 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching LLMs Program Semantics via Symbolic Execution Traces
May 07, 2026We introduce an evaluation framework of 500 C verification tasks across five property types (memory safety, overflow, termination, reachability, data races) built on SV-COMP 2025, and evaluate 14 models across six families. We find that high overall accuracy masks a critical weakness: while most models reliably confirm properties hold, violation detection varies widely and degrades sharply with program length. To close this gap, we train on formal verification artifacts: running the Soteria symbolic execution engine on generic open-source C code and using the resulting traces for continued pretraining of Qwen3-8B. Just ${\sim}$3,000 bug traces combined with chain-of-thought reasoning at inference time improve violation detection by over 17 percentage points, producing one of the most balanced accuracy profiles among evaluated models. On violation detection, the trained 8B model outperforms the 4$\times$ larger Qwen3-32B without thinking and approaches it in overall accuracy. The interaction between trace training and chain-of-thought is superadditive: neither alone provides meaningful gains, but their combination does. Improvements transfer across all five property types, including ones the training traces do not target. Our 28 configurations confirm the gains stem from trace semantics, not code volume, and that trace curation and format matter.
MiniF2F-Dafny: LLM-Guided Mathematical Theorem Proving via Auto-Active Verification
Dec 11, 2025We present miniF2F-Dafny, the first translation of the mathematical reasoning benchmark miniF2F to an automated theorem prover: Dafny. Previously, the benchmark existed only in interactive theorem provers (Lean, Isabelle, HOL Light, Metamath). We find that Dafny's automation verifies 99/244 (40.6%) of the test set and 109/244 (44.7%) of the validation set with empty proofs--requiring no manual proof steps. For problems where empty proofs fail, we evaluate 12 off-the-shelf LLMs on providing proof hints. The best model we test achieves 55.7% pass@4 success rate employing iterative error correction. These preliminary results highlight an effective division of labor: LLMs provide high-level guidance while automation handles low-level details. Our benchmark can be found on GitHub at http://github.com/dafny-lang/miniF2F .
CLEVER: A Curated Benchmark for Formally Verified Code Generation
May 21, 2025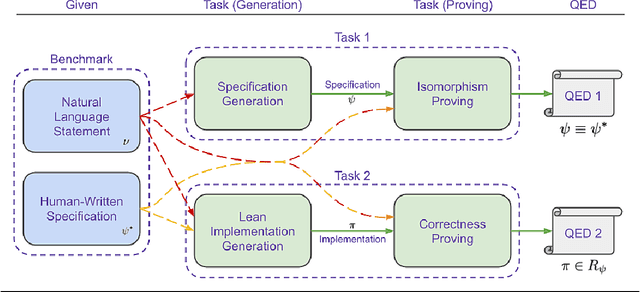
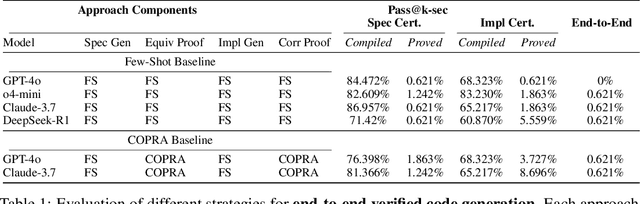

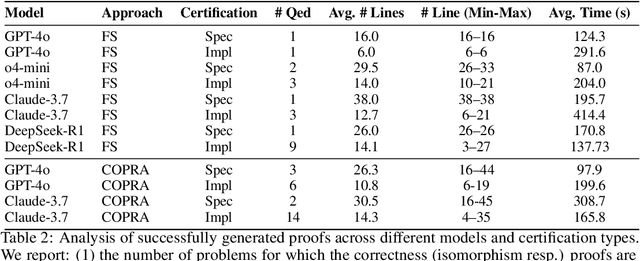
We introduce ${\rm C{\small LEVER}}$, a high-quality, curated benchmark of 161 problems for end-to-end verified code generation in Lean. Each problem consists of (1) the task of generating a specification that matches a held-out ground-truth specification, and (2) the task of generating a Lean implementation that provably satisfies this specification. Unlike prior benchmarks, ${\rm C{\small LEVER}}$ avoids test-case supervision, LLM-generated annotations, and specifications that leak implementation logic or allow vacuous solutions. All outputs are verified post-hoc using Lean's type checker to ensure machine-checkable correctness. We use ${\rm C{\small LEVER}}$ to evaluate several few-shot and agentic approaches based on state-of-the-art language models. These methods all struggle to achieve full verification, establishing it as a challenging frontier benchmark for program synthesis and formal reasoning. Our benchmark can be found on GitHub(https://github.com/trishullab/clever) as well as HuggingFace(https://huggingface.co/datasets/amitayusht/clever). All our evaluation code is also available online(https://github.com/trishullab/clever-prover).
Dafny as Verification-Aware Intermediate Language for Code Generation
Jan 10, 2025



Using large language models (LLMs) to generate source code from natural language prompts is a popular and promising idea with a wide range of applications. One of its limitations is that the generated code can be faulty at times, often in a subtle way, despite being presented to the user as correct. In this paper, we explore ways in which formal methods can assist with increasing the quality of code generated by an LLM. Instead of emitting code in a target language directly, we propose that the user guides the LLM to first generate an opaque intermediate representation, in the verification-aware language Dafny, that can be automatically validated for correctness against agreed on specifications. The correct Dafny program is then compiled to the target language and returned to the user. All user-system interactions throughout the procedure occur via natural language; Dafny code is never exposed. We describe our current prototype and report on its performance on the HumanEval Python code generation benchmarks.