 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval
Feb 12, 20263D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations. Our code will be made available at https://github.com/ndkhanh360/RI-Mamba.git.
Class-Partitioned VQ-VAE and Latent Flow Matching for Point Cloud Scene Generation
Jan 18, 2026Most 3D scene generation methods are limited to only generating object bounding box parameters while newer diffusion methods also generate class labels and latent features. Using object size or latent feature, they then retrieve objects from a predefined database. For complex scenes of varied, multi-categorical objects, diffusion-based latents cannot be effectively decoded by current autoencoders into the correct point cloud objects which agree with target classes. We introduce a Class-Partitioned Vector Quantized Variational Autoencoder (CPVQ-VAE) that is trained to effectively decode object latent features, by employing a pioneering $\textit{class-partitioned codebook}$ where codevectors are labeled by class. To address the problem of $\textit{codebook collapse}$, we propose a $\textit{class-aware}$ running average update which reinitializes dead codevectors within each partition. During inference, object features and class labels, both generated by a Latent-space Flow Matching Model (LFMM) designed specifically for scene generation, are consumed by the CPVQ-VAE. The CPVQ-VAE's class-aware inverse look-up then maps generated latents to codebook entries that are decoded to class-specific point cloud shapes. Thereby, we achieve pure point cloud generation without relying on an external objects database for retrieval. Extensive experiments reveal that our method reliably recovers plausible point cloud scenes, with up to 70.4% and 72.3% reduction in Chamfer and Point2Mesh errors on complex living room scenes.
Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation
Dec 22, 2025



Locating and retrieving objects from scene-level point clouds is a challenging problem with broad applications in robotics and augmented reality. This task is commonly formulated as open-vocabulary 3D instance segmentation. Although recent methods demonstrate strong performance, they depend heavily on SAM and CLIP to generate and classify 3D instance masks from images accompanying the point cloud, leading to substantial computational overhead and slow processing that limit their deployment in real-world settings. Open-YOLO 3D alleviates this issue by using a real-time 2D detector to classify class-agnostic masks produced directly from the point cloud by a pretrained 3D segmenter, eliminating the need for SAM and CLIP and significantly reducing inference time. However, Open-YOLO 3D often fails to generalize to object categories that appear infrequently in the 3D training data. In this paper, we propose a method that generates 3D instance masks for novel objects from RGB images guided by a 2D open-vocabulary detector. Our approach inherits the 2D detector's ability to recognize novel objects while maintaining efficient classification, enabling fast and accurate retrieval of rare instances from open-ended text queries. Our code will be made available at https://github.com/ndkhanh360/BoxOVIS.
A Survey of Deep Learning-based Point Cloud Denoising
Aug 23, 2025



Accurate 3D geometry acquisition is essential for a wide range of applications, such as computer graphics, autonomous driving, robotics, and augmented reality. However, raw point clouds acquired in real-world environments are often corrupted with noise due to various factors such as sensor, lighting, material, environment etc, which reduces geometric fidelity and degrades downstream performance. Point cloud denoising is a fundamental problem, aiming to recover clean point sets while preserving underlying structures. Classical optimization-based methods, guided by hand-crafted filters or geometric priors, have been extensively studied but struggle to handle diverse and complex noise patterns. Recent deep learning approaches leverage neural network architectures to learn distinctive representations and demonstrate strong outcomes, particularly on complex and large-scale point clouds. Provided these significant advances, this survey provides a comprehensive and up-to-date review of deep learning-based point cloud denoising methods up to August 2025. We organize the literature from two perspectives: (1) supervision level (supervised vs. unsupervised), and (2) modeling perspective, proposing a functional taxonomy that unifies diverse approaches by their denoising principles. We further analyze architectural trends both structurally and chronologically, establish a unified benchmark with consistent training settings, and evaluate methods in terms of denoising quality, surface fidelity, point distribution, and computational efficiency. Finally, we discuss open challenges and outline directions for future research in this rapidly evolving field.
Hybrid Long and Short Range Flows for Point Cloud Filtering
Aug 12, 2025Point cloud capture processes are error-prone and introduce noisy artifacts that necessitate filtering/denoising. Recent filtering methods often suffer from point clustering or noise retaining issues. In this paper, we propose Hybrid Point Cloud Filtering ($\textbf{HybridPF}$) that considers both short-range and long-range filtering trajectories when removing noise. It is well established that short range scores, given by $\nabla_{x}\log p(x_t)$, may provide the necessary displacements to move noisy points to the underlying clean surface. By contrast, long range velocity flows approximate constant displacements directed from a high noise variant patch $x_0$ towards the corresponding clean surface $x_1$. Here, noisy patches $x_t$ are viewed as intermediate states between the high noise variant and the clean patches. Our intuition is that long range information from velocity flow models can guide the short range scores to align more closely with the clean points. In turn, score models generally provide a quicker convergence to the clean surface. Specifically, we devise two parallel modules, the ShortModule and LongModule, each consisting of an Encoder-Decoder pair to respectively account for short-range scores and long-range flows. We find that short-range scores, guided by long-range features, yield filtered point clouds with good point distributions and convergence near the clean surface. We design a joint loss function to simultaneously train the ShortModule and LongModule, in an end-to-end manner. Finally, we identify a key weakness in current displacement based methods, limitations on the decoder architecture, and propose a dynamic graph convolutional decoder to improve the inference process. Comprehensive experiments demonstrate that our HybridPF achieves state-of-the-art results while enabling faster inference speed.
StraightPCF: Straight Point Cloud Filtering
May 14, 2024Point cloud filtering is a fundamental 3D vision task, which aims to remove noise while recovering the underlying clean surfaces. State-of-the-art methods remove noise by moving noisy points along stochastic trajectories to the clean surfaces. These methods often require regularization within the training objective and/or during post-processing, to ensure fidelity. In this paper, we introduce StraightPCF, a new deep learning based method for point cloud filtering. It works by moving noisy points along straight paths, thus reducing discretization errors while ensuring faster convergence to the clean surfaces. We model noisy patches as intermediate states between high noise patch variants and their clean counterparts, and design the VelocityModule to infer a constant flow velocity from the former to the latter. This constant flow leads to straight filtering trajectories. In addition, we introduce a DistanceModule that scales the straight trajectory using an estimated distance scalar to attain convergence near the clean surface. Our network is lightweight and only has $\sim530K$ parameters, being 17% of IterativePFN (a most recent point cloud filtering network). Extensive experiments on both synthetic and real-world data show our method achieves state-of-the-art results. Our method also demonstrates nice distributions of filtered points without the need for regularization. The implementation code can be found at: https://github.com/ddsediri/StraightPCF.
IterativePFN: True Iterative Point Cloud Filtering
Apr 04, 2023



The quality of point clouds is often limited by noise introduced during their capture process. Consequently, a fundamental 3D vision task is the removal of noise, known as point cloud filtering or denoising. State-of-the-art learning based methods focus on training neural networks to infer filtered displacements and directly shift noisy points onto the underlying clean surfaces. In high noise conditions, they iterate the filtering process. However, this iterative filtering is only done at test time and is less effective at ensuring points converge quickly onto the clean surfaces. We propose IterativePFN (iterative point cloud filtering network), which consists of multiple IterationModules that model the true iterative filtering process internally, within a single network. We train our IterativePFN network using a novel loss function that utilizes an adaptive ground truth target at each iteration to capture the relationship between intermediate filtering results during training. This ensures that the filtered results converge faster to the clean surfaces. Our method is able to obtain better performance compared to state-of-the-art methods. The source code can be found at: https://github.com/ddsediri/IterativePFN.
Contrastive Learning for Joint Normal Estimation and Point Cloud Filtering
Aug 14, 2022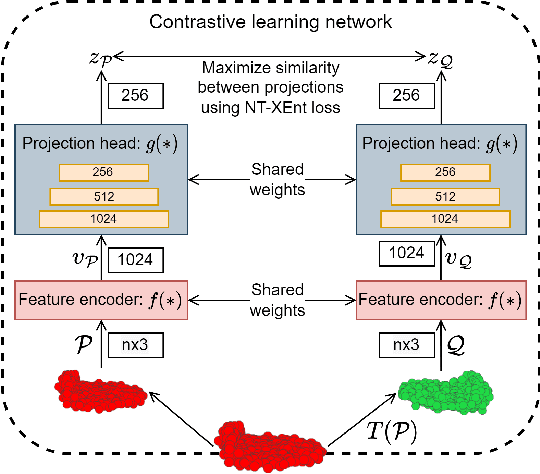
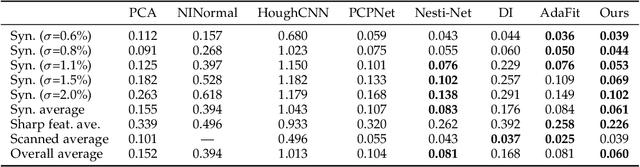
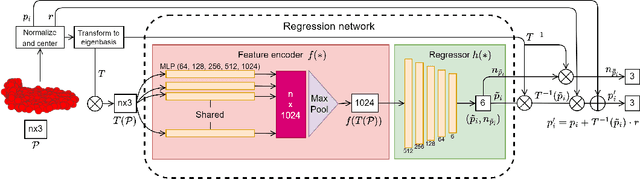
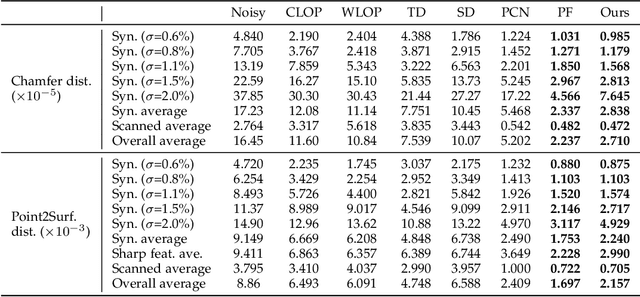
Point cloud filtering and normal estimation are two fundamental research problems in the 3D field. Existing methods usually perform normal estimation and filtering separately and often show sensitivity to noise and/or inability to preserve sharp geometric features such as corners and edges. In this paper, we propose a novel deep learning method to jointly estimate normals and filter point clouds. We first introduce a 3D patch based contrastive learning framework, with noise corruption as an augmentation, to train a feature encoder capable of generating faithful representations of point cloud patches while remaining robust to noise. These representations are consumed by a simple regression network and supervised by a novel joint loss, simultaneously estimating point normals and displacements that are used to filter the patch centers. Experimental results show that our method well supports the two tasks simultaneously and preserves sharp features and fine details. It generally outperforms state-of-the-art techniques on both tasks.
Deep Point Cloud Normal Estimation via Triplet Learning
Oct 20, 2021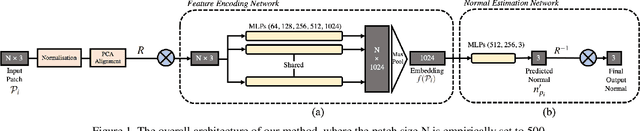

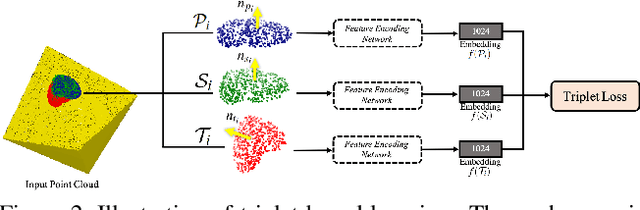

Normal estimation on 3D point clouds is a fundamental problem in 3D vision and graphics. Current methods often show limited accuracy in predicting normals at sharp features (e.g., edges and corners) and less robustness to noise. In this paper, we propose a novel normal estimation method for point clouds. It consists of two phases: (a) feature encoding which learns representations of local patches, and (b) normal estimation that takes the learned representation as input and regresses the normal vector. We are motivated that local patches on isotropic and anisotropic surfaces have similar or distinct normals, and that separable features or representations can be learned to facilitate normal estimation. To realise this, we first construct triplets of local patches on 3D point cloud data, and design a triplet network with a triplet loss for feature encoding. We then design a simple network with several MLPs and a loss function to regress the normal vector. Despite having a smaller network size compared to most other methods, experimental results show that our method preserves sharp features and achieves better normal estimation results on CAD-like shapes.