 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verified Code Reasoning by LLMs
Sep 30, 2025



While LLM-based agents are able to tackle a wide variety of code reasoning questions, the answers are not always correct. This prevents the agent from being useful in situations where high precision is desired: (1) helping a software engineer understand a new code base, (2) helping a software engineer during code review sessions, and (3) ensuring that the code generated by an automated code generation system meets certain requirements (e.g. fixes a bug, improves readability, implements a feature). As a result of this lack of trustworthiness, the agent's answers need to be manually verified before they can be trusted. Manually confirming responses from a code reasoning agent requires human effort and can result in slower developer productivity, which weakens the assistance benefits of the agent. In this paper, we describe a method to automatically validate the answers provided by a code reasoning agent by verifying its reasoning steps. At a very high level, the method consists of extracting a formal representation of the agent's response and, subsequently, using formal verification and program analysis tools to verify the agent's reasoning steps. We applied this approach to a benchmark set of 20 uninitialized variable errors detected by sanitizers and 20 program equivalence queries. For the uninitialized variable errors, the formal verification step was able to validate the agent's reasoning on 13/20 examples, and for the program equivalence queries, the formal verification step successfully caught 6/8 incorrect judgments made by the agent.
CLEVER: A Curated Benchmark for Formally Verified Code Generation
May 21, 2025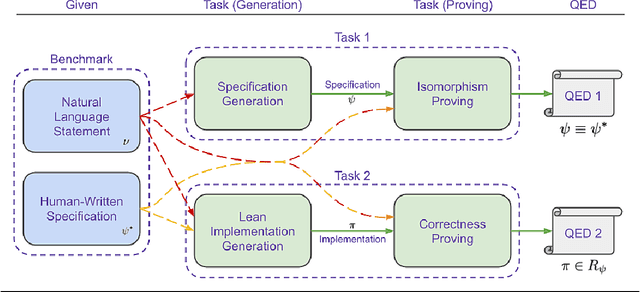
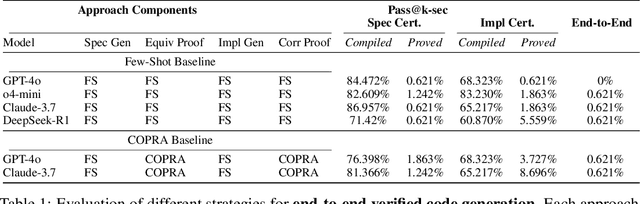

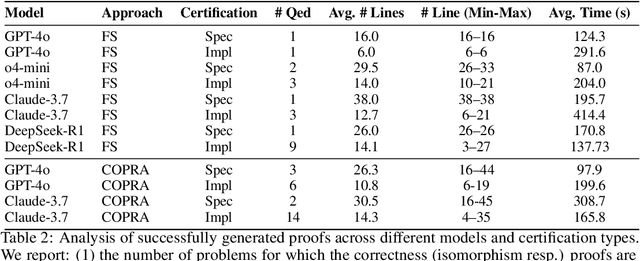
We introduce ${\rm C{\small LEVER}}$, a high-quality, curated benchmark of 161 problems for end-to-end verified code generation in Lean. Each problem consists of (1) the task of generating a specification that matches a held-out ground-truth specification, and (2) the task of generating a Lean implementation that provably satisfies this specification. Unlike prior benchmarks, ${\rm C{\small LEVER}}$ avoids test-case supervision, LLM-generated annotations, and specifications that leak implementation logic or allow vacuous solutions. All outputs are verified post-hoc using Lean's type checker to ensure machine-checkable correctness. We use ${\rm C{\small LEVER}}$ to evaluate several few-shot and agentic approaches based on state-of-the-art language models. These methods all struggle to achieve full verification, establishing it as a challenging frontier benchmark for program synthesis and formal reasoning. Our benchmark can be found on GitHub(https://github.com/trishullab/clever) as well as HuggingFace(https://huggingface.co/datasets/amitayusht/clever). All our evaluation code is also available online(https://github.com/trishullab/clever-prover).