 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Data-Driven Predictive Control for Robust and Reactive Exoskeleton Locomotion Synthesis
Aug 14, 2025Robust bipedal locomotion in exoskeletons requires the ability to dynamically react to changes in the environment in real time. This paper introduces the hybrid data-driven predictive control (HDDPC) framework, an extension of the data-enabled predictive control, that addresses these challenges by simultaneously planning foot contact schedules and continuous domain trajectories. The proposed framework utilizes a Hankel matrix-based representation to model system dynamics, incorporating step-to-step (S2S) transitions to enhance adaptability in dynamic environments. By integrating contact scheduling with trajectory planning, the framework offers an efficient, unified solution for locomotion motion synthesis that enables robust and reactive walking through online replanning. We validate the approach on the Atalante exoskeleton, demonstrating improved robustness and adaptability.
Langevin Flows for Modeling Neural Latent Dynamics
Jul 15, 2025



Neural populations exhibit latent dynamical structures that drive time-evolving spiking activities, motivating the search for models that capture both intrinsic network dynamics and external unobserved influences. In this work, we introduce LangevinFlow, a sequential Variational Auto-Encoder where the time evolution of latent variables is governed by the underdamped Langevin equation. Our approach incorporates physical priors -- such as inertia, damping, a learned potential function, and stochastic forces -- to represent both autonomous and non-autonomous processes in neural systems. Crucially, the potential function is parameterized as a network of locally coupled oscillators, biasing the model toward oscillatory and flow-like behaviors observed in biological neural populations. Our model features a recurrent encoder, a one-layer Transformer decoder, and Langevin dynamics in the latent space. Empirically, our method outperforms state-of-the-art baselines on synthetic neural populations generated by a Lorenz attractor, closely matching ground-truth firing rates. On the Neural Latents Benchmark (NLB), the model achieves superior held-out neuron likelihoods (bits per spike) and forward prediction accuracy across four challenging datasets. It also matches or surpasses alternative methods in decoding behavioral metrics such as hand velocity. Overall, this work introduces a flexible, physics-inspired, high-performing framework for modeling complex neural population dynamics and their unobserved influences.
Escaping Platos Cave: JAM for Aligning Independently Trained Vision and Language Models
Jul 01, 2025Independently trained vision and language models inhabit disjoint representational spaces, shaped by their respective modalities, objectives, and architectures. Yet an emerging hypothesis - the Platonic Representation Hypothesis - suggests that such models may nonetheless converge toward a shared statistical model of reality. This compatibility, if it exists, raises a fundamental question: can we move beyond post-hoc statistical detection of alignment and explicitly optimize for it between such disjoint representations? We cast this Platonic alignment problem as a multi-objective optimization task - preserve each modality's native structure while aligning for mutual coherence. We introduce the Joint Autoencoder Modulator (JAM) framework that jointly trains modality-specific autoencoders on the latent representations of pre-trained single modality models, encouraging alignment through both reconstruction and cross-modal objectives. By analogy, this framework serves as a method to escape Plato's Cave, enabling the emergence of shared structure from disjoint inputs. We evaluate this framework across three critical design axes: (i) the alignment objective - comparing contrastive loss (Con), its hard-negative variant (NegCon), and our Spread loss, (ii) the layer depth at which alignment is most effective, and (iii) the impact of foundation model scale on representational convergence. Our findings show that our lightweight Pareto-efficient framework reliably induces alignment, even across frozen, independently trained representations, offering both theoretical insight and practical pathways for transforming generalist unimodal foundations into specialist multimodal models.
Steering Generative Models with Experimental Data for Protein Fitness Optimization
May 21, 2025Protein fitness optimization involves finding a protein sequence that maximizes desired quantitative properties in a combinatorially large design space of possible sequences. Recent developments in steering protein generative models (e.g diffusion models, language models) offer a promising approach. However, by and large, past studies have optimized surrogate rewards and/or utilized large amounts of labeled data for steering, making it unclear how well existing methods perform and compare to each other in real-world optimization campaigns where fitness is measured by low-throughput wet-lab assays. In this study, we explore fitness optimization using small amounts (hundreds) of labeled sequence-fitness pairs and comprehensively evaluate strategies such as classifier guidance and posterior sampling for guiding generation from different discrete diffusion models of protein sequences. We also demonstrate how guidance can be integrated into adaptive sequence selection akin to Thompson sampling in Bayesian optimization, showing that plug-and-play guidance strategies offer advantages compared to alternatives such as reinforcement learning with protein language models.
CLEVER: A Curated Benchmark for Formally Verified Code Generation
May 21, 2025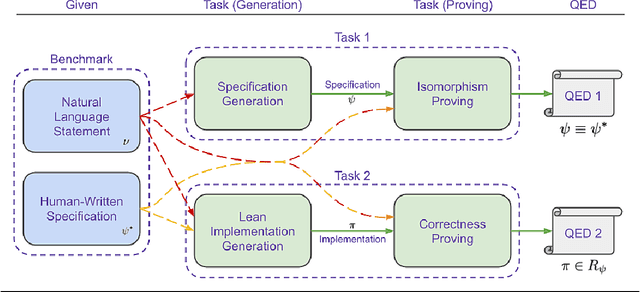
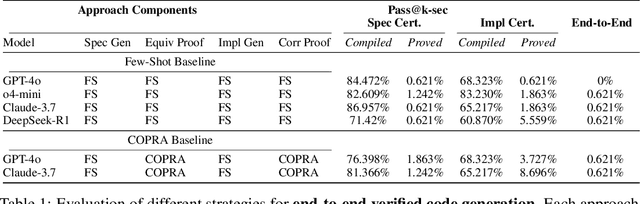

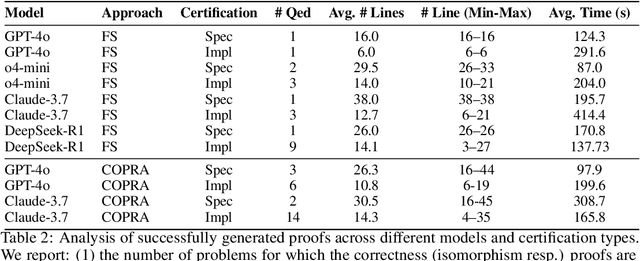
We introduce ${\rm C{\small LEVER}}$, a high-quality, curated benchmark of 161 problems for end-to-end verified code generation in Lean. Each problem consists of (1) the task of generating a specification that matches a held-out ground-truth specification, and (2) the task of generating a Lean implementation that provably satisfies this specification. Unlike prior benchmarks, ${\rm C{\small LEVER}}$ avoids test-case supervision, LLM-generated annotations, and specifications that leak implementation logic or allow vacuous solutions. All outputs are verified post-hoc using Lean's type checker to ensure machine-checkable correctness. We use ${\rm C{\small LEVER}}$ to evaluate several few-shot and agentic approaches based on state-of-the-art language models. These methods all struggle to achieve full verification, establishing it as a challenging frontier benchmark for program synthesis and formal reasoning. Our benchmark can be found on GitHub(https://github.com/trishullab/clever) as well as HuggingFace(https://huggingface.co/datasets/amitayusht/clever). All our evaluation code is also available online(https://github.com/trishullab/clever-prover).
STeP: A General and Scalable Framework for Solving Video Inverse Problems with Spatiotemporal Diffusion Priors
Apr 10, 2025We study how to solve general Bayesian inverse problems involving videos using diffusion model priors. While it is desirable to use a video diffusion prior to effectively capture complex temporal relationships, due to the computational and data requirements of training such a model, prior work has instead relied on image diffusion priors on single frames combined with heuristics to enforce temporal consistency. However, these approaches struggle with faithfully recovering the underlying temporal relationships, particularly for tasks with high temporal uncertainty. In this paper, we demonstrate the feasibility of practical and accessible spatiotemporal diffusion priors by fine-tuning latent video diffusion models from pretrained image diffusion models using limited videos in specific domains. Leveraging this plug-and-play spatiotemporal diffusion prior, we introduce a general and scalable framework for solving video inverse problems. We then apply our framework to two challenging scientific video inverse problems--black hole imaging and dynamic MRI. Our framework enables the generation of diverse, high-fidelity video reconstructions that not only fit observations but also recover multi-modal solutions. By incorporating a spatiotemporal diffusion prior, we significantly improve our ability to capture complex temporal relationships in the data while also enhancing spatial fidelity.
Self-Evolving Visual Concept Library using Vision-Language Critics
Mar 31, 2025We study the problem of building a visual concept library for visual recognition. Building effective visual concept libraries is challenging, as manual definition is labor-intensive, while relying solely on LLMs for concept generation can result in concepts that lack discriminative power or fail to account for the complex interactions between them. Our approach, ESCHER, takes a library learning perspective to iteratively discover and improve visual concepts. ESCHER uses a vision-language model (VLM) as a critic to iteratively refine the concept library, including accounting for interactions between concepts and how they affect downstream classifiers. By leveraging the in-context learning abilities of LLMs and the history of performance using various concepts, ESCHER dynamically improves its concept generation strategy based on the VLM critic's feedback. Finally, ESCHER does not require any human annotations, and is thus an automated plug-and-play framework. We empirically demonstrate the ability of ESCHER to learn a concept library for zero-shot, few-shot, and fine-tuning visual classification tasks. This work represents, to our knowledge, the first application of concept library learning to real-world visual tasks.
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
Mar 14, 2025



Plug-and-play diffusion priors (PnPDP) have emerged as a promising research direction for solving inverse problems. However, current studies primarily focus on natural image restoration, leaving the performance of these algorithms in scientific inverse problems largely unexplored. To address this gap, we introduce \textsc{InverseBench}, a framework that evaluates diffusion models across five distinct scientific inverse problems. These problems present unique structural challenges that differ from existing benchmarks, arising from critical scientific applications such as optical tomography, medical imaging, black hole imaging, seismology, and fluid dynamics. With \textsc{InverseBench}, we benchmark 14 inverse problem algorithms that use plug-and-play diffusion priors against strong, domain-specific baselines, offering valuable new insights into the strengths and weaknesses of existing algorithms. To facilitate further research and development, we open-source the codebase, along with datasets and pre-trained models, at https://devzhk.github.io/InverseBench/.
Split Gibbs Discrete Diffusion Posterior Sampling
Mar 03, 2025We study the problem of posterior sampling in discrete-state spaces using discrete diffusion models. While posterior sampling methods for continuous diffusion models have achieved remarkable progress, analogous methods for discrete diffusion models remain challenging. In this work, we introduce a principled plug-and-play discrete diffusion posterior sampling algorithm based on split Gibbs sampling, which we call SG-DPS. Our algorithm enables reward-guided generation and solving inverse problems in discrete-state spaces. We demonstrate that SG-DPS converges to the true posterior distribution on synthetic benchmarks, and enjoys state-of-the-art posterior sampling performance on a range of benchmarks for discrete data, achieving up to 2x improved performance compared to existing baselines.
DataSciBench: An LLM Agent Benchmark for Data Science
Feb 19, 2025



This paper presents DataSciBench, a comprehensive benchmark for evaluating Large Language Model (LLM) capabilities in data science. Recent related benchmarks have primarily focused on single tasks, easily obtainable ground truth, and straightforward evaluation metrics, which limits the scope of tasks that can be evaluated. In contrast, DataSciBench is constructed based on a more comprehensive and curated collection of natural and challenging prompts for uncertain ground truth and evaluation metrics. We develop a semi-automated pipeline for generating ground truth (GT) and validating evaluation metrics. This pipeline utilizes and implements an LLM-based self-consistency and human verification strategy to produce accurate GT by leveraging collected prompts, predefined task types, and aggregate functions (metrics). Furthermore, we propose an innovative Task - Function - Code (TFC) framework to assess each code execution outcome based on precisely defined metrics and programmatic rules. Our experimental framework involves testing 6 API-based models, 8 open-source general models, and 9 open-source code generation models using the diverse set of prompts we have gathered. This approach aims to provide a more comprehensive and rigorous evaluation of LLMs in data science, revealing their strengths and weaknesses. Experimental results demonstrate that API-based models outperform open-sourced models on all metrics and Deepseek-Coder-33B-Instruct achieves the highest score among open-sourced models. We release all code and data at https://github.com/THUDM/DataSciBench.