 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainBits: How Much of the Brain are Generative Reconstruction Methods Using?
Nov 05, 2024



When evaluating stimuli reconstruction results it is tempting to assume that higher fidelity text and image generation is due to an improved understanding of the brain or more powerful signal extraction from neural recordings. However, in practice, new reconstruction methods could improve performance for at least three other reasons: learning more about the distribution of stimuli, becoming better at reconstructing text or images in general, or exploiting weaknesses in current image and/or text evaluation metrics. Here we disentangle how much of the reconstruction is due to these other factors vs. productively using the neural recordings. We introduce BrainBits, a method that uses a bottleneck to quantify the amount of signal extracted from neural recordings that is actually necessary to reproduce a method's reconstruction fidelity. We find that it takes surprisingly little information from the brain to produce reconstructions with high fidelity. In these cases, it is clear that the priors of the methods' generative models are so powerful that the outputs they produce extrapolate far beyond the neural signal they decode. Given that reconstructing stimuli can be improved independently by either improving signal extraction from the brain or by building more powerful generative models, improving the latter may fool us into thinking we are improving the former. We propose that methods should report a method-specific random baseline, a reconstruction ceiling, and a curve of performance as a function of bottleneck size, with the ultimate goal of using more of the neural recordings.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Jun 20, 2024



We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
Population Transformer: Learning Population-level Representations of Intracranial Activity
Jun 05, 2024



We present a self-supervised framework that learns population-level codes for intracranial neural recordings at scale, unlocking the benefits of representation learning for a key neuroscience recording modality. The Population Transformer (PopT) lowers the amount of data required for decoding experiments, while increasing accuracy, even on never-before-seen subjects and tasks. We address two key challenges in developing PopT: sparse electrode distribution and varying electrode location across patients. PopT stacks on top of pretrained representations and enhances downstream tasks by enabling learned aggregation of multiple spatially-sparse data channels. Beyond decoding, we interpret the pretrained PopT and fine-tuned models to show how it can be used to provide neuroscience insights learned from massive amounts of data. We release a pretrained PopT to enable off-the-shelf improvements in multi-channel intracranial data decoding and interpretability, and code is available at https://github.com/czlwang/PopulationTransformer.
Operator learning for hyperbolic partial differential equations
Dec 29, 2023


We construct the first rigorously justified probabilistic algorithm for recovering the solution operator of a hyperbolic partial differential equation (PDE) in two variables from input-output training pairs. The primary challenge of recovering the solution operator of hyperbolic PDEs is the presence of characteristics, along which the associated Green's function is discontinuous. Therefore, a central component of our algorithm is a rank detection scheme that identifies the approximate location of the characteristics. By combining the randomized singular value decomposition with an adaptive hierarchical partition of the domain, we construct an approximant to the solution operator using $O(\Psi_\epsilon^{-1}\epsilon^{-7}\log(\Xi_\epsilon^{-1}\epsilon^{-1}))$ input-output pairs with relative error $O(\Xi_\epsilon^{-1}\epsilon)$ in the operator norm as $\epsilon\to0$, with high probability. Here, $\Psi_\epsilon$ represents the existence of degenerate singular values of the solution operator, and $\Xi_\epsilon$ measures the quality of the training data. Our assumptions on the regularity of the coefficients of the hyperbolic PDE are relatively weak given that hyperbolic PDEs do not have the ``instantaneous smoothing effect'' of elliptic and parabolic PDEs, and our recovery rate improves as the regularity of the coefficients increases.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023



We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Learning a natural-language to LTL executable semantic parser for grounded robotics
Aug 11, 2020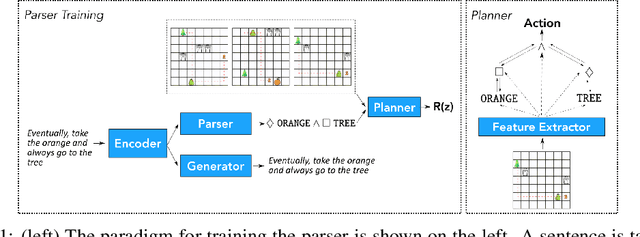
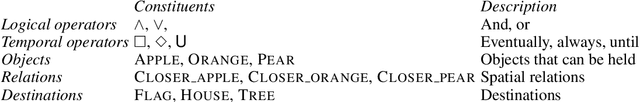
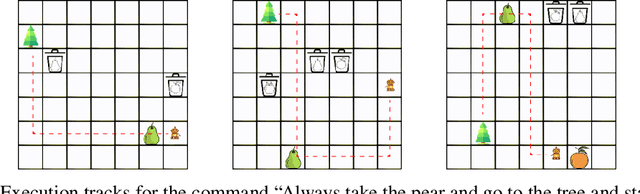
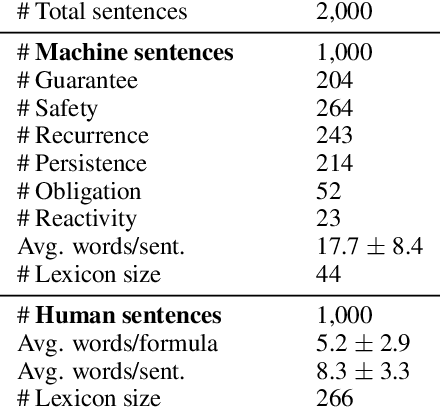
Children acquire their native language with apparent ease by observing how language is used in context and attempting to use it themselves. They do so without laborious annotations, negative examples, or even direct corrections. We take a step toward robots that can do the same by training a grounded semantic parser, which discovers latent linguistic representations that can be used for the execution of natural-language commands. In particular, we focus on the difficult domain of commands with a temporal aspect, whose semantics we capture with Linear Temporal Logic, LTL. Our parser is trained with pairs of sentences and executions as well as an executor. At training time, the parser hypothesizes a meaning representation for the input as a formula in LTL. Three competing pressures allow the parser to discover meaning from language. First, any hypothesized meaning for a sentence must be permissive enough to reflect all the annotated execution trajectories. Second, the executor -- a pretrained end-to-end LTL planner -- must find that the observed trajectories are likely executions of the meaning. Finally, a generator, which reconstructs the original input, encourages the model to find representations that conserve knowledge about the command. Together these ensure that the meaning is neither too general nor too specific. Our model generalizes well, being able to parse and execute both machine-generated and human-generated commands, with near-equal accuracy, despite the fact that the human-generated sentences are much more varied and complex with an open lexicon. The approach presented here is not specific to LTL; it can be applied to any domain where sentence meanings can be hypothesized and an executor can verify these meanings, thus opening the door to many applications for robotic agents.