 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Deep Learning-based Point Cloud Denoising
Aug 23, 2025



Accurate 3D geometry acquisition is essential for a wide range of applications, such as computer graphics, autonomous driving, robotics, and augmented reality. However, raw point clouds acquired in real-world environments are often corrupted with noise due to various factors such as sensor, lighting, material, environment etc, which reduces geometric fidelity and degrades downstream performance. Point cloud denoising is a fundamental problem, aiming to recover clean point sets while preserving underlying structures. Classical optimization-based methods, guided by hand-crafted filters or geometric priors, have been extensively studied but struggle to handle diverse and complex noise patterns. Recent deep learning approaches leverage neural network architectures to learn distinctive representations and demonstrate strong outcomes, particularly on complex and large-scale point clouds. Provided these significant advances, this survey provides a comprehensive and up-to-date review of deep learning-based point cloud denoising methods up to August 2025. We organize the literature from two perspectives: (1) supervision level (supervised vs. unsupervised), and (2) modeling perspective, proposing a functional taxonomy that unifies diverse approaches by their denoising principles. We further analyze architectural trends both structurally and chronologically, establish a unified benchmark with consistent training settings, and evaluate methods in terms of denoising quality, surface fidelity, point distribution, and computational efficiency. Finally, we discuss open challenges and outline directions for future research in this rapidly evolving field.
When Large Language Models Meet Law: Dual-Lens Taxonomy, Technical Advances, and Ethical Governance
Jul 10, 2025This paper establishes the first comprehensive review of Large Language Models (LLMs) applied within the legal domain. It pioneers an innovative dual lens taxonomy that integrates legal reasoning frameworks and professional ontologies to systematically unify historical research and contemporary breakthroughs. Transformer-based LLMs, which exhibit emergent capabilities such as contextual reasoning and generative argumentation, surmount traditional limitations by dynamically capturing legal semantics and unifying evidence reasoning. Significant progress is documented in task generalization, reasoning formalization, workflow integration, and addressing core challenges in text processing, knowledge integration, and evaluation rigor via technical innovations like sparse attention mechanisms and mixture-of-experts architectures. However, widespread adoption of LLM introduces critical challenges: hallucination, explainability deficits, jurisdictional adaptation difficulties, and ethical asymmetry. This review proposes a novel taxonomy that maps legal roles to NLP subtasks and computationally implements the Toulmin argumentation framework, thus systematizing advances in reasoning, retrieval, prediction, and dispute resolution. It identifies key frontiers including low-resource systems, multimodal evidence integration, and dynamic rebuttal handling. Ultimately, this work provides both a technical roadmap for researchers and a conceptual framework for practitioners navigating the algorithmic future, laying a robust foundation for the next era of legal artificial intelligence. We have created a GitHub repository to index the relevant papers: https://github.com/Kilimajaro/LLMs_Meet_Law.
Towards Uniform Point Distribution in Feature-preserving Point Cloud Filtering
Jan 17, 2022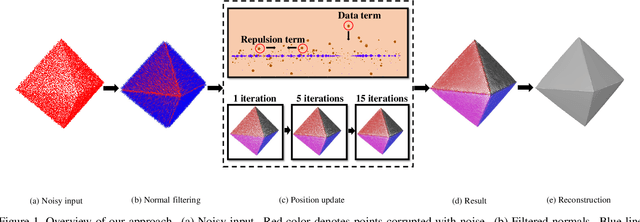
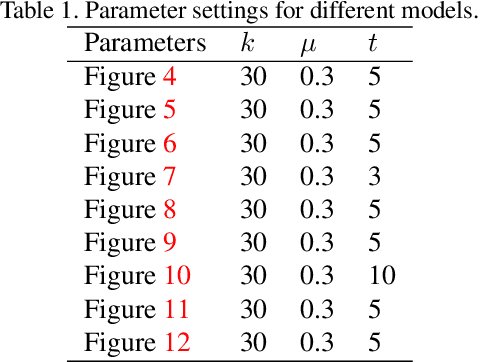
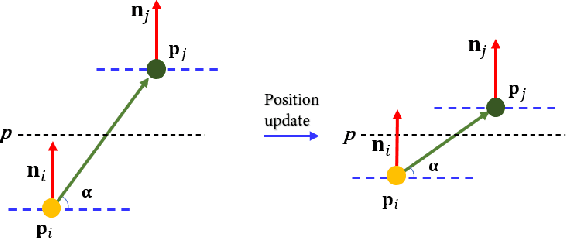
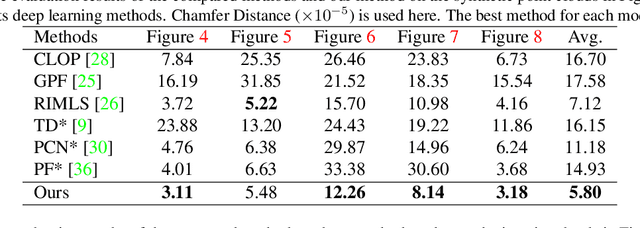
As a popular representation of 3D data, point cloud may contain noise and need to be filtered before use. Existing point cloud filtering methods either cannot preserve sharp features or result in uneven point distribution in the filtered output. To address this problem, this paper introduces a point cloud filtering method that considers both point distribution and feature preservation during filtering. The key idea is to incorporate a repulsion term with a data term in energy minimization. The repulsion term is responsible for the point distribution, while the data term is to approximate the noisy surfaces while preserving the geometric features. This method is capable of handling models with fine-scale features and sharp features. Extensive experiments show that our method yields better results with a more uniform point distribution ($5.8\times10^{-5}$ Chamfer Distance on average) in seconds.
Rethinking Point Cloud Filtering: A Non-Local Position Based Approach
Oct 14, 2021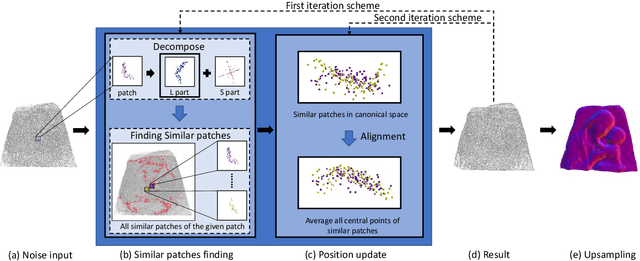
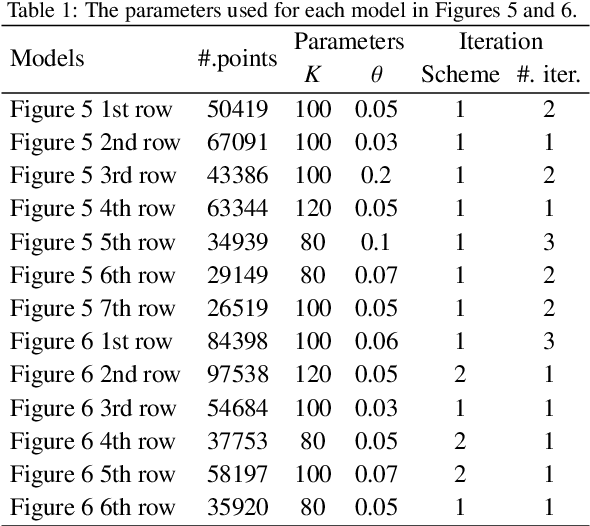
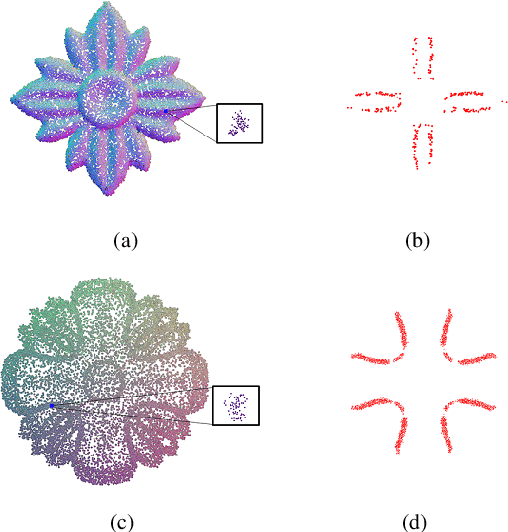
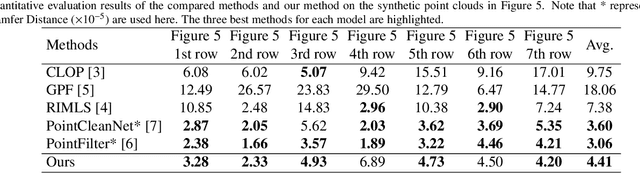
Existing position based point cloud filtering methods can hardly preserve sharp geometric features. In this paper, we rethink point cloud filtering from a non-learning non-local non-normal perspective, and propose a novel position based approach for feature-preserving point cloud filtering. Unlike normal based techniques, our method does not require the normal information. The core idea is to first design a similarity metric to search the non-local similar patches of a queried local patch. We then map the non-local similar patches into a canonical space and aggregate the non-local information. The aggregated outcome (i.e. coordinate) will be inversely mapped into the original space. Our method is simple yet effective. Extensive experiments validate our method, and show that it generally outperforms position based methods (deep learning and non-learning), and generates better or comparable outcomes to normal based techniques (deep learning and non-learning).