 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Local Minima Provably in Non-convex Matrix Sensing: A Deterministic Framework via Simulated Lifting
Feb 05, 2026Low-rank matrix sensing is a fundamental yet challenging nonconvex problem whose optimization landscape typically contains numerous spurious local minima, making it difficult for gradient-based optimizers to converge to the global optimum. Recent work has shown that over-parameterization via tensor lifting can convert such local minima into strict saddle points, an insight that also partially explains why massive scaling can improve generalization and performance in modern machine learning. Motivated by this observation, we propose a Simulated Oracle Direction (SOD) escape mechanism that simulates the landscape and escape direction of the over-parametrized space, without resorting to actually lifting the problem, since that would be computationally intractable. In essence, we designed a mathematical framework to project over-parametrized escape directions onto the original parameter space to guarantee a strict decrease of objective value from existing local minima. To the best of the our knowledge, this represents the first deterministic framework that could escape spurious local minima with guarantee, especially without using random perturbations or heuristic estimates. Numerical experiments demonstrate that our framework reliably escapes local minima and facilitates convergence to global optima, while incurring minimal computational cost when compared to explicit tensor over-parameterization. We believe this framework has non-trivial implications for nonconvex optimization beyond matrix sensing, by showcasing how simulated over-parameterization can be leveraged to tame challenging optimization landscapes.
VAMO: Efficient Large-Scale Nonconvex Optimization via Adaptive Zeroth Order Variance Reduction
May 20, 2025Optimizing large-scale nonconvex problems, common in machine learning, demands balancing rapid convergence with computational efficiency. First-order (FO) stochastic methods like SVRG provide fast convergence and good generalization but incur high costs due to full-batch gradients in large models. Conversely, zeroth-order (ZO) algorithms reduce this burden using estimated gradients, yet their slow convergence in high-dimensional settings limits practicality. We introduce VAMO (VAriance-reduced Mixed-gradient Optimizer), a stochastic variance-reduced method combining FO mini-batch gradients with lightweight ZO finite-difference probes under an SVRG-style framework. VAMO's hybrid design uses a two-point ZO estimator to achieve a dimension-agnostic convergence rate of $\mathcal{O}(1/T + 1/b)$, where $T$ is the number of iterations and $b$ is the batch-size, surpassing the dimension-dependent slowdown of purely ZO methods and significantly improving over SGD's $\mathcal{O}(1/\sqrt{T})$ rate. Additionally, we propose a multi-point ZO variant that mitigates the $O(1/b)$ error by adjusting number of estimation points to balance convergence and cost, making it ideal for a whole range of computationally constrained scenarios. Experiments including traditional neural network training and LLM finetuning show VAMO outperforms established FO and ZO methods, offering a faster, more flexible option for improved efficiency.
Topology-Aware 3D Gaussian Splatting: Leveraging Persistent Homology for Optimized Structural Integrity
Dec 21, 2024Gaussian Splatting (GS) has emerged as a crucial technique for representing discrete volumetric radiance fields. It leverages unique parametrization to mitigate computational demands in scene optimization. This work introduces Topology-Aware 3D Gaussian Splatting (Topology-GS), which addresses two key limitations in current approaches: compromised pixel-level structural integrity due to incomplete initial geometric coverage, and inadequate feature-level integrity from insufficient topological constraints during optimization. To overcome these limitations, Topology-GS incorporates a novel interpolation strategy, Local Persistent Voronoi Interpolation (LPVI), and a topology-focused regularization term based on persistent barcodes, named PersLoss. LPVI utilizes persistent homology to guide adaptive interpolation, enhancing point coverage in low-curvature areas while preserving topological structure. PersLoss aligns the visual perceptual similarity of rendered images with ground truth by constraining distances between their topological features. Comprehensive experiments on three novel-view synthesis benchmarks demonstrate that Topology-GS outperforms existing methods in terms of PSNR, SSIM, and LPIPS metrics, while maintaining efficient memory usage. This study pioneers the integration of topology with 3D-GS, laying the groundwork for future research in this area.
Absence of spurious solutions far from ground truth: A low-rank analysis with high-order losses
Mar 10, 2024Matrix sensing problems exhibit pervasive non-convexity, plaguing optimization with a proliferation of suboptimal spurious solutions. Avoiding convergence to these critical points poses a major challenge. This work provides new theoretical insights that help demystify the intricacies of the non-convex landscape. In this work, we prove that under certain conditions, critical points sufficiently distant from the ground truth matrix exhibit favorable geometry by being strict saddle points rather than troublesome local minima. Moreover, we introduce the notion of higher-order losses for the matrix sensing problem and show that the incorporation of such losses into the objective function amplifies the negative curvature around those distant critical points. This implies that increasing the complexity of the objective function via high-order losses accelerates the escape from such critical points and acts as a desirable alternative to increasing the complexity of the optimization problem via over-parametrization. By elucidating key characteristics of the non-convex optimization landscape, this work makes progress towards a comprehensive framework for tackling broader machine learning objectives plagued by non-convexity.
Algorithmic Regularization in Tensor Optimization: Towards a Lifted Approach in Matrix Sensing
Oct 24, 2023Gradient descent (GD) is crucial for generalization in machine learning models, as it induces implicit regularization, promoting compact representations. In this work, we examine the role of GD in inducing implicit regularization for tensor optimization, particularly within the context of the lifted matrix sensing framework. This framework has been recently proposed to address the non-convex matrix sensing problem by transforming spurious solutions into strict saddles when optimizing over symmetric, rank-1 tensors. We show that, with sufficiently small initialization scale, GD applied to this lifted problem results in approximate rank-1 tensors and critical points with escape directions. Our findings underscore the significance of the tensor parametrization of matrix sensing, in combination with first-order methods, in achieving global optimality in such problems.
Over-parametrization via Lifting for Low-rank Matrix Sensing: Conversion of Spurious Solutions to Strict Saddle Points
Feb 15, 2023


This paper studies the role of over-parametrization in solving non-convex optimization problems. The focus is on the important class of low-rank matrix sensing, where we propose an infinite hierarchy of non-convex problems via the lifting technique and the Burer-Monteiro factorization. This contrasts with the existing over-parametrization technique where the search rank is limited by the dimension of the matrix and it does not allow a rich over-parametrization of an arbitrary degree. We show that although the spurious solutions of the problem remain stationary points through the hierarchy, they will be transformed into strict saddle points (under some technical conditions) and can be escaped via local search methods. This is the first result in the literature showing that over-parametrization creates a negative curvature for escaping spurious solutions. We also derive a bound on how much over-parametrization is requited to enable the elimination of spurious solutions.
Semidefinite Programming versus Burer-Monteiro Factorization for Matrix Sensing
Aug 15, 2022Many fundamental low-rank optimization problems, such as matrix completion, phase synchronization/retrieval, power system state estimation, and robust PCA, can be formulated as the matrix sensing problem. Two main approaches for solving matrix sensing are based on semidefinite programming (SDP) and Burer-Monteiro (B-M) factorization. The SDP method suffers from high computational and space complexities, whereas the B-M method may return a spurious solution due to the non-convexity of the problem. The existing theoretical guarantees for the success of these methods have led to similar conservative conditions, which may wrongly imply that these methods have comparable performances. In this paper, we shed light on some major differences between these two methods. First, we present a class of structured matrix completion problems for which the B-M methods fail with an overwhelming probability, while the SDP method works correctly. Second, we identify a class of highly sparse matrix completion problems for which the B-M method works and the SDP method fails. Third, we prove that although the B-M method exhibits the same performance independent of the rank of the unknown solution, the success of the SDP method is correlated to the rank of the solution and improves as the rank increases. Unlike the existing literature that has mainly focused on those instances of matrix sensing for which both SDP and B-M work, this paper offers the first result on the unique merit of each method over the alternative approach.
Noisy Low-rank Matrix Optimization: Geometry of Local Minima and Convergence Rate
Mar 08, 2022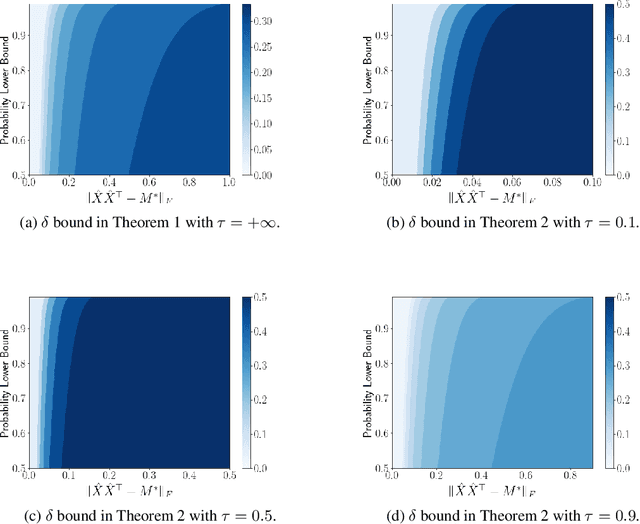
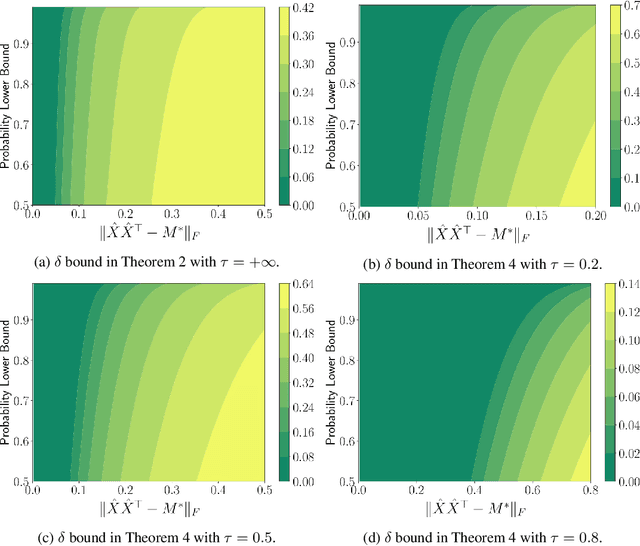
This paper is concerned with low-rank matrix optimization, which has found a wide range of applications in machine learning. This problem in the special case of matrix sense has been studied extensively through the notion of Restricted Isometry Property (RIP), leading to a wealth of results on the geometric landscape of the problem and the convergence rate of common algorithms. However, the existing results are not able to handle the problem with a general objective function subject to noisy data. In this paper, we address this problem by developing a mathematical framework that can deal with random corruptions to general objective functions, where the noise model is arbitrary. We prove that as long as the RIP constant of the noiseless objective is less than $1/3$, any spurious local solution of the noisy optimization problem must be close to the ground truth solution. By working through the strict saddle property, we also show that an approximate solution can be found in polynomial time. We characterize the geometry of the spurious local minima of the problem in a local region around the ground truth in the case when the RIP constant is greater than $1/3$. This paper offers the first set of results on the global and local optimization landscapes of general low-rank optimization problems under arbitrary random corruptions.
Sharp Restricted Isometry Property Bounds for Low-rank Matrix Recovery Problems with Corrupted Measurements
May 18, 2021
In this paper, we study a general low-rank matrix recovery problem with linear measurements corrupted by some noise. The objective is to understand under what conditions on the restricted isometry property (RIP) of the problem local search methods can find the ground truth with a small error. By analyzing the landscape of the non-convex problem, we first propose a global guarantee on the maximum distance between an arbitrary local minimizer and the ground truth under the assumption that the RIP constant is smaller than 1/2. We show that this distance shrinks to zero as the intensity of the noise reduces. Our new guarantee is sharp in terms of the RIP constant and is much stronger than the existing results. We then present a local guarantee for problems with an arbitrary RIP constant, which states that any local minimizer is either considerably close to the ground truth or far away from it. The developed results demonstrate how the noise intensity and the RIP constant of the problem affect the locations of the local minima relative to the true solution.
Partition-Based Convex Relaxations for Certifying the Robustness of ReLU Neural Networks
Jan 22, 2021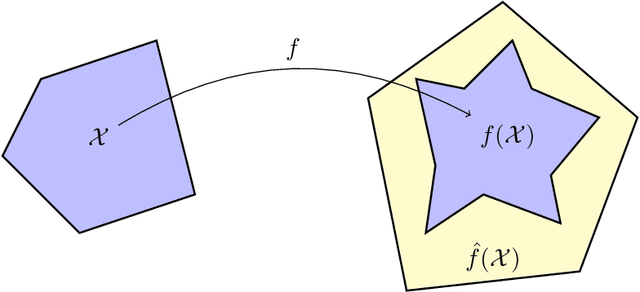
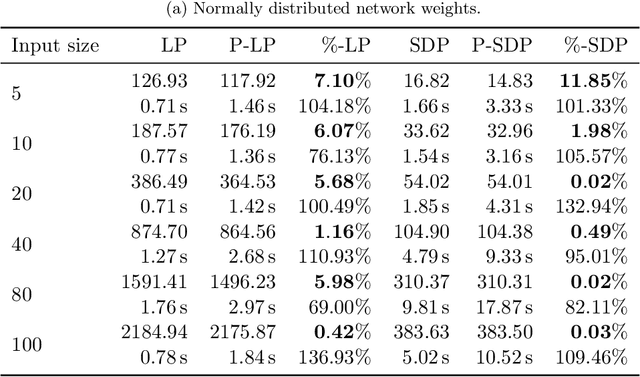
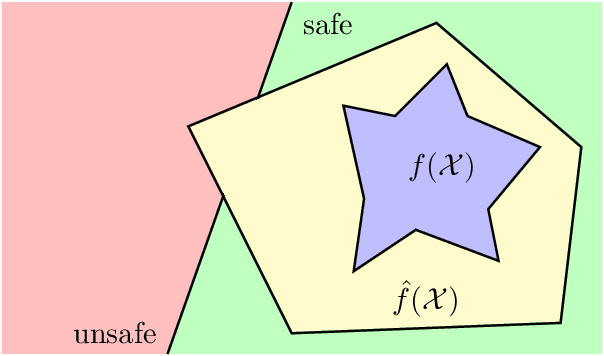
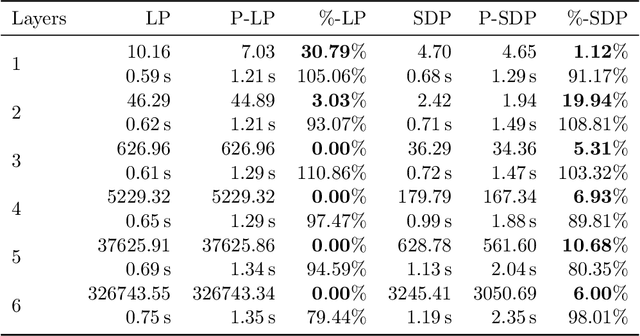
In this paper, we study certifying the robustness of ReLU neural networks against adversarial input perturbations. To diminish the relaxation error suffered by the popular linear programming (LP) and semidefinite programming (SDP) certification methods, we propose partitioning the input uncertainty set and solving the relaxations on each part separately. We show that this approach reduces relaxation error, and that the error is eliminated entirely upon performing an LP relaxation with an intelligently designed partition. To scale this approach to large networks, we consider courser partitions that take the same form as this motivating partition. We prove that computing such a partition that directly minimizes the LP relaxation error is NP-hard. By instead minimizing the worst-case LP relaxation error, we develop a computationally tractable scheme with a closed-form optimal two-part partition. We extend the analysis to the SDP, where the feasible set geometry is exploited to design a two-part partition that minimizes the worst-case SDP relaxation error. Experiments on IRIS classifiers demonstrate significant reduction in relaxation error, offering certificates that are otherwise void without partitioning. By independently increasing the input size and the number of layers, we empirically illustrate under which regimes the partitioned LP and SDP are best applied.