified Game-Theoretic Interpretation of Adversarial Robustness
Nov 08, 2021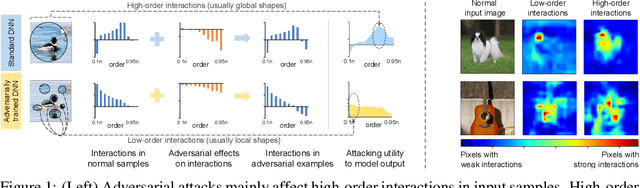

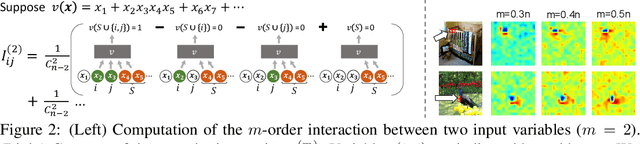
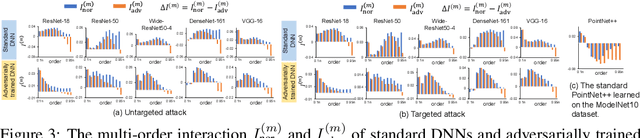
This paper provides a unified view to explain different adversarial attacks and defense methods, \emph{i.e.} the view of multi-order interactions between input variables of DNNs. Based on the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide a potential method to unify adversarial perturbations and robustness, which can explain the existing defense methods in a principle way. Besides, our findings also make a revision of previous inaccurate understanding of the shape bias of adversarially learned features.
Learning Robotic Ultrasound Scanning Skills via Human Demonstrations and Guided Explorations
Nov 02, 2021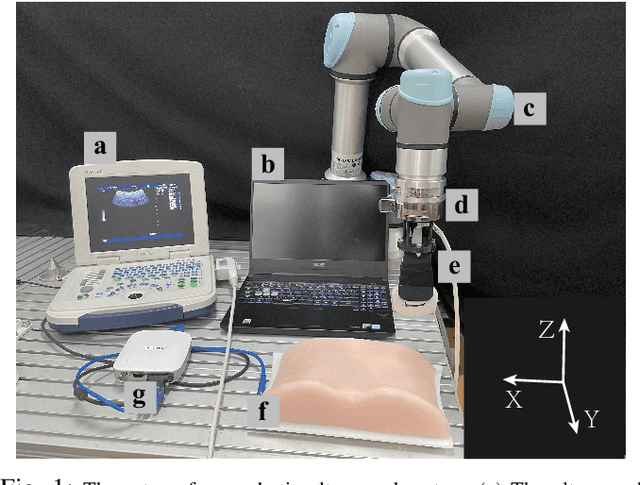
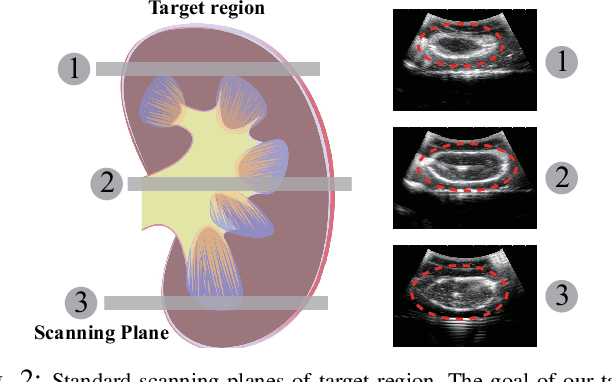
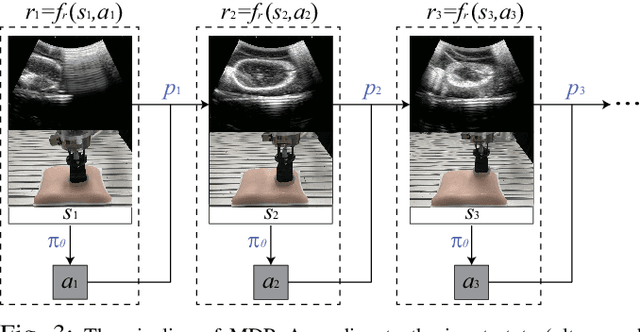
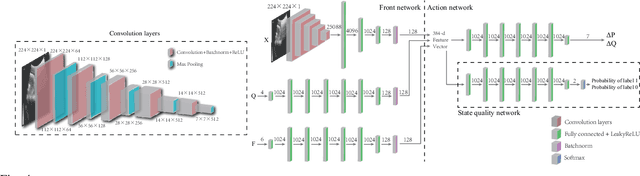
Medical ultrasound has become a routine examination approach nowadays and is widely adopted for different medical applications, so it is desired to have a robotic ultrasound system to perform the ultrasound scanning autonomously. However, the ultrasound scanning skill is considerably complex, which highly depends on the experience of the ultrasound physician. In this paper, we propose a learning-based approach to learn the robotic ultrasound scanning skills from human demonstrations. First, the robotic ultrasound scanning skill is encapsulated into a high-dimensional multi-modal model, which takes the ultrasound images, the pose/position of the probe and the contact force into account. Second, we leverage the power of imitation learning to train the multi-modal model with the training data collected from the demonstrations of experienced ultrasound physicians. Finally, a post-optimization procedure with guided explorations is proposed to further improve the performance of the learned model. Robotic experiments are conducted to validate the advantages of our proposed framework and the learned models.
Learning Friction Model for Tethered Capsule Robot
Aug 16, 2021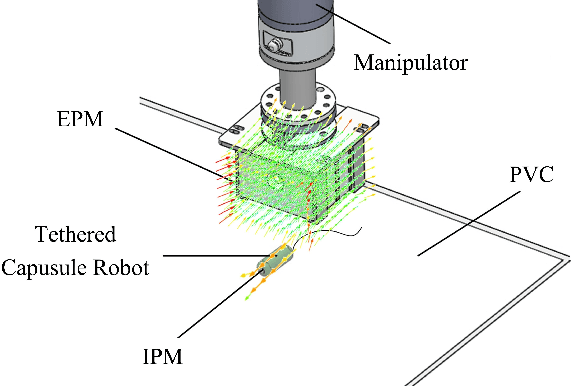


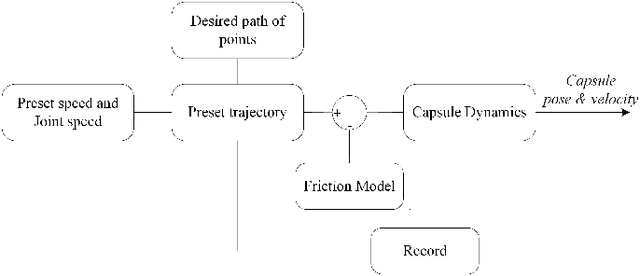
With the potential applications of capsule robots in medical endoscopy, accurate dynamic control of the capsule robot is becoming more and more important. In the scale of a capsule robot, the friction between capsule and the environment plays an essential role in the dynamic model, which is usually difficult to model beforehand. In the paper, a tethered capsule robot system driven by a robot manipulator is built, where a strong magnetic Halbach array is mounted on the robot's end-effector to adjust the state of the capsule. To increase the control accuracy, the friction between capsule and the environment is learned with demonstrated trajectories. With the learned friction model, experimental results demonstrate an improvement of 5.6% in terms of tracking error.
Data Generation for Learning to Grasp in a Bin-picking Scenario
Aug 14, 2021



The rise of deep learning has greatly transformed the pipeline of robotic grasping from model-based approach to data-driven stream. Along this line, a large scale of grasping data either collected from simulation or from real world examples become extremely important. In this paper, we present our recent work on data generation in simulation for a bin-picking scene. 77 objects from the YCB object data sets are used to generate the dataset with PyBullet, where different environment conditions are taken into account including lighting, camera pose, sensor noise and so on. In all, 100K data samples are collected in terms of ground truth segmentation, RGB, 6D pose and point cloud. All the data examples including the source code are made available online.
Unknown Object Segmentation through Domain Adaptation
Aug 09, 2021


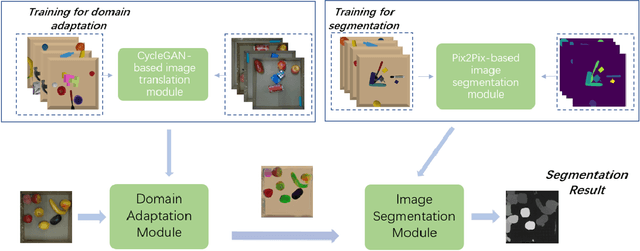
The ability to segment unknown objects in cluttered scenes has a profound impact on robot grasping. The rise of deep learning has greatly transformed the pipeline of robotic grasping from model-based approach to data-driven stream, which generally requires a large scale of grasping data either collected in simulation or from real-world examples. In this paper, we proposed a sim-to-real framework to transfer the object segmentation model learned in simulation to the real-world. First, data samples are collected in simulation, including RGB, 6D pose, and point cloud. Second, we also present a GAN-based unknown object segmentation method through domain adaptation, which consists of an image translation module and an image segmentation module. The image translation module is used to shorten the reality gap and the segmentation module is responsible for the segmentation mask generation. We used the above method to perform segmentation experiments on unknown objects in a bin-picking scenario. Finally, the experimental result shows that the segmentation model learned in simulation can be used for real-world data segmentation.
OoD-Bench: Benchmarking and Understanding Out-of-Distribution Generalization Datasets and Algorithms
Jun 07, 2021
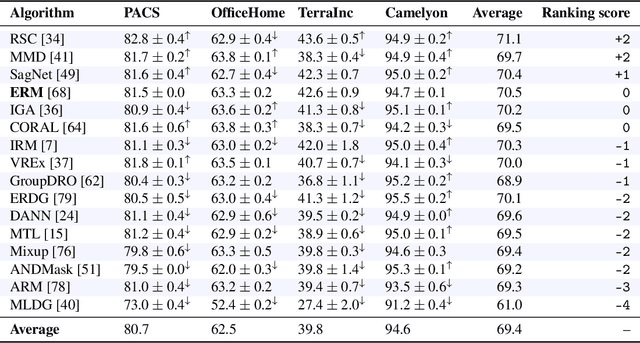
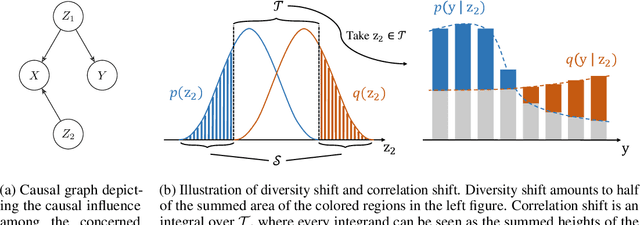
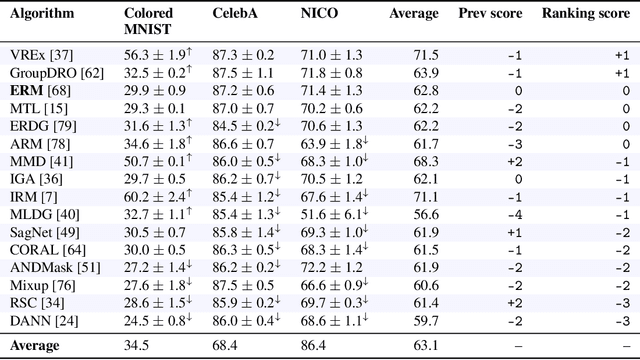
Deep learning has achieved tremendous success with independent and identically distributed (i.i.d.) data. However, the performance of neural networks often degenerates drastically when encountering out-of-distribution (OoD) data, i.e., training and test data are sampled from different distributions. While a plethora of algorithms has been proposed to deal with OoD generalization, our understanding of the data used to train and evaluate these algorithms remains stagnant. In this work, we position existing datasets and algorithms from various research areas (e.g., domain generalization, stable learning, invariant risk minimization) seemingly unconnected into the same coherent picture. First, we identify and measure two distinct kinds of distribution shifts that are ubiquitous in various datasets. Next, we compare various OoD generalization algorithms with a new benchmark dominated by the two distribution shifts. Through extensive experiments, we show that existing OoD algorithms that outperform empirical risk minimization on one distribution shift usually have limitations on the other distribution shift. The new benchmark may serve as a strong foothold that can be resorted to by future OoD generalization research.
Game-theoretic Understanding of Adversarially Learned Features
Mar 12, 2021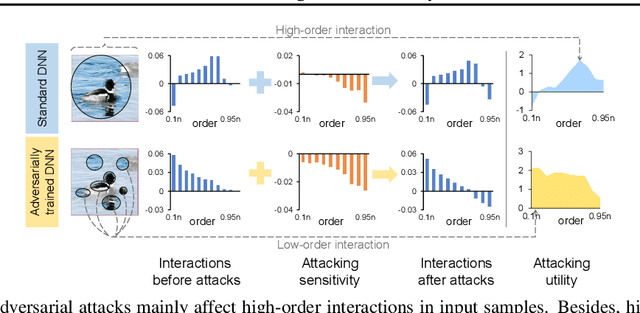
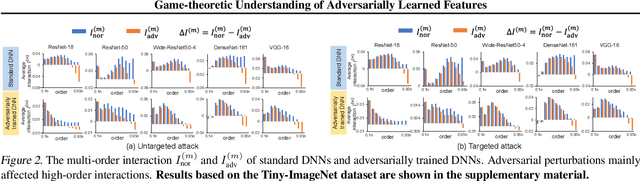
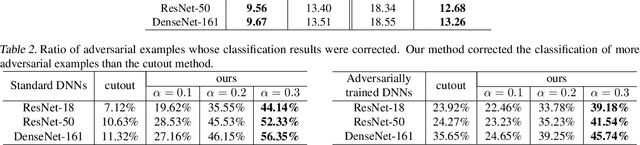
This paper aims to understand adversarial attacks and defense from a new perspecitve, i.e., the signal-processing behavior of DNNs. We novelly define the multi-order interaction in game theory, which satisfies six properties. With the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide more insights into and make a revision of previous understanding for the shape bias of adversarially learned features. Besides, the multi-order interaction can also explain the recoverability of adversarial examples.
Game-Theoretic Interactions of Different Orders
Oct 28, 2020In this study, we define interaction components of different orders between two input variables based on game theory. We further prove that interaction components of different orders satisfy several desirable properties.