 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT as Psychologist? Preliminary Evaluations for GPT-4V on Visual Affective Computing
Mar 09, 2024



Multimodal language models (MLMs) are designed to process and integrate information from multiple sources, such as text, speech, images, and videos. Despite its success in language understanding, it is critical to evaluate the performance of downstream tasks for better human-centric applications. This paper assesses the application of MLMs with 5 crucial abilities for affective computing, spanning from visual affective tasks and reasoning tasks. The results show that GPT4 has high accuracy in facial action unit recognition and micro-expression detection while its general facial expression recognition performance is not accurate. We also highlight the challenges of achieving fine-grained micro-expression recognition and the potential for further study and demonstrate the versatility and potential of GPT4 for handling advanced tasks in emotion recognition and related fields by integrating with task-related agents for more complex tasks, such as heart rate estimation through signal processing. In conclusion, this paper provides valuable insights into the potential applications and challenges of MLMs in human-centric computing. The interesting samples are available at \url{https://github.com/LuPaoPao/GPT4Affectivity}.
Large-scale Weakly Supervised Learning for Road Extraction from Satellite Imagery
Sep 14, 2023



Automatic road extraction from satellite imagery using deep learning is a viable alternative to traditional manual mapping. Therefore it has received considerable attention recently. However, most of the existing methods are supervised and require pixel-level labeling, which is tedious and error-prone. To make matters worse, the earth has a diverse range of terrain, vegetation, and man-made objects. It is well known that models trained in one area generalize poorly to other areas. Various shooting conditions such as light and angel, as well as different image processing techniques further complicate the issue. It is impractical to develop training data to cover all image styles. This paper proposes to leverage OpenStreetMap road data as weak labels and large scale satellite imagery to pre-train semantic segmentation models. Our extensive experimental results show that the prediction accuracy increases with the amount of the weakly labeled data, as well as the road density in the areas chosen for training. Using as much as 100 times more data than the widely used DeepGlobe road dataset, our model with the D-LinkNet architecture and the ResNet-50 backbone exceeds the top performer of the current DeepGlobe leaderboard. Furthermore, due to large-scale pre-training, our model generalizes much better than those trained with only the curated datasets, implying great application potential.
Fg-T2M: Fine-Grained Text-Driven Human Motion Generation via Diffusion Model
Sep 12, 2023Text-driven human motion generation in computer vision is both significant and challenging. However, current methods are limited to producing either deterministic or imprecise motion sequences, failing to effectively control the temporal and spatial relationships required to conform to a given text description. In this work, we propose a fine-grained method for generating high-quality, conditional human motion sequences supporting precise text description. Our approach consists of two key components: 1) a linguistics-structure assisted module that constructs accurate and complete language feature to fully utilize text information; and 2) a context-aware progressive reasoning module that learns neighborhood and overall semantic linguistics features from shallow and deep graph neural networks to achieve a multi-step inference. Experiments show that our approach outperforms text-driven motion generation methods on HumanML3D and KIT test sets and generates better visually confirmed motion to the text conditions.
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
Sep 06, 2023Reconstructing both objects and hands in 3D from a single RGB image is complex. Existing methods rely on manually defined hand-object constraints in Euclidean space, leading to suboptimal feature learning. Compared with Euclidean space, hyperbolic space better preserves the geometric properties of meshes thanks to its exponentially-growing space distance, which amplifies the differences between the features based on similarity. In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features. Our method that projects mesh and image features into a unified hyperbolic space includes two modules, ie. dynamic hyperbolic graph convolution and image-attention hyperbolic graph convolution. With these two modules, our method learns mesh features with rich geometry-image multi-modal information and models better hand-object interaction. Our method provides a promising alternative for fine hand-object reconstruction in hyperbolic space. Extensive experiments on three public datasets demonstrate that our method outperforms most state-of-the-art methods.
Attentive Mask CLIP
Dec 16, 2022



Image token removal is an efficient augmentation strategy for reducing the cost of computing image features. However, this efficient augmentation strategy has been found to adversely affect the accuracy of CLIP-based training. We hypothesize that removing a large portion of image tokens may improperly discard the semantic content associated with a given text description, thus constituting an incorrect pairing target in CLIP training. To address this issue, we propose an attentive token removal approach for CLIP training, which retains tokens with a high semantic correlation to the text description. The correlation scores are computed in an online fashion using the EMA version of the visual encoder. Our experiments show that the proposed attentive masking approach performs better than the previous method of random token removal for CLIP training. The approach also makes it efficient to apply multiple augmentation views to the image, as well as introducing instance contrastive learning tasks between these views into the CLIP framework. Compared to other CLIP improvements that combine different pre-training targets such as SLIP and MaskCLIP, our method is not only more effective, but also much more efficient. Specifically, using ViT-B and YFCC-15M dataset, our approach achieves $43.9\%$ top-1 accuracy on ImageNet-1K zero-shot classification, as well as $62.7/42.1$ and $38.0/23.2$ I2T/T2I retrieval accuracy on Flickr30K and MS COCO, which are $+1.1\%$, $+5.5/+0.9$, and $+4.4/+1.3$ higher than the SLIP method, while being $2.30\times$ faster. An efficient version of our approach running $1.16\times$ faster than the plain CLIP model achieves significant gains of $+5.3\%$, $+11.3/+8.0$, and $+9.5/+4.9$ on these benchmarks.
Training a universal instance segmentation network for live cell images of various cell types and imaging modalities
Jul 28, 2022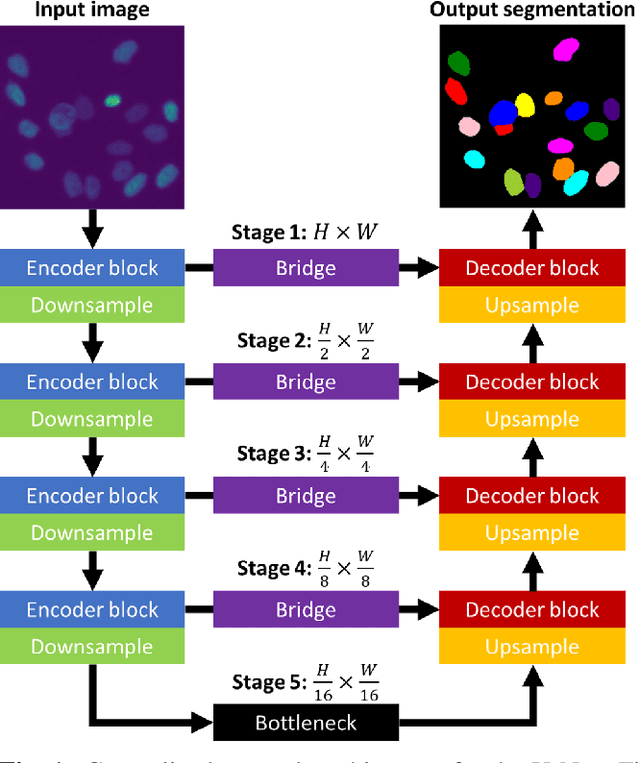
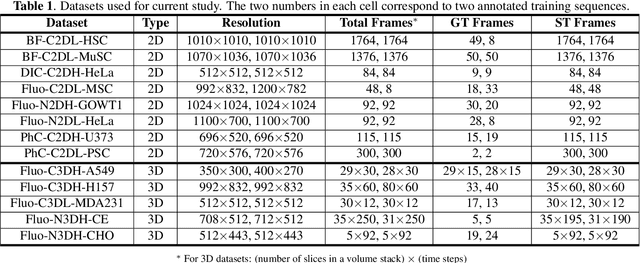

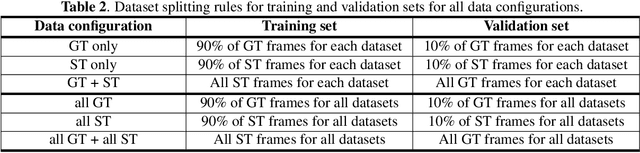
We share our recent findings in an attempt to train a universal segmentation network for various cell types and imaging modalities. Our method was built on the generalized U-Net architecture, which allows the evaluation of each component individually. We modified the traditional binary training targets to include three classes for direct instance segmentation. Detailed experiments were performed regarding training schemes, training settings, network backbones, and individual modules on the segmentation performance. Our proposed training scheme draws minibatches in turn from each dataset, and the gradients are accumulated before an optimization step. We found that the key to training a universal network is all-time supervision on all datasets, and it is necessary to sample each dataset in an unbiased way. Our experiments also suggest that there might exist common features to define cell boundaries across cell types and imaging modalities, which could allow application of trained models to totally unseen datasets. A few training tricks can further boost the segmentation performance, including uneven class weights in the cross-entropy loss function, well-designed learning rate scheduler, larger image crops for contextual information, and additional loss terms for unbalanced classes. We also found that segmentation performance can benefit from group normalization layer and Atrous Spatial Pyramid Pooling module, thanks to their more reliable statistics estimation and improved semantic understanding, respectively. We participated in the 6th Cell Tracking Challenge (CTC) held at IEEE International Symposium on Biomedical Imaging (ISBI) 2021 using one of the developed variants. Our method was evaluated as the best runner up during the initial submission for the primary track, and also secured the 3rd place in an additional round of competition in preparation for the summary publication.
Rethinking the Zigzag Flattening for Image Reading
Mar 15, 2022


Sequence ordering of word vector matters a lot to text reading, which has been proven in natural language processing (NLP). However, the rule of different sequence ordering in computer vision (CV) was not well explored, e.g., why the "zigzag" flattening (ZF) is commonly utilized as a default option to get the image patches ordering in vision transformers (ViTs). Notably, when decomposing multi-scale images, the ZF could not maintain the invariance of feature point positions. To this end, we investigate the Hilbert fractal flattening (HF) as another method for sequence ordering in CV and contrast it against ZF. The HF has proven to be superior to other curves in maintaining spatial locality, when performing multi-scale transformations of dimensional space. And it can be easily plugged into most deep neural networks (DNNs). Extensive experiments demonstrate that it can yield consistent and significant performance boosts for a variety of architectures. Finally, we hope that our studies spark further research about the flattening strategy of image reading.
GSC Loss: A Gaussian Score Calibrating Loss for Deep Learning
Mar 02, 2022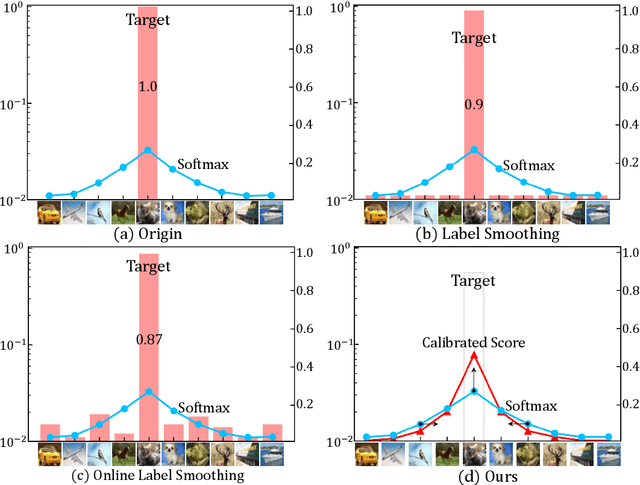
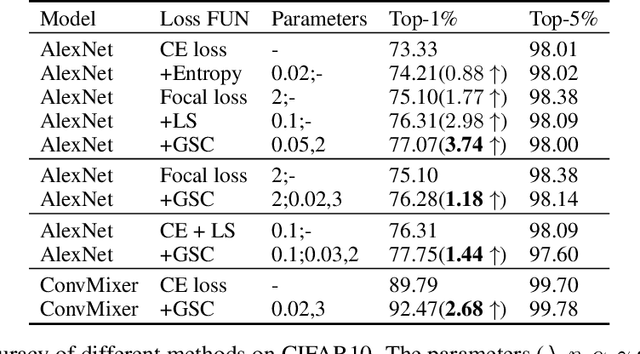
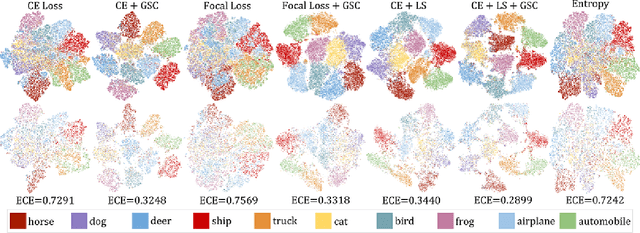
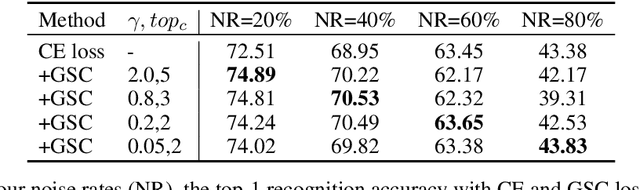
Cross entropy (CE) loss integrated with softmax is an orthodox component in most classification-based frameworks, but it fails to obtain an accurate probability distribution of predicted scores that is critical for further decision-making of poor-classified samples. The prediction score calibration provides a solution to learn the distribution of predicted scores which can explicitly make the model obtain a discriminative representation. Considering the entropy function can be utilized to measure the uncertainty of predicted scores. But, the gradient variation of it is not in line with the expectations of model optimization. To this end, we proposed a general Gaussian Score Calibrating (GSC) loss to calibrate the predicted scores produced by the deep neural networks (DNN). Extensive experiments on over 10 benchmark datasets demonstrate that the proposed GSC loss can yield consistent and significant performance boosts in a variety of visual tasks. Notably, our label-independent GSC loss can be embedded into common improved methods based on the CE loss easily.
HEROHE Challenge: assessing HER2 status in breast cancer without immunohistochemistry or in situ hybridization
Nov 08, 2021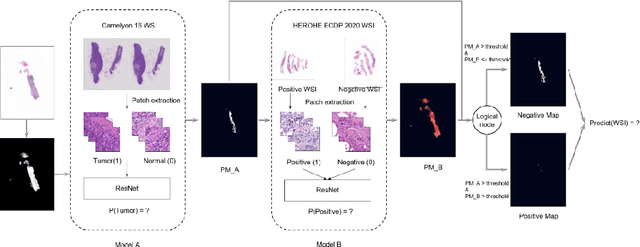
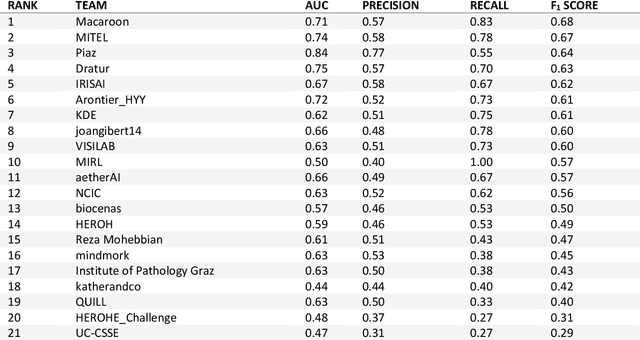
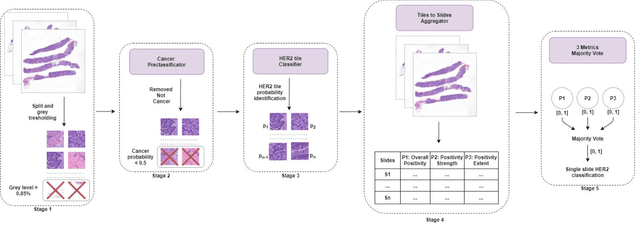
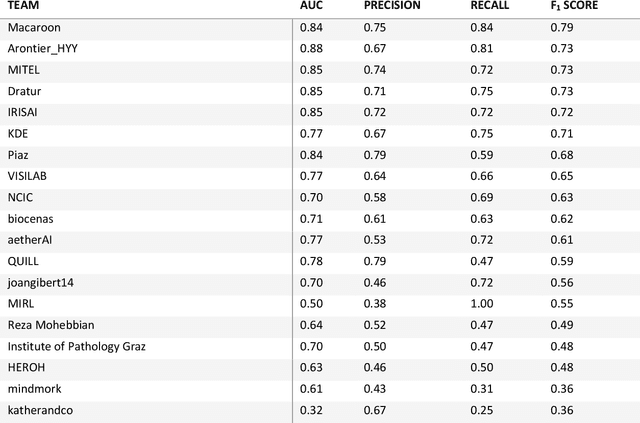
Breast cancer is the most common malignancy in women, being responsible for more than half a million deaths every year. As such, early and accurate diagnosis is of paramount importance. Human expertise is required to diagnose and correctly classify breast cancer and define appropriate therapy, which depends on the evaluation of the expression of different biomarkers such as the transmembrane protein receptor HER2. This evaluation requires several steps, including special techniques such as immunohistochemistry or in situ hybridization to assess HER2 status. With the goal of reducing the number of steps and human bias in diagnosis, the HEROHE Challenge was organized, as a parallel event of the 16th European Congress on Digital Pathology, aiming to automate the assessment of the HER2 status based only on hematoxylin and eosin stained tissue sample of invasive breast cancer. Methods to assess HER2 status were presented by 21 teams worldwide and the results achieved by some of the proposed methods open potential perspectives to advance the state-of-the-art.
Reducing the feature divergence of RGB and near-infrared images using Switchable Normalization
Jun 06, 2021

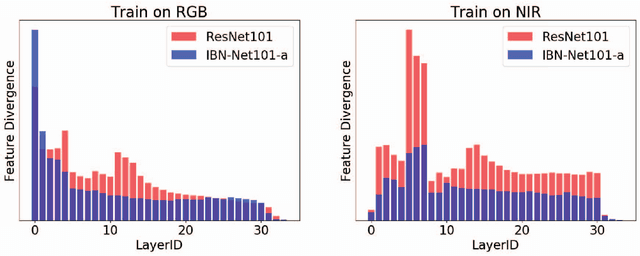
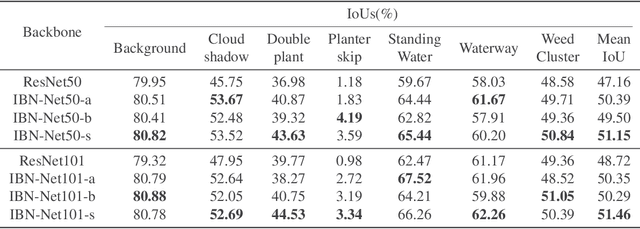
Visual pattern recognition over agricultural areas is an important application of aerial image processing. In this paper, we consider the multi-modality nature of agricultural aerial images and show that naively combining different modalities together without taking the feature divergence into account can lead to sub-optimal results. Thus, we apply a Switchable Normalization block to our DeepLabV3 segmentation model to alleviate the feature divergence. Using the popular symmetric Kullback Leibler divergence measure, we show that our model can greatly reduce the divergence between RGB and near-infrared channels. Together with a hybrid loss function, our model achieves nearly 10\% improvements in mean IoU over previously published baseline.