 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Shapley with Robust Significance Testing and Its Application to Bond Recovery Rate Prediction
Jan 06, 2025



We propose Group Shapley, a metric that extends the classical individual-level Shapley value framework to evaluate the importance of feature groups, addressing the structured nature of predictors commonly found in business and economic data. More importantly, we develop a significance testing procedure based on a three-cumulant chi-square approximation and establish the asymptotic properties of the test statistics for Group Shapley values. Our approach can effectively handle challenging scenarios, including sparse or skewed distributions and small sample sizes, outperforming alternative tests such as the Wald test. Simulations confirm that the proposed test maintains robust empirical size and demonstrates enhanced power under diverse conditions. To illustrate the method's practical relevance in advancing Explainable AI, we apply our framework to bond recovery rate predictions using a global dataset (1996-2023) comprising 2,094 observations and 98 features, grouped into 16 subgroups and five broader categories: bond characteristics, firm fundamentals, industry-specific factors, market-related variables, and macroeconomic indicators. Our results identify the market-related variables group as the most influential. Furthermore, Lorenz curves and Gini indices reveal that Group Shapley assigns feature importance more equitably compared to individual Shapley values.
Facial Attractiveness Prediction in Live Streaming: A New Benchmark and Multi-modal Method
Jan 05, 2025



Facial attractiveness prediction (FAP) has long been an important computer vision task, which could be widely applied in live streaming for facial retouching, content recommendation, etc. However, previous FAP datasets are either small, closed-source, or lack diversity. Moreover, the corresponding FAP models exhibit limited generalization and adaptation ability. To overcome these limitations, in this paper we present LiveBeauty, the first large-scale live-specific FAP dataset, in a more challenging application scenario, i.e., live streaming. 10,000 face images are collected from a live streaming platform directly, with 200,000 corresponding attractiveness annotations obtained from a well-devised subjective experiment, making LiveBeauty the largest open-access FAP dataset in the challenging live scenario. Furthermore, a multi-modal FAP method is proposed to measure the facial attractiveness in live streaming. Specifically, we first extract holistic facial prior knowledge and multi-modal aesthetic semantic features via a Personalized Attractiveness Prior Module (PAPM) and a Multi-modal Attractiveness Encoder Module (MAEM), respectively, then integrate the extracted features through a Cross-Modal Fusion Module (CMFM). Extensive experiments conducted on both LiveBeauty and other open-source FAP datasets demonstrate that our proposed method achieves state-of-the-art performance. Dataset will be available soon.
AdaMixup: A Dynamic Defense Framework for Membership Inference Attack Mitigation
Jan 04, 2025

Membership inference attacks have emerged as a significant privacy concern in the training of deep learning models, where attackers can infer whether a data point was part of the training set based on the model's outputs. To address this challenge, we propose a novel defense mechanism, AdaMixup. AdaMixup employs adaptive mixup techniques to enhance the model's robustness against membership inference attacks by dynamically adjusting the mixup strategy during training. This method not only improves the model's privacy protection but also maintains high performance. Experimental results across multiple datasets demonstrate that AdaMixup significantly reduces the risk of membership inference attacks while achieving a favorable trade-off between defensive efficiency and model accuracy. This research provides an effective solution for data privacy protection and lays the groundwork for future advancements in mixup training methods.
Analyzing Country-Level Vaccination Rates and Determinants of Practical Capacity to Administer COVID-19 Vaccines
Dec 30, 2024The COVID-19 vaccine development, manufacturing, transportation, and administration proved an extreme logistics operation of global magnitude. Global vaccination levels, however, remain a key concern in preventing the emergence of new strains and minimizing the impact of the pandemic's disruption of daily life. In this paper, country-level vaccination rates are analyzed through a queuing framework to extract service rates that represent the practical capacity of a country to administer vaccines. These rates are further characterized through regression and interpretable machine learning methods with country-level demographic, governmental, and socio-economic variates. Model results show that participation in multi-governmental collaborations such as COVAX may improve the ability to vaccinate. Similarly, improved transportation and accessibility variates such as roads per area for low-income countries and rail lines per area for high-income countries can improve rates. It was also found that for low-income countries specifically, improvements in basic and health infrastructure (as measured through spending on healthcare, number of doctors and hospital beds per 100k, population percent with access to electricity, life expectancy, and vehicles per 1000 people) resulted in higher vaccination rates. Of the high-income countries, those with larger 65-plus populations struggled to vaccinate at high rates, indicating potential accessibility issues for the elderly. This study finds that improving basic and health infrastructure, focusing on accessibility in the last mile, particularly for the elderly, and fostering global partnerships can improve logistical operations of such a scale. Such structural impediments and inequities in global health care must be addressed in preparation for future global public health crises.
Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024


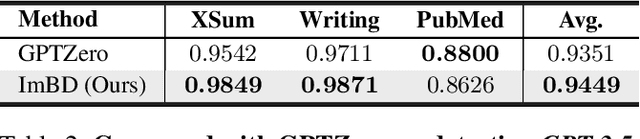
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
Fine-grained Text to Image Synthesis
Dec 10, 2024Fine-grained text to image synthesis involves generating images from texts that belong to different categories. In contrast to general text to image synthesis, in fine-grained synthesis there is high similarity between images of different subclasses, and there may be linguistic discrepancy among texts describing the same image. Recent Generative Adversarial Networks (GAN), such as the Recurrent Affine Transformation (RAT) GAN model, are able to synthesize clear and realistic images from texts. However, GAN models ignore fine-grained level information. In this paper we propose an approach that incorporates an auxiliary classifier in the discriminator and a contrastive learning method to improve the accuracy of fine-grained details in images synthesized by RAT GAN. The auxiliary classifier helps the discriminator classify the class of images, and helps the generator synthesize more accurate fine-grained images. The contrastive learning method minimizes the similarity between images from different subclasses and maximizes the similarity between images from the same subclass. We evaluate on several state-of-the-art methods on the commonly used CUB-200-2011 bird dataset and Oxford-102 flower dataset, and demonstrated superior performance.
Practical Performative Policy Learning with Strategic Agents
Dec 02, 2024



This paper studies the performative policy learning problem, where agents adjust their features in response to a released policy to improve their potential outcomes, inducing an endogenous distribution shift. There has been growing interest in training machine learning models in strategic environments, including strategic classification and performative prediction. However, existing approaches often rely on restrictive parametric assumptions: micro-level utility models in strategic classification and macro-level data distribution maps in performative prediction, severely limiting scalability and generalizability. We approach this problem as a complex causal inference task, relaxing parametric assumptions on both micro-level agent behavior and macro-level data distribution. Leveraging bounded rationality, we uncover a practical low-dimensional structure in distribution shifts and construct an effective mediator in the causal path from the deployed model to the shifted data. We then propose a gradient-based policy optimization algorithm with a differentiable classifier as a substitute for the high-dimensional distribution map. Our algorithm efficiently utilizes batch feedback and limited manipulation patterns. Our approach achieves high sample efficiency compared to methods reliant on bandit feedback or zero-order optimization. We also provide theoretical guarantees for algorithmic convergence. Extensive and challenging experiments on high-dimensional settings demonstrate our method's practical efficacy.
Advancing Myopia To Holism: Fully Contrastive Language-Image Pre-training
Nov 30, 2024



In rapidly evolving field of vision-language models (VLMs), contrastive language-image pre-training (CLIP) has made significant strides, becoming foundation for various downstream tasks. However, relying on one-to-one (image, text) contrastive paradigm to learn alignment from large-scale messy web data, CLIP faces a serious myopic dilemma, resulting in biases towards monotonous short texts and shallow visual expressivity. To overcome these issues, this paper advances CLIP into one novel holistic paradigm, by updating both diverse data and alignment optimization. To obtain colorful data with low cost, we use image-to-text captioning to generate multi-texts for each image, from multiple perspectives, granularities, and hierarchies. Two gadgets are proposed to encourage textual diversity. To match such (image, multi-texts) pairs, we modify the CLIP image encoder into multi-branch, and propose multi-to-multi contrastive optimization for image-text part-to-part matching. As a result, diverse visual embeddings are learned for each image, bringing good interpretability and generalization. Extensive experiments and ablations across over ten benchmarks indicate that our holistic CLIP significantly outperforms existing myopic CLIP, including image-text retrieval, open-vocabulary classification, and dense visual tasks.
Leveraging Semantic Asymmetry for Precise Gross Tumor Volume Segmentation of Nasopharyngeal Carcinoma in Planning CT
Nov 27, 2024



In the radiation therapy of nasopharyngeal carcinoma (NPC), clinicians typically delineate the gross tumor volume (GTV) using non-contrast planning computed tomography to ensure accurate radiation dose delivery. However, the low contrast between tumors and adjacent normal tissues necessitates that radiation oncologists manually delineate the tumors, often relying on diagnostic MRI for guidance. % In this study, we propose a novel approach to directly segment NPC gross tumors on non-contrast planning CT images, circumventing potential registration errors when aligning MRI or MRI-derived tumor masks to planning CT. To address the low contrast issues between tumors and adjacent normal structures in planning CT, we introduce a 3D Semantic Asymmetry Tumor segmentation (SATs) method. Specifically, we posit that a healthy nasopharyngeal region is characteristically bilaterally symmetric, whereas the emergence of nasopharyngeal carcinoma disrupts this symmetry. Then, we propose a Siamese contrastive learning segmentation framework that minimizes the voxel-wise distance between original and flipped areas without tumor and encourages a larger distance between original and flipped areas with tumor. Thus, our approach enhances the sensitivity of features to semantic asymmetries. % Extensive experiments demonstrate that the proposed SATs achieves the leading NPC GTV segmentation performance in both internal and external testing, \emph{e.g.}, with at least 2\% absolute Dice score improvement and 12\% average distance error reduction when compared to other state-of-the-art methods in the external testing.
ST-Align: A Multimodal Foundation Model for Image-Gene Alignment in Spatial Transcriptomics
Nov 25, 2024



Spatial transcriptomics (ST) provides high-resolution pathological images and whole-transcriptomic expression profiles at individual spots across whole-slide scales. This setting makes it an ideal data source to develop multimodal foundation models. Although recent studies attempted to fine-tune visual encoders with trainable gene encoders based on spot-level, the absence of a wider slide perspective and spatial intrinsic relationships limits their ability to capture ST-specific insights effectively. Here, we introduce ST-Align, the first foundation model designed for ST that deeply aligns image-gene pairs by incorporating spatial context, effectively bridging pathological imaging with genomic features. We design a novel pretraining framework with a three-target alignment strategy for ST-Align, enabling (1) multi-scale alignment across image-gene pairs, capturing both spot- and niche-level contexts for a comprehensive perspective, and (2) cross-level alignment of multimodal insights, connecting localized cellular characteristics and broader tissue architecture. Additionally, ST-Align employs specialized encoders tailored to distinct ST contexts, followed by an Attention-Based Fusion Network (ABFN) for enhanced multimodal fusion, effectively merging domain-shared knowledge with ST-specific insights from both pathological and genomic data. We pre-trained ST-Align on 1.3 million spot-niche pairs and evaluated its performance through two downstream tasks across six datasets, demonstrating superior zero-shot and few-shot capabilities. ST-Align highlights the potential for reducing the cost of ST and providing valuable insights into the distinction of critical compositions within human tissue.