 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpNet: Enhancing MLPs to Represent Functions with Controlled Non-differentiability
Jan 27, 2026Multi-layer perceptrons (MLPs) are a standard tool for learning and function approximation, but they inherently yield outputs that are globally smooth. As a result, they struggle to represent functions that are continuous yet deliberately non-differentiable (i.e., with prescribed $C^0$ sharp features) without relying on ad hoc post-processing. We present SharpNet, a modified MLP architecture capable of encoding functions with user-defined sharp features by enriching the network with an auxiliary feature function, which is defined as the solution to a Poisson equation with jump Neumann boundary conditions. It is evaluated via an efficient local integral that is fully differentiable with respect to the feature locations, enabling our method to jointly optimize both the feature locations and the MLP parameters to recover the target functions/models. The $C^0$-continuity of SharpNet is precisely controllable, ensuring $C^0$-continuity at the feature locations and smoothness elsewhere. We validate SharpNet on 2D problems and 3D CAD model reconstruction, and compare it against several state-of-the-art baselines. In both types of tasks, SharpNet accurately recovers sharp edges and corners while maintaining smooth behavior away from those features, whereas existing methods tend to smooth out gradient discontinuities. Both qualitative and quantitative evaluations highlight the benefits of our approach.
ForeDiffusion: Foresight-Conditioned Diffusion Policy via Future View Construction for Robot Manipulation
Jan 19, 2026Diffusion strategies have advanced visual motor control by progressively denoising high-dimensional action sequences, providing a promising method for robot manipulation. However, as task complexity increases, the success rate of existing baseline models decreases considerably. Analysis indicates that current diffusion strategies are confronted with two limitations. First, these strategies only rely on short-term observations as conditions. Second, the training objective remains limited to a single denoising loss, which leads to error accumulation and causes grasping deviations. To address these limitations, this paper proposes Foresight-Conditioned Diffusion (ForeDiffusion), by injecting the predicted future view representation into the diffusion process. As a result, the policy is guided to be forward-looking, enabling it to correct trajectory deviations. Following this design, ForeDiffusion employs a dual loss mechanism, combining the traditional denoising loss and the consistency loss of future observations, to achieve the unified optimization. Extensive evaluation on the Adroit suite and the MetaWorld benchmark demonstrates that ForeDiffusion achieves an average success rate of 80% for the overall task, significantly outperforming the existing mainstream diffusion methods by 23% in complex tasks, while maintaining more stable performance across the entire tasks.
LiteGE: Lightweight Geodesic Embedding for Efficient Geodesics Computation and Non-Isometric Shape Correspondence
Dec 23, 2025Computing geodesic distances on 3D surfaces is fundamental to many tasks in 3D vision and geometry processing, with deep connections to tasks such as shape correspondence. Recent learning-based methods achieve strong performance but rely on large 3D backbones, leading to high memory usage and latency, which limit their use in interactive or resource-constrained settings. We introduce LiteGE, a lightweight approach that constructs compact, category-aware shape descriptors by applying Principal Component Analysis (PCA) to unsigned distance field (UDFs) samples at informative voxels. This descriptor is efficient to compute and removes the need for high-capacity networks. LiteGE remains robust on sparse point clouds, supporting inputs with as few as 300 points, where prior methods fail. Extensive experiments show that LiteGE reduces memory usage and inference time by up to 300$\times$ compared to existing neural approaches. In addition, by exploiting the intrinsic relationship between geodesic distance and shape correspondence, LiteGE enables fast and accurate shape matching. Our method achieves up to 1000$\times$ speedup over state-of-the-art mesh-based approaches while maintaining comparable accuracy on non-isometric shape pairs, including evaluations on point-cloud inputs.
Voronoi-Assisted Diffusion for Computing Unsigned Distance Fields from Unoriented Points
Oct 14, 2025Unsigned Distance Fields (UDFs) provide a flexible representation for 3D shapes with arbitrary topology, including open and closed surfaces, orientable and non-orientable geometries, and non-manifold structures. While recent neural approaches have shown promise in learning UDFs, they often suffer from numerical instability, high computational cost, and limited controllability. We present a lightweight, network-free method, Voronoi-Assisted Diffusion (VAD), for computing UDFs directly from unoriented point clouds. Our approach begins by assigning bi-directional normals to input points, guided by two Voronoi-based geometric criteria encoded in an energy function for optimal alignment. The aligned normals are then diffused to form an approximate UDF gradient field, which is subsequently integrated to recover the final UDF. Experiments demonstrate that VAD robustly handles watertight and open surfaces, as well as complex non-manifold and non-orientable geometries, while remaining computationally efficient and stable.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025



Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
A Survey of Deep Learning-based Point Cloud Denoising
Aug 23, 2025



Accurate 3D geometry acquisition is essential for a wide range of applications, such as computer graphics, autonomous driving, robotics, and augmented reality. However, raw point clouds acquired in real-world environments are often corrupted with noise due to various factors such as sensor, lighting, material, environment etc, which reduces geometric fidelity and degrades downstream performance. Point cloud denoising is a fundamental problem, aiming to recover clean point sets while preserving underlying structures. Classical optimization-based methods, guided by hand-crafted filters or geometric priors, have been extensively studied but struggle to handle diverse and complex noise patterns. Recent deep learning approaches leverage neural network architectures to learn distinctive representations and demonstrate strong outcomes, particularly on complex and large-scale point clouds. Provided these significant advances, this survey provides a comprehensive and up-to-date review of deep learning-based point cloud denoising methods up to August 2025. We organize the literature from two perspectives: (1) supervision level (supervised vs. unsupervised), and (2) modeling perspective, proposing a functional taxonomy that unifies diverse approaches by their denoising principles. We further analyze architectural trends both structurally and chronologically, establish a unified benchmark with consistent training settings, and evaluate methods in terms of denoising quality, surface fidelity, point distribution, and computational efficiency. Finally, we discuss open challenges and outline directions for future research in this rapidly evolving field.
Hybrid Long and Short Range Flows for Point Cloud Filtering
Aug 12, 2025Point cloud capture processes are error-prone and introduce noisy artifacts that necessitate filtering/denoising. Recent filtering methods often suffer from point clustering or noise retaining issues. In this paper, we propose Hybrid Point Cloud Filtering ($\textbf{HybridPF}$) that considers both short-range and long-range filtering trajectories when removing noise. It is well established that short range scores, given by $\nabla_{x}\log p(x_t)$, may provide the necessary displacements to move noisy points to the underlying clean surface. By contrast, long range velocity flows approximate constant displacements directed from a high noise variant patch $x_0$ towards the corresponding clean surface $x_1$. Here, noisy patches $x_t$ are viewed as intermediate states between the high noise variant and the clean patches. Our intuition is that long range information from velocity flow models can guide the short range scores to align more closely with the clean points. In turn, score models generally provide a quicker convergence to the clean surface. Specifically, we devise two parallel modules, the ShortModule and LongModule, each consisting of an Encoder-Decoder pair to respectively account for short-range scores and long-range flows. We find that short-range scores, guided by long-range features, yield filtered point clouds with good point distributions and convergence near the clean surface. We design a joint loss function to simultaneously train the ShortModule and LongModule, in an end-to-end manner. Finally, we identify a key weakness in current displacement based methods, limitations on the decoder architecture, and propose a dynamic graph convolutional decoder to improve the inference process. Comprehensive experiments demonstrate that our HybridPF achieves state-of-the-art results while enabling faster inference speed.
ESNERA: Empirical and semantic named entity alignment for named entity dataset merging
Aug 09, 2025Named Entity Recognition (NER) is a fundamental task in natural language processing. It remains a research hotspot due to its wide applicability across domains. Although recent advances in deep learning have significantly improved NER performance, they rely heavily on large, high-quality annotated datasets. However, building these datasets is expensive and time-consuming, posing a major bottleneck for further research. Current dataset merging approaches mainly focus on strategies like manual label mapping or constructing label graphs, which lack interpretability and scalability. To address this, we propose an automatic label alignment method based on label similarity. The method combines empirical and semantic similarities, using a greedy pairwise merging strategy to unify label spaces across different datasets. Experiments are conducted in two stages: first, merging three existing NER datasets into a unified corpus with minimal impact on NER performance; second, integrating this corpus with a small-scale, self-built dataset in the financial domain. The results show that our method enables effective dataset merging and enhances NER performance in the low-resource financial domain. This study presents an efficient, interpretable, and scalable solution for integrating multi-source NER corpora.
MonoCloth: Reconstruction and Animation of Cloth-Decoupled Human Avatars from Monocular Videos
Aug 06, 2025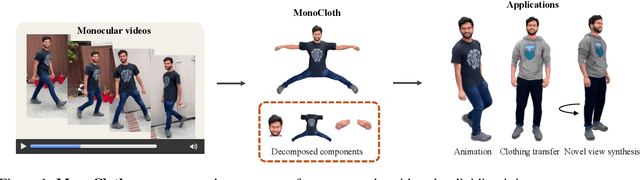
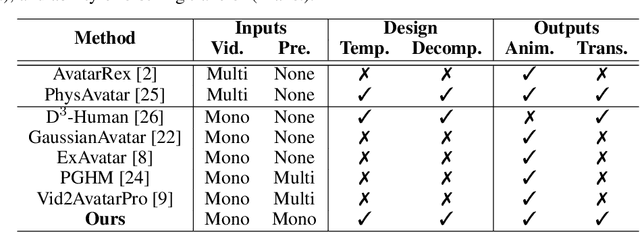
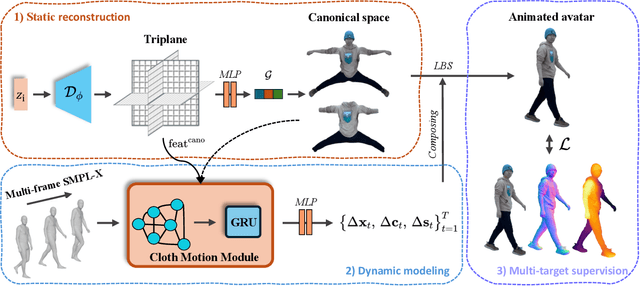
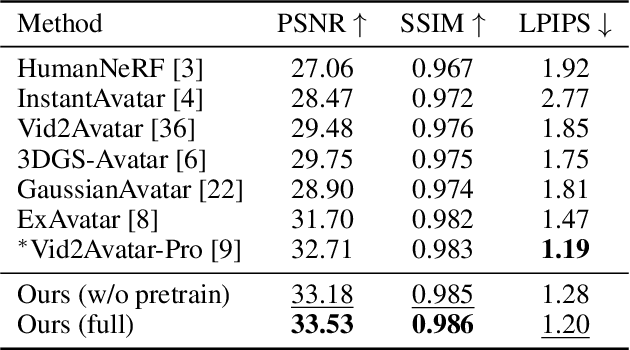
Reconstructing realistic 3D human avatars from monocular videos is a challenging task due to the limited geometric information and complex non-rigid motion involved. We present MonoCloth, a new method for reconstructing and animating clothed human avatars from monocular videos. To overcome the limitations of monocular input, we introduce a part-based decomposition strategy that separates the avatar into body, face, hands, and clothing. This design reflects the varying levels of reconstruction difficulty and deformation complexity across these components. Specifically, we focus on detailed geometry recovery for the face and hands. For clothing, we propose a dedicated cloth simulation module that captures garment deformation using temporal motion cues and geometric constraints. Experimental results demonstrate that MonoCloth improves both visual reconstruction quality and animation realism compared to existing methods. Furthermore, thanks to its part-based design, MonoCloth also supports additional tasks such as clothing transfer, underscoring its versatility and practical utility.
JAM: Keypoint-Guided Joint Prediction after Classification-Aware Marginal Proposal for Multi-Agent Interaction
Jul 23, 2025Predicting the future motion of road participants is a critical task in autonomous driving. In this work, we address the challenge of low-quality generation of low-probability modes in multi-agent joint prediction. To tackle this issue, we propose a two-stage multi-agent interactive prediction framework named \textit{keypoint-guided joint prediction after classification-aware marginal proposal} (JAM). The first stage is modeled as a marginal prediction process, which classifies queries by trajectory type to encourage the model to learn all categories of trajectories, providing comprehensive mode information for the joint prediction module. The second stage is modeled as a joint prediction process, which takes the scene context and the marginal proposals from the first stage as inputs to learn the final joint distribution. We explicitly introduce key waypoints to guide the joint prediction module in better capturing and leveraging the critical information from the initial predicted trajectories. We conduct extensive experiments on the real-world Waymo Open Motion Dataset interactive prediction benchmark. The results show that our approach achieves competitive performance. In particular, in the framework comparison experiments, the proposed JAM outperforms other prediction frameworks and achieves state-of-the-art performance in interactive trajectory prediction. The code is available at https://github.com/LinFunster/JAM to facilitate future research.