 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Time-Scale Invariant Population-Level Neural Representations
Nov 17, 2025



General-purpose foundation models for neural time series can help accelerate neuroscientific discoveries and enable applications such as brain computer interfaces (BCIs). A key component in scaling these models is population-level representation learning, which leverages information across channels to capture spatial as well as temporal structure. Population-level approaches have recently shown that such representations can be both efficient to learn on top of pretrained temporal encoders and produce useful representations for decoding a variety of downstream tasks. However, these models remain sensitive to mismatches in preprocessing, particularly on time-scales, between pretraining and downstream settings. We systematically examine how time-scale mismatches affects generalization and find that existing representations lack invariance. To address this, we introduce Time-scale Augmented Pretraining (TSAP), which consistently improves robustness to different time-scales across decoding tasks and builds invariance in the representation space. These results highlight handling preprocessing diversity as a key step toward building generalizable neural foundation models.
Learning the relative composition of EEG signals using pairwise relative shift pretraining
Nov 14, 2025Self-supervised learning (SSL) offers a promising approach for learning electroencephalography (EEG) representations from unlabeled data, reducing the need for expensive annotations for clinical applications like sleep staging and seizure detection. While current EEG SSL methods predominantly use masked reconstruction strategies like masked autoencoders (MAE) that capture local temporal patterns, position prediction pretraining remains underexplored despite its potential to learn long-range dependencies in neural signals. We introduce PAirwise Relative Shift or PARS pretraining, a novel pretext task that predicts relative temporal shifts between randomly sampled EEG window pairs. Unlike reconstruction-based methods that focus on local pattern recovery, PARS encourages encoders to capture relative temporal composition and long-range dependencies inherent in neural signals. Through comprehensive evaluation on various EEG decoding tasks, we demonstrate that PARS-pretrained transformers consistently outperform existing pretraining strategies in label-efficient and transfer learning settings, establishing a new paradigm for self-supervised EEG representation learning.
Population Transformer: Learning Population-level Representations of Intracranial Activity
Jun 05, 2024



We present a self-supervised framework that learns population-level codes for intracranial neural recordings at scale, unlocking the benefits of representation learning for a key neuroscience recording modality. The Population Transformer (PopT) lowers the amount of data required for decoding experiments, while increasing accuracy, even on never-before-seen subjects and tasks. We address two key challenges in developing PopT: sparse electrode distribution and varying electrode location across patients. PopT stacks on top of pretrained representations and enhances downstream tasks by enabling learned aggregation of multiple spatially-sparse data channels. Beyond decoding, we interpret the pretrained PopT and fine-tuned models to show how it can be used to provide neuroscience insights learned from massive amounts of data. We release a pretrained PopT to enable off-the-shelf improvements in multi-channel intracranial data decoding and interpretability, and code is available at https://github.com/czlwang/PopulationTransformer.
Generalizability Under Sensor Failure: Tokenization + Transformers Enable More Robust Latent Spaces
Feb 29, 2024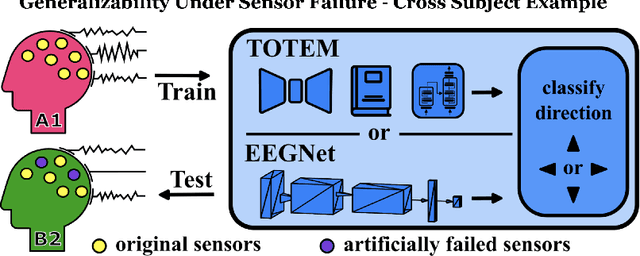
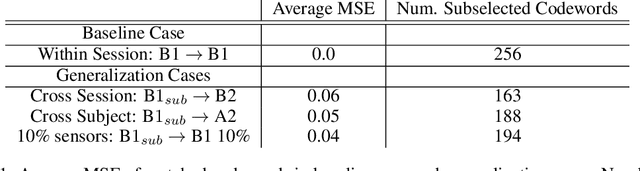
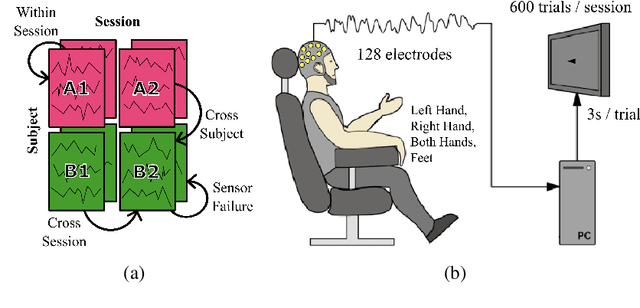
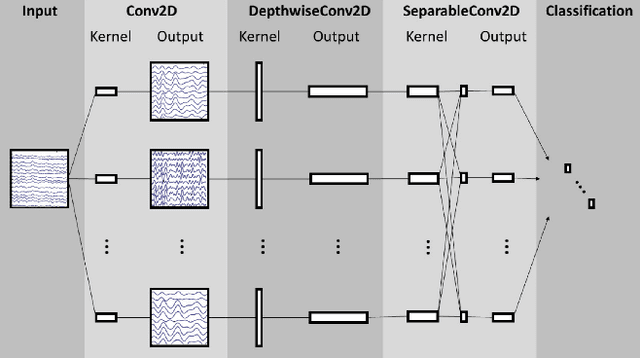
A major goal in neuroscience is to discover neural data representations that generalize. This goal is challenged by variability along recording sessions (e.g. environment), subjects (e.g. varying neural structures), and sensors (e.g. sensor noise), among others. Recent work has begun to address generalization across sessions and subjects, but few study robustness to sensor failure which is highly prevalent in neuroscience experiments. In order to address these generalizability dimensions we first collect our own electroencephalography dataset with numerous sessions, subjects, and sensors, then study two time series models: EEGNet (Lawhern et al., 2018) and TOTEM (Talukder et al., 2024). EEGNet is a widely used convolutional neural network, while TOTEM is a discrete time series tokenizer and transformer model. We find that TOTEM outperforms or matches EEGNet across all generalizability cases. Finally through analysis of TOTEM's latent codebook we observe that tokenization enables generalization