 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Multimodal Protein Design Enables DNA-Encoding of Chemistry
Apr 06, 2026Evolution is an extraordinary engine for enzymatic diversity, yet the chemistry it has explored remains a narrow slice of what DNA can encode. Deep generative models can design new proteins that bind ligands, but none have created enzymes without pre-specifying catalytic residues. We introduce DISCO (DIffusion for Sequence-structure CO-design), a multimodal model that co-designs protein sequence and 3D structure around arbitrary biomolecules, as well as inference-time scaling methods that optimize objectives across both modalities. Conditioned solely on reactive intermediates, DISCO designs diverse heme enzymes with novel active-site geometries. These enzymes catalyze new-to-nature carbene-transfer reactions, including alkene cyclopropanation, spirocyclopropanation, B-H, and C(sp$^3$)-H insertions, with high activities exceeding those of engineered enzymes. Random mutagenesis of a selected design further confirmed that enzyme activity can be improved through directed evolution. By providing a scalable route to evolvable enzymes, DISCO broadens the potential scope of genetically encodable transformations. Code is available at https://github.com/DISCO-design/DISCO.
Steering Generative Models with Experimental Data for Protein Fitness Optimization
May 21, 2025Protein fitness optimization involves finding a protein sequence that maximizes desired quantitative properties in a combinatorially large design space of possible sequences. Recent developments in steering protein generative models (e.g diffusion models, language models) offer a promising approach. However, by and large, past studies have optimized surrogate rewards and/or utilized large amounts of labeled data for steering, making it unclear how well existing methods perform and compare to each other in real-world optimization campaigns where fitness is measured by low-throughput wet-lab assays. In this study, we explore fitness optimization using small amounts (hundreds) of labeled sequence-fitness pairs and comprehensively evaluate strategies such as classifier guidance and posterior sampling for guiding generation from different discrete diffusion models of protein sequences. We also demonstrate how guidance can be integrated into adaptive sequence selection akin to Thompson sampling in Bayesian optimization, showing that plug-and-play guidance strategies offer advantages compared to alternatives such as reinforcement learning with protein language models.
Protein sequence design with deep generative models
Apr 09, 2021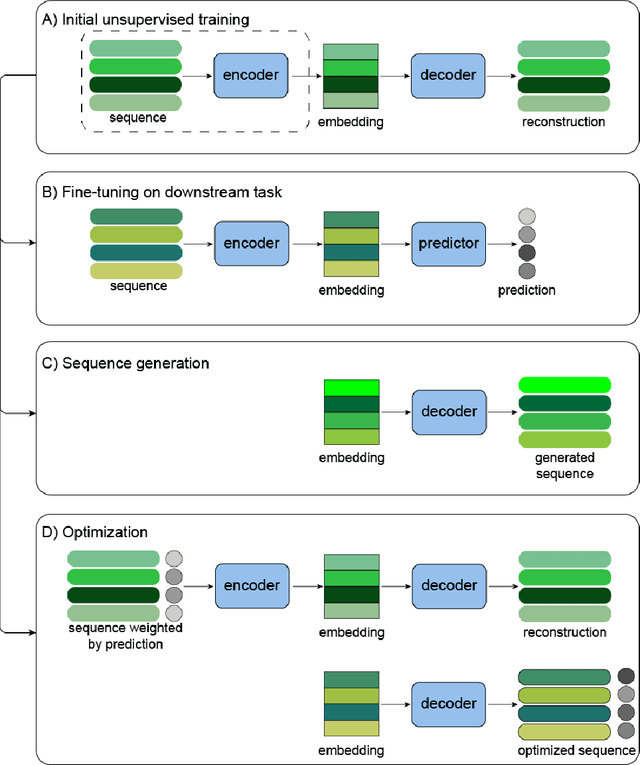
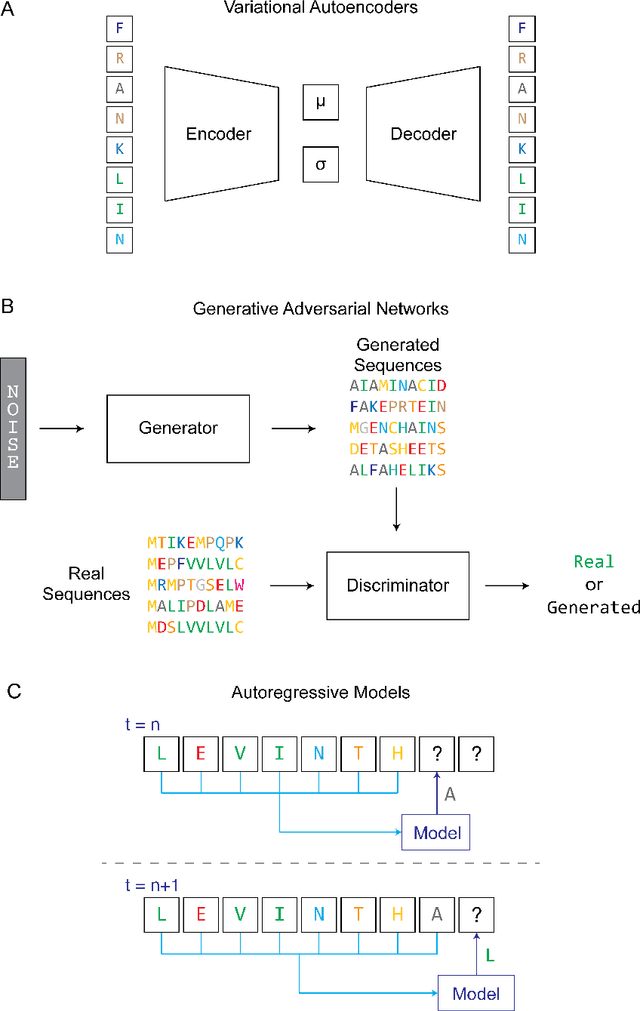
Protein engineering seeks to identify protein sequences with optimized properties. When guided by machine learning, protein sequence generation methods can draw on prior knowledge and experimental efforts to improve this process. In this review, we highlight recent applications of machine learning to generate protein sequences, focusing on the emerging field of deep generative methods.