 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Constrained Reinforcement Learning under Strong Duality
Jun 22, 2024


We study the problem of Distributionally Robust Constrained RL (DRC-RL), where the goal is to maximize the expected reward subject to environmental distribution shifts and constraints. This setting captures situations where training and testing environments differ, and policies must satisfy constraints motivated by safety or limited budgets. Despite significant progress toward algorithm design for the separate problems of distributionally robust RL and constrained RL, there do not yet exist algorithms with end-to-end convergence guarantees for DRC-RL. We develop an algorithmic framework based on strong duality that enables the first efficient and provable solution in a class of environmental uncertainties. Further, our framework exposes an inherent structure of DRC-RL that arises from the combination of distributional robustness and constraints, which prevents a popular class of iterative methods from tractably solving DRC-RL, despite such frameworks being applicable for each of distributionally robust RL and constrained RL individually. Finally, we conduct experiments on a car racing benchmark to evaluate the effectiveness of the proposed algorithm.
Preferential Multi-Objective Bayesian Optimization
Jun 20, 2024Preferential Bayesian optimization (PBO) is a framework for optimizing a decision-maker's latent preferences over available design choices. While preferences often involve multiple conflicting objectives, existing work in PBO assumes that preferences can be encoded by a single objective function. For example, in robotic assistive devices, technicians often attempt to maximize user comfort while simultaneously minimizing mechanical energy consumption for longer battery life. Similarly, in autonomous driving policy design, decision-makers wish to understand the trade-offs between multiple safety and performance attributes before committing to a policy. To address this gap, we propose the first framework for PBO with multiple objectives. Within this framework, we present dueling scalarized Thompson sampling (DSTS), a multi-objective generalization of the popular dueling Thompson algorithm, which may be of interest beyond the PBO setting. We evaluate DSTS across four synthetic test functions and two simulated exoskeleton personalization and driving policy design tasks, showing that it outperforms several benchmarks. Finally, we prove that DSTS is asymptotically consistent. As a direct consequence, this result provides, to our knowledge, the first convergence guarantee for dueling Thompson sampling in the PBO setting.
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
Jun 06, 2024



Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^\text{EM}$ and Self-Rewarding LM.
Population Transformer: Learning Population-level Representations of Intracranial Activity
Jun 05, 2024



We present a self-supervised framework that learns population-level codes for intracranial neural recordings at scale, unlocking the benefits of representation learning for a key neuroscience recording modality. The Population Transformer (PopT) lowers the amount of data required for decoding experiments, while increasing accuracy, even on never-before-seen subjects and tasks. We address two key challenges in developing PopT: sparse electrode distribution and varying electrode location across patients. PopT stacks on top of pretrained representations and enhances downstream tasks by enabling learned aggregation of multiple spatially-sparse data channels. Beyond decoding, we interpret the pretrained PopT and fine-tuned models to show how it can be used to provide neuroscience insights learned from massive amounts of data. We release a pretrained PopT to enable off-the-shelf improvements in multi-channel intracranial data decoding and interpretability, and code is available at https://github.com/czlwang/PopulationTransformer.
Self-Control of LLM Behaviors by Compressing Suffix Gradient into Prefix Controller
Jun 04, 2024



We propose Self-Control, a novel method utilizing suffix gradients to control the behavior of large language models (LLMs) without explicit human annotations. Given a guideline expressed in suffix string and the model's self-assessment of adherence, Self-Control computes the gradient of this self-judgment concerning the model's hidden states, directly influencing the auto-regressive generation process towards desired behaviors. To enhance efficiency, we introduce Self-Control_{prefix}, a compact module that encapsulates the learned representations from suffix gradients into a Prefix Controller, facilitating inference-time control for various LLM behaviors. Our experiments demonstrate Self-Control's efficacy across multiple domains, including emotional modulation, ensuring harmlessness, and enhancing complex reasoning. Especially, Self-Control_{prefix} enables a plug-and-play control and jointly controls multiple attributes, improving model outputs without altering model parameters or increasing inference-time costs.
Principled Probabilistic Imaging using Diffusion Models as Plug-and-Play Priors
May 29, 2024



Diffusion models (DMs) have recently shown outstanding capability in modeling complex image distributions, making them expressive image priors for solving Bayesian inverse problems. However, most existing DM-based methods rely on approximations in the generative process to be generic to different inverse problems, leading to inaccurate sample distributions that deviate from the target posterior defined within the Bayesian framework. To harness the generative power of DMs while avoiding such approximations, we propose a Markov chain Monte Carlo algorithm that performs posterior sampling for general inverse problems by reducing it to sampling the posterior of a Gaussian denoising problem. Crucially, we leverage a general DM formulation as a unified interface that allows for rigorously solving the denoising problem with a range of state-of-the-art DMs. We demonstrate the effectiveness of the proposed method on six inverse problems (three linear and three nonlinear), including a real-world black hole imaging problem. Experimental results indicate that our proposed method offers more accurate reconstructions and posterior estimation compared to existing DM-based imaging inverse methods.
Data-Driven Predictive Control for Robust Exoskeleton Locomotion
Mar 23, 2024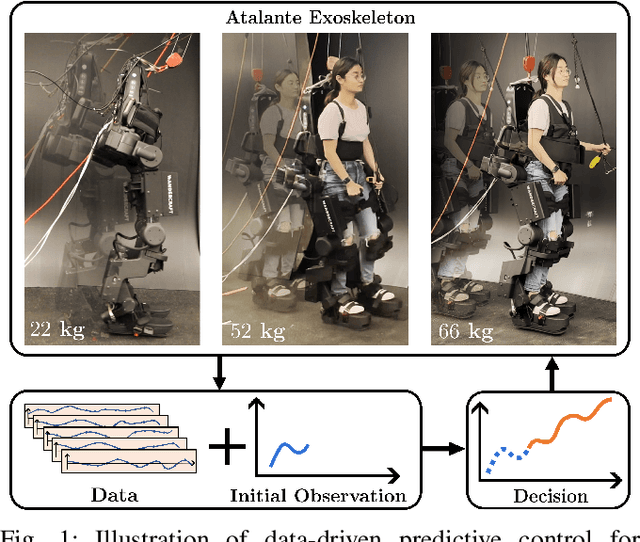
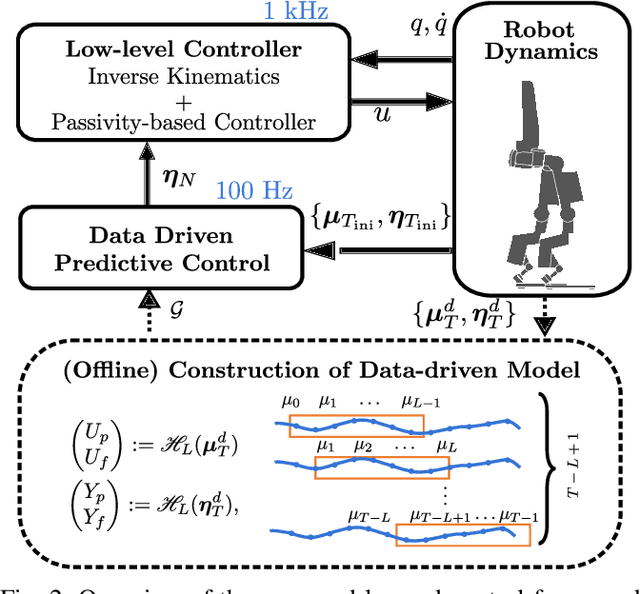
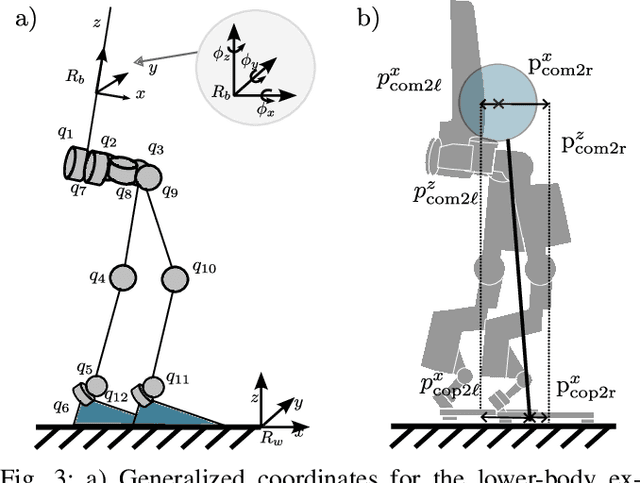
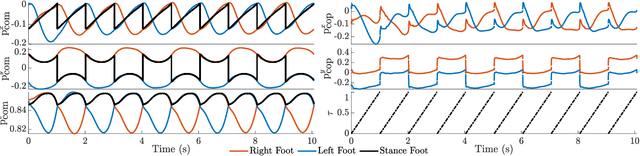
Exoskeleton locomotion must be robust while being adaptive to different users with and without payloads. To address these challenges, this work introduces a data-driven predictive control (DDPC) framework to synthesize walking gaits for lower-body exoskeletons, employing Hankel matrices and a state transition matrix for its data-driven model. The proposed approach leverages DDPC through a multi-layer architecture. At the top layer, DDPC serves as a planner employing Hankel matrices and a state transition matrix to generate a data-driven model that can learn and adapt to varying users and payloads. At the lower layer, our method incorporates inverse kinematics and passivity-based control to map the planned trajectory from DDPC into the full-order states of the lower-body exoskeleton. We validate the effectiveness of this approach through numerical simulations and hardware experiments conducted on the Atalante lower-body exoskeleton with different payloads. Moreover, we conducted a comparative analysis against the model predictive control (MPC) framework based on the reduced-order linear inverted pendulum (LIP) model. Through this comparison, the paper demonstrates that DDPC enables robust bipedal walking at various velocities while accounting for model uncertainties and unknown perturbations.
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
Mar 02, 2024



This paper introduces SceneCraft, a Large Language Model (LLM) Agent converting text descriptions into Blender-executable Python scripts which render complex scenes with up to a hundred 3D assets. This process requires complex spatial planning and arrangement. We tackle these challenges through a combination of advanced abstraction, strategic planning, and library learning. SceneCraft first models a scene graph as a blueprint, detailing the spatial relationships among assets in the scene. SceneCraft then writes Python scripts based on this graph, translating relationships into numerical constraints for asset layout. Next, SceneCraft leverages the perceptual strengths of vision-language foundation models like GPT-V to analyze rendered images and iteratively refine the scene. On top of this process, SceneCraft features a library learning mechanism that compiles common script functions into a reusable library, facilitating continuous self-improvement without expensive LLM parameter tuning. Our evaluation demonstrates that SceneCraft surpasses existing LLM-based agents in rendering complex scenes, as shown by its adherence to constraints and favorable human assessments. We also showcase the broader application potential of SceneCraft by reconstructing detailed 3D scenes from the Sintel movie and guiding a video generative model with generated scenes as intermediary control signal.
Generalizability Under Sensor Failure: Tokenization + Transformers Enable More Robust Latent Spaces
Feb 29, 2024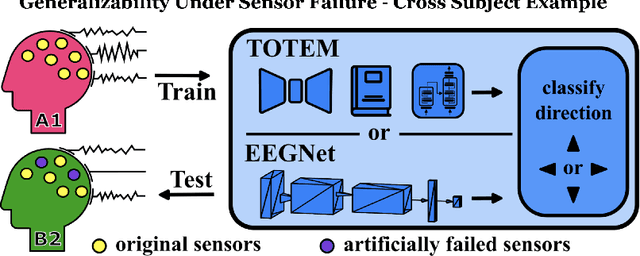
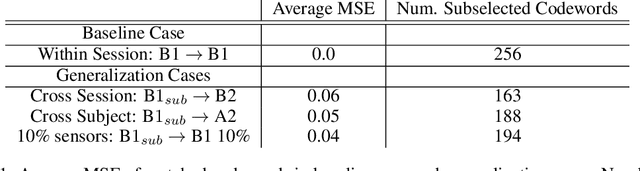
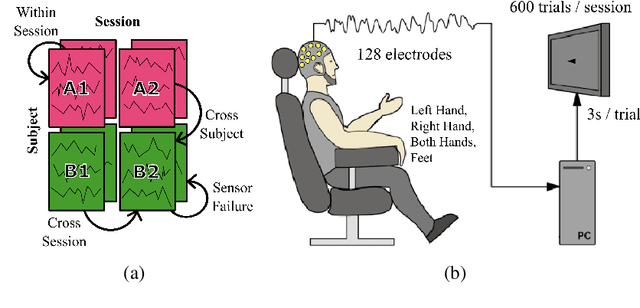
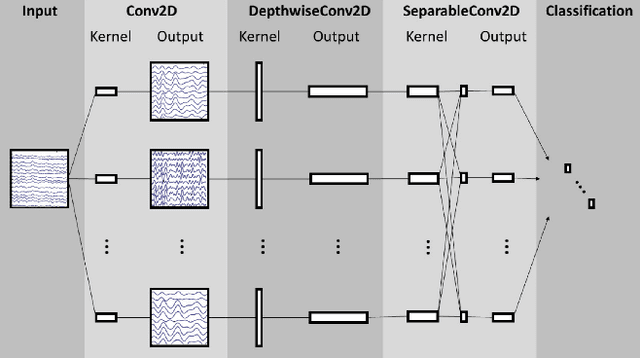
A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization
TOTEM: TOkenized Time Series EMbeddings for General Time Series Analysis
Feb 26, 2024



The field of general time series analysis has recently begun to explore unified modeling, where a common architectural backbone can be retrained on a specific task for a specific dataset. In this work, we approach unification from a complementary vantage point: unification across tasks and domains. To this end, we explore the impact of discrete, learnt, time series data representations that enable generalist, cross-domain training. Our method, TOTEM, or TOkenized Time Series EMbeddings, proposes a simple tokenizer architecture that embeds time series data from varying domains using a discrete vectorized representation learned in a self-supervised manner. TOTEM works across multiple tasks and domains with minimal to no tuning. We study the efficacy of TOTEM with an extensive evaluation on 17 real world time series datasets across 3 tasks. We evaluate both the specialist (i.e., training a model on each domain) and generalist (i.e., training a single model on many domains) settings, and show that TOTEM matches or outperforms previous best methods on several popular benchmarks. The code can be found at: https://github.com/SaberaTalukder/TOTEM.