 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Separation Using Speaker Inventories and Estimated Speech
Oct 20, 2020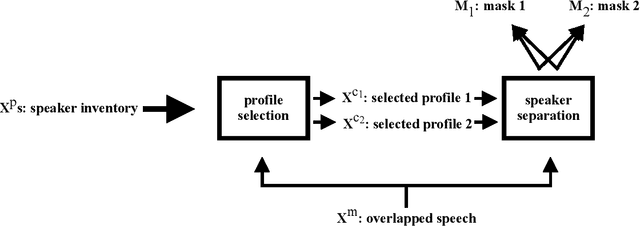
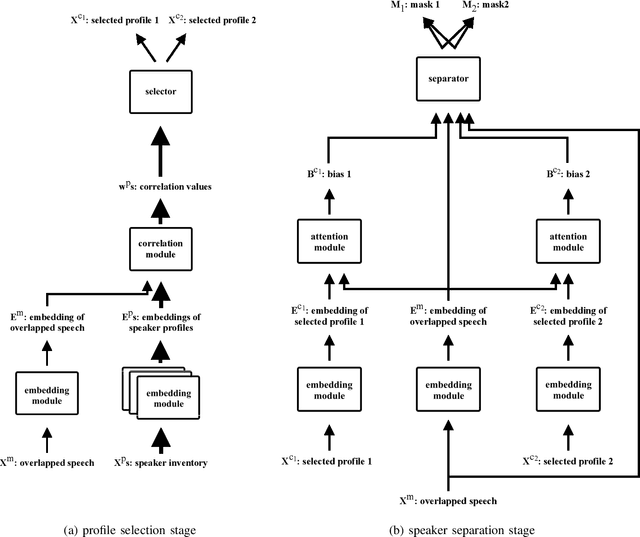
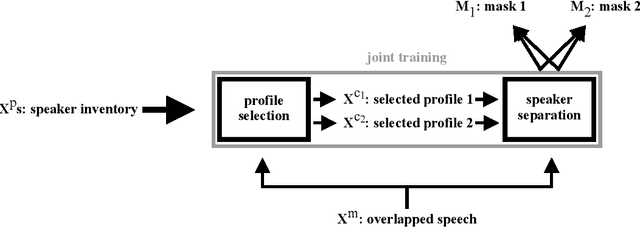
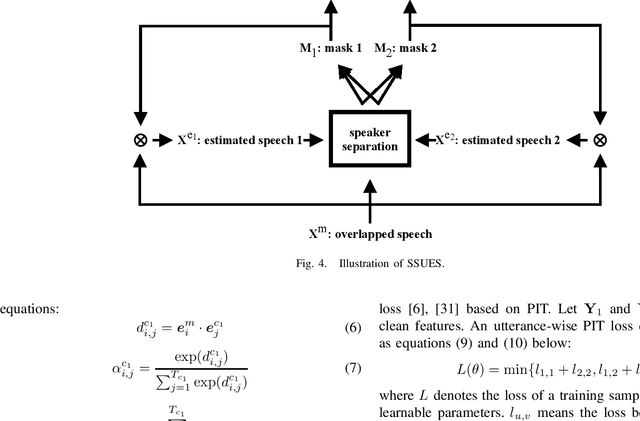
We propose speaker separation using speaker inventories and estimated speech (SSUSIES), a framework leveraging speaker profiles and estimated speech for speaker separation. SSUSIES contains two methods, speaker separation using speaker inventories (SSUSI) and speaker separation using estimated speech (SSUES). SSUSI performs speaker separation with the help of speaker inventory. By combining the advantages of permutation invariant training (PIT) and speech extraction, SSUSI significantly outperforms conventional approaches. SSUES is a widely applicable technique that can substantially improve speaker separation performance using the output of first-pass separation. We evaluate the models on both speaker separation and speech recognition metrics.
Developing RNN-T Models Surpassing High-Performance Hybrid Models with Customization Capability
Jul 30, 2020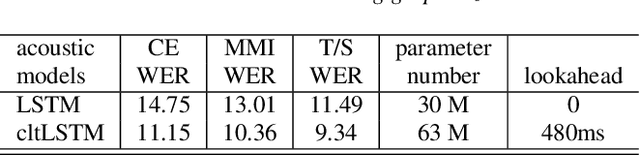
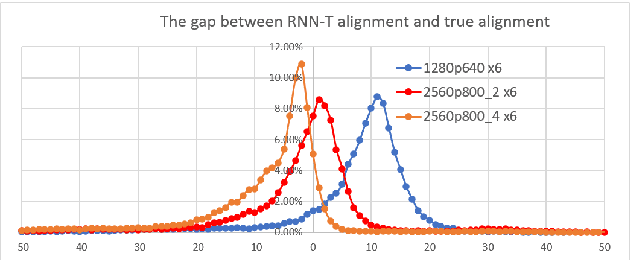
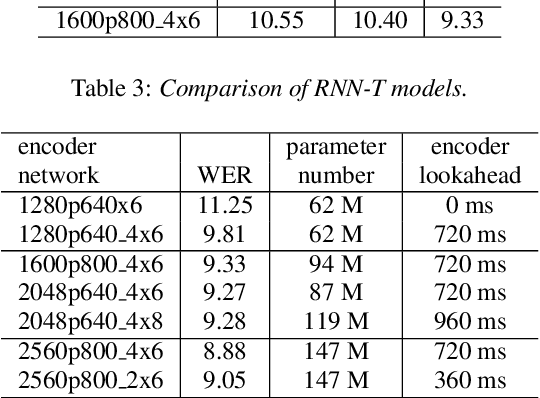
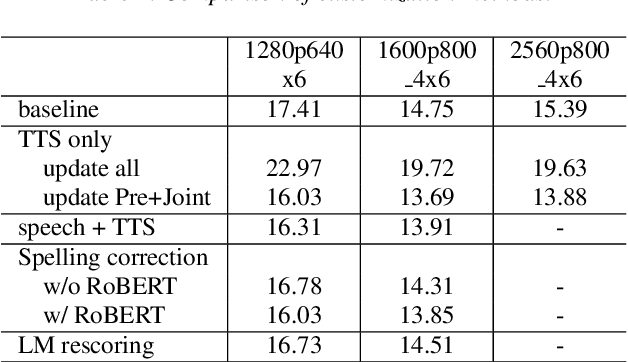
Because of its streaming nature, recurrent neural network transducer (RNN-T) is a very promising end-to-end (E2E) model that may replace the popular hybrid model for automatic speech recognition. In this paper, we describe our recent development of RNN-T models with reduced GPU memory consumption during training, better initialization strategy, and advanced encoder modeling with future lookahead. When trained with Microsoft's 65 thousand hours of anonymized training data, the developed RNN-T model surpasses a very well trained hybrid model with both better recognition accuracy and lower latency. We further study how to customize RNN-T models to a new domain, which is important for deploying E2E models to practical scenarios. By comparing several methods leveraging text-only data in the new domain, we found that updating RNN-T's prediction and joint networks using text-to-speech generated from domain-specific text is the most effective.
Exploring Transformers for Large-Scale Speech Recognition
May 19, 2020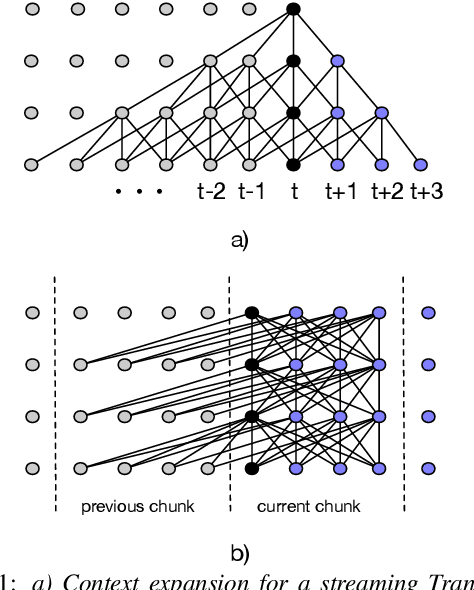
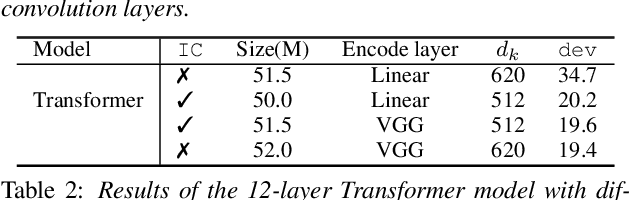
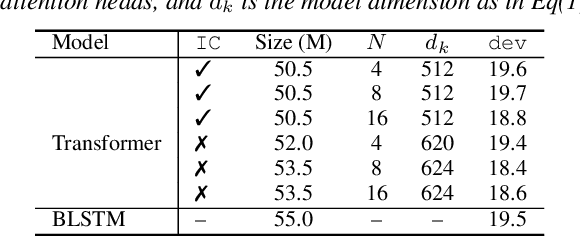
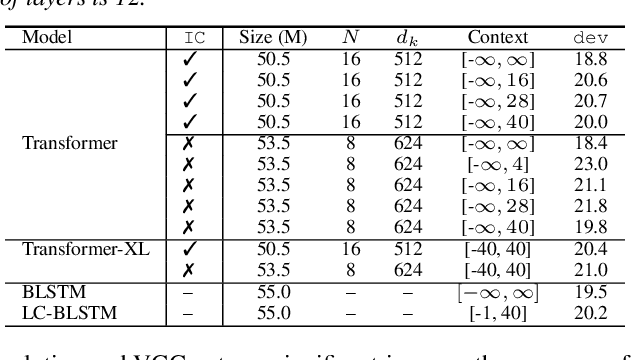
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.
Minimum Latency Training Strategies for Streaming Sequence-to-Sequence ASR
May 15, 2020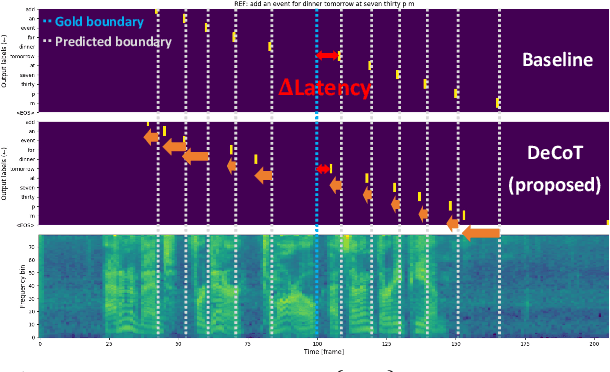

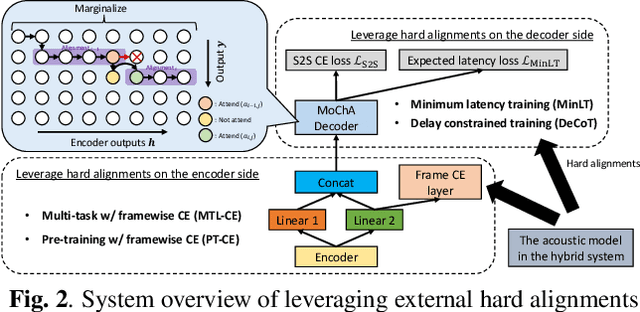
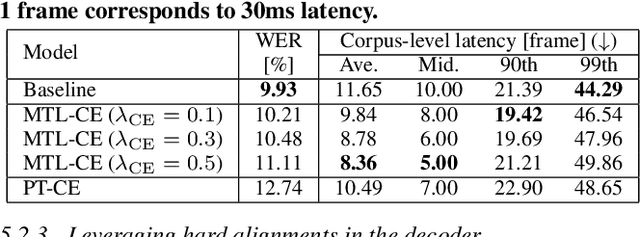
Recently, a few novel streaming attention-based sequence-to-sequence (S2S) models have been proposed to perform online speech recognition with linear-time decoding complexity. However, in these models, the decisions to generate tokens are delayed compared to the actual acoustic boundaries since their unidirectional encoders lack future information. This leads to an inevitable latency during inference. To alleviate this issue and reduce latency, we propose several strategies during training by leveraging external hard alignments extracted from the hybrid model. We investigate to utilize the alignments in both the encoder and the decoder. On the encoder side, (1) multi-task learning and (2) pre-training with the framewise classification task are studied. On the decoder side, we (3) remove inappropriate alignment paths beyond an acceptable latency during the alignment marginalization, and (4) directly minimize the differentiable expected latency loss. Experiments on the Cortana voice search task demonstrate that our proposed methods can significantly reduce the latency, and even improve the recognition accuracy in certain cases on the decoder side. We also present some analysis to understand the behaviors of streaming S2S models.
Exploring Pre-training with Alignments for RNN Transducer based End-to-End Speech Recognition
May 01, 2020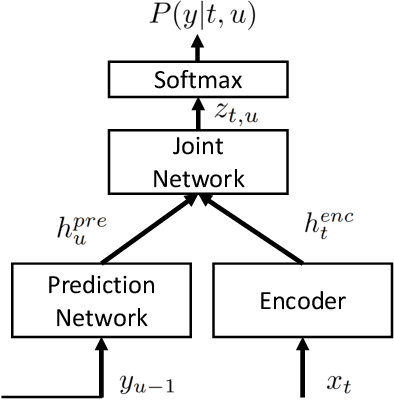

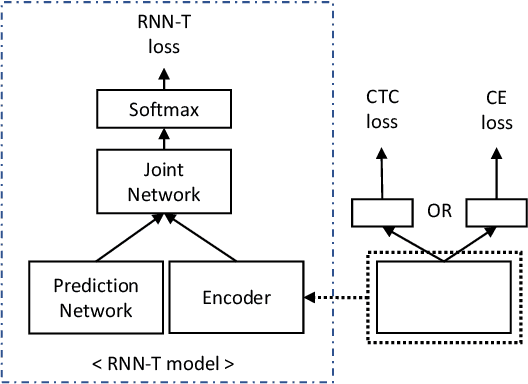
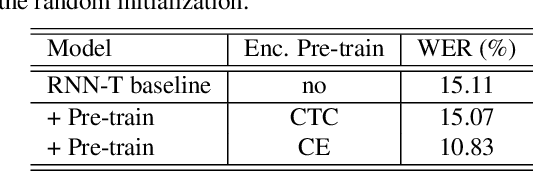
Recently, the recurrent neural network transducer (RNN-T) architecture has become an emerging trend in end-to-end automatic speech recognition research due to its advantages of being capable for online streaming speech recognition. However, RNN-T training is made difficult by the huge memory requirements, and complicated neural structure. A common solution to ease the RNN-T training is to employ connectionist temporal classification (CTC) model along with RNN language model (RNNLM) to initialize the RNN-T parameters. In this work, we conversely leverage external alignments to seed the RNN-T model. Two different pre-training solutions are explored, referred to as encoder pre-training, and whole-network pre-training respectively. Evaluated on Microsoft 65,000 hours anonymized production data with personally identifiable information removed, our proposed methods can obtain significant improvement. In particular, the encoder pre-training solution achieved a 10% and a 8% relative word error rate reduction when compared with random initialization and the widely used CTC+RNNLM initialization strategy, respectively. Our solutions also significantly reduce the RNN-T model latency from the baseline.
L-Vector: Neural Label Embedding for Domain Adaptation
Apr 25, 2020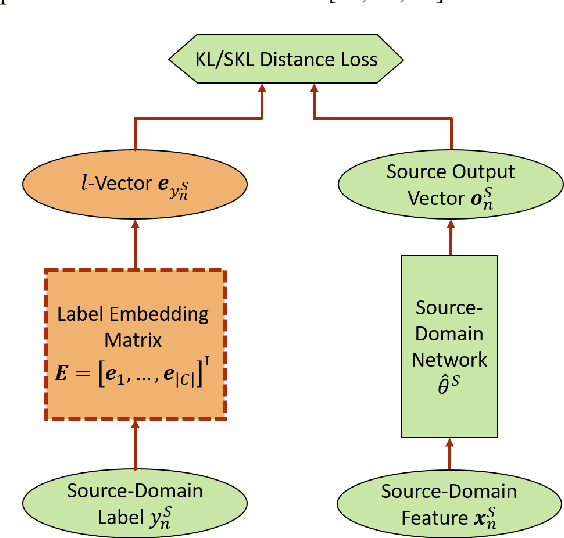
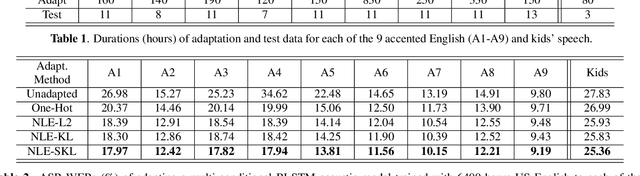
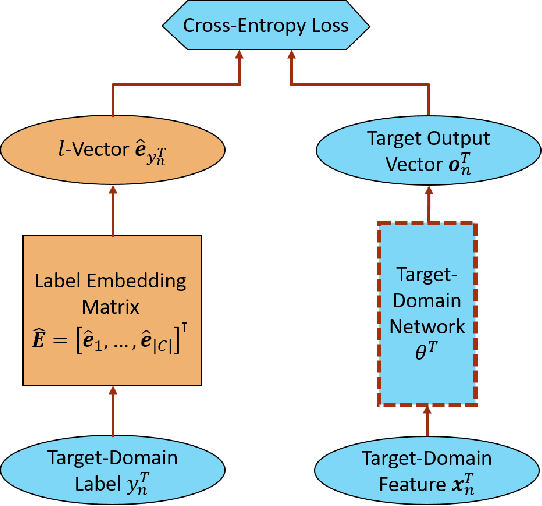
We propose a novel neural label embedding (NLE) scheme for the domain adaptation of a deep neural network (DNN) acoustic model with unpaired data samples from source and target domains. With NLE method, we distill the knowledge from a powerful source-domain DNN into a dictionary of label embeddings, or l-vectors, one for each senone class. Each l-vector is a representation of the senone-specific output distributions of the source-domain DNN and is learned to minimize the average L2, Kullback-Leibler (KL) or symmetric KL distance to the output vectors with the same label through simple averaging or standard back-propagation. During adaptation, the l-vectors serve as the soft targets to train the target-domain model with cross-entropy loss. Without parallel data constraint as in the teacher-student learning, NLE is specially suited for the situation where the paired target-domain data cannot be simulated from the source-domain data. We adapt a 6400 hours multi-conditional US English acoustic model to each of the 9 accented English (80 to 830 hours) and kids' speech (80 hours). NLE achieves up to 14.1% relative word error rate reduction over direct re-training with one-hot labels.
* 5 pages, 2 figure, ICASSP 2020
High-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
Mar 17, 2020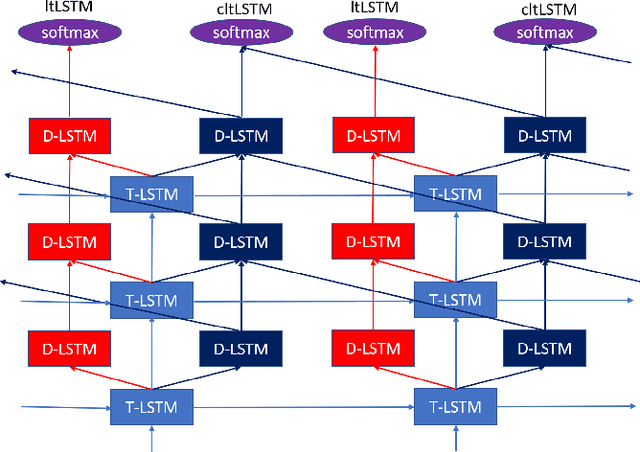
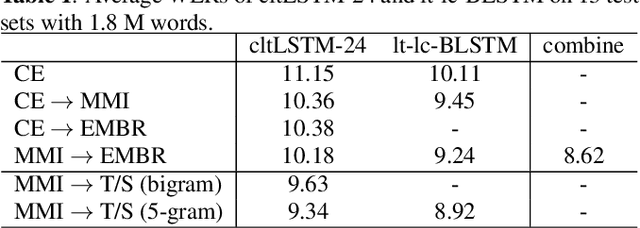
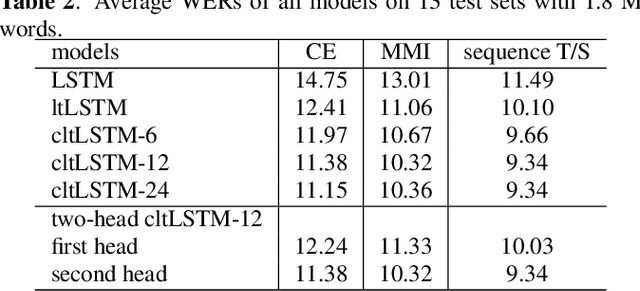
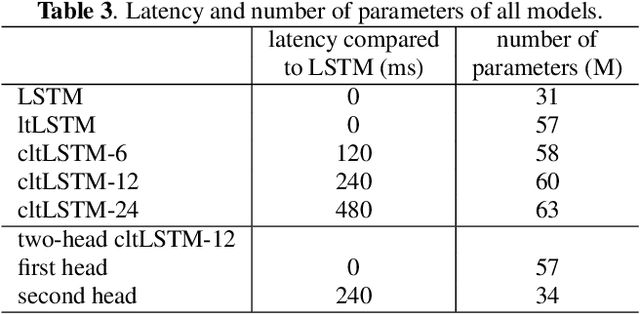
While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved. In this paper, we detail our recent efforts to improve conventional hybrid LSTM acoustic models for high-accuracy and low-latency automatic speech recognition. To achieve high accuracy, we use a contextual layer trajectory LSTM (cltLSTM), which decouples the temporal modeling and target classification tasks, and incorporates future context frames to get more information for accurate acoustic modeling. We further improve the training strategy with sequence-level teacher-student learning. To obtain low latency, we design a two-head cltLSTM, in which one head has zero latency and the other head has a small latency, compared to an LSTM. When trained with Microsoft's 65 thousand hours of anonymized training data and evaluated with test sets with 1.8 million words, the proposed two-head cltLSTM model with the proposed training strategy yields a 28.2\% relative WER reduction over the conventional LSTM acoustic model, with a similar perceived latency.
A Privacy-Preserving DNN Pruning and Mobile Acceleration Framework
Mar 13, 2020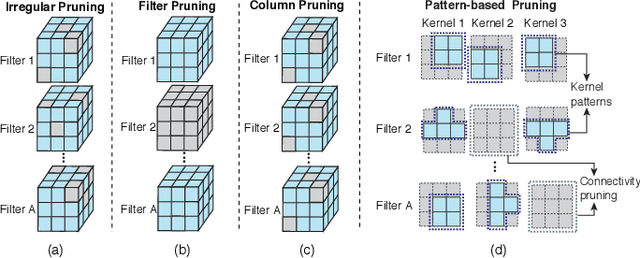
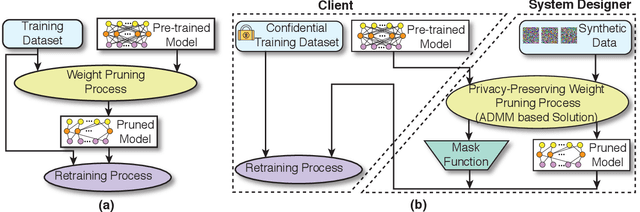
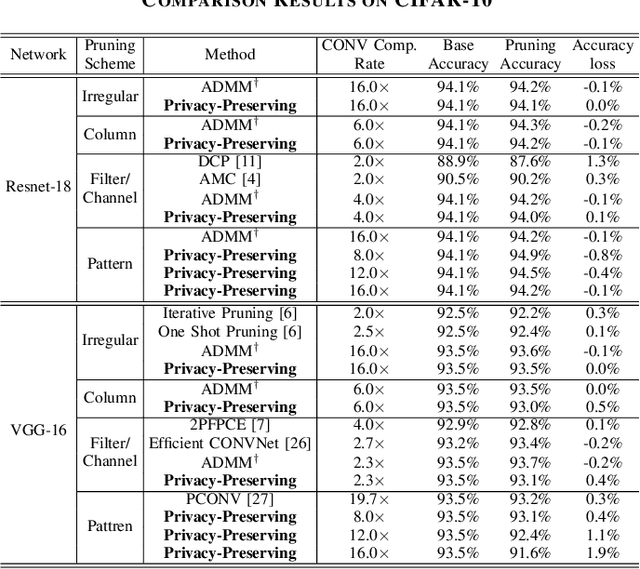
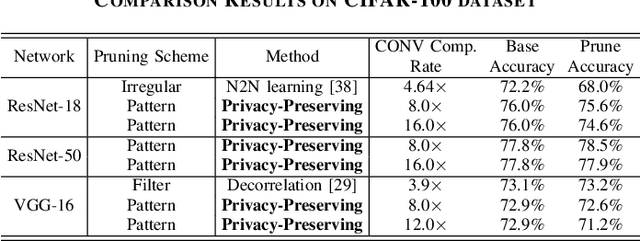
To facilitate the deployment of deep neural networks (DNNs) on resource-constrained computing systems, DNN model compression methods have been proposed. However, previous methods mainly focus on reducing the model size and/or improving hardware performance, without considering the data privacy requirement. This paper proposes a privacy-preserving model compression framework that formulates a privacy-preserving DNN weight pruning problem and develops an ADMM based solution to support different weight pruning schemes. We consider the case that the system designer will perform weight pruning on a pre-trained model provided by the client, whereas the client cannot share her confidential training dataset. To mitigate the non-availability of the training dataset, the system designer distills the knowledge of a pre-trained model into a pruned model using only randomly generated synthetic data. Then the client's effort is simply reduced to performing the retraining process using her confidential training dataset, which is similar as the DNN training process with the help of the mask function from the system designer. Both algorithmic and hardware experiments validate the effectiveness of the proposed framework.
BLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Feb 22, 2020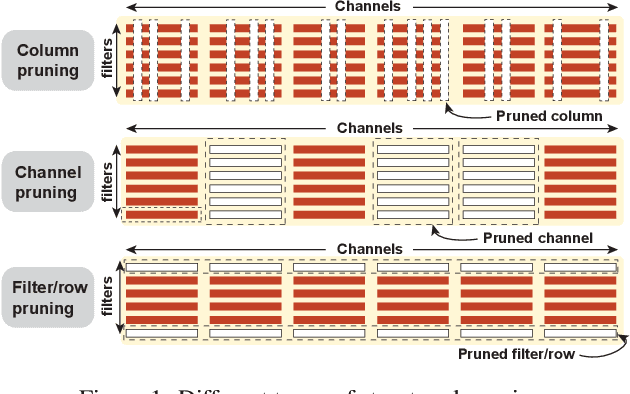
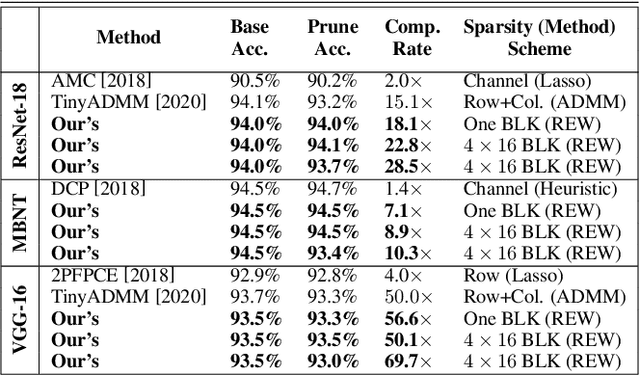
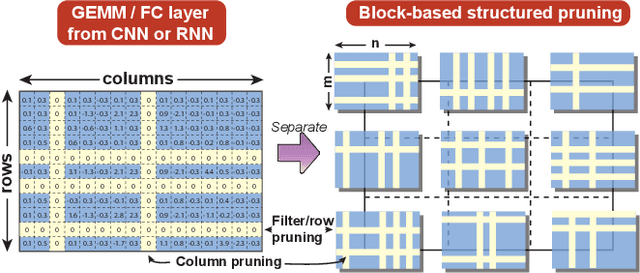
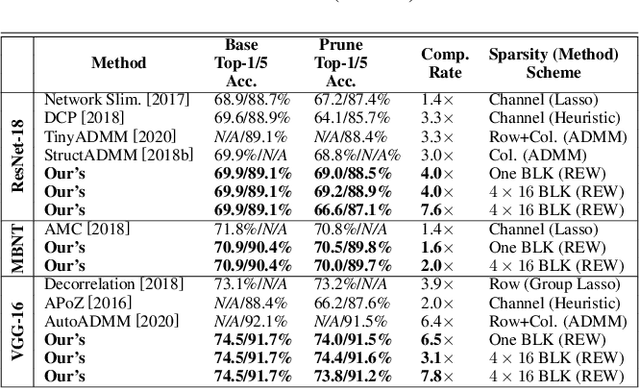
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020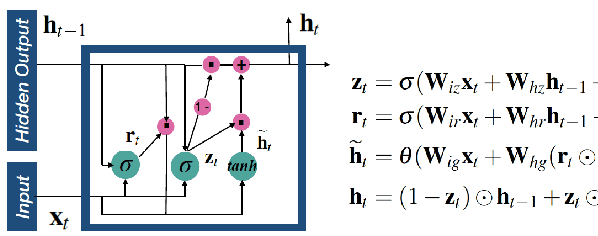
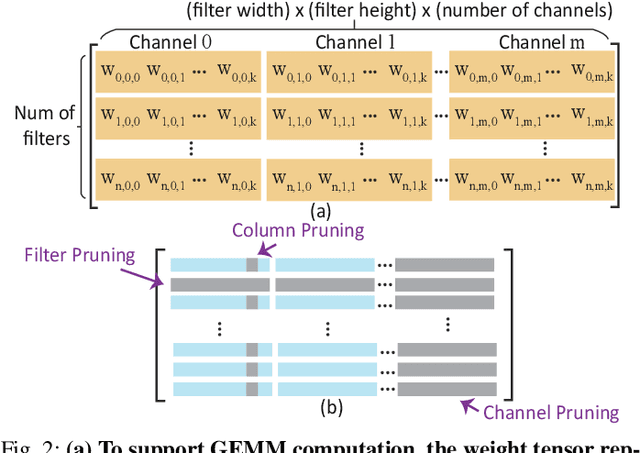
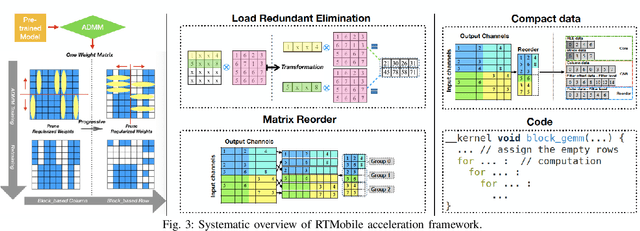
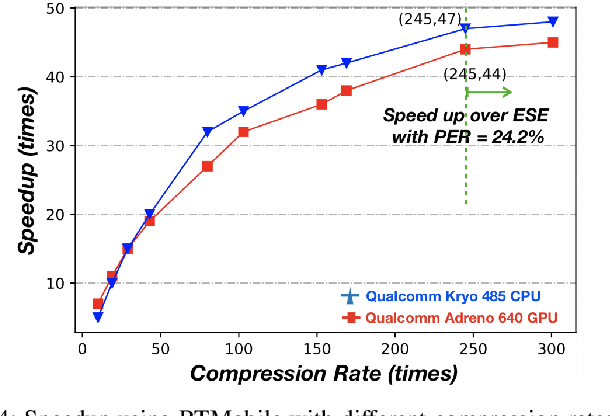
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.