 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-hallucination Synthetic Captions for Large-Scale Vision-Language Model Pre-training
Apr 17, 2025In recent years, the field of vision-language model pre-training has experienced rapid advancements, driven primarily by the continuous enhancement of textual capabilities in large language models. However, existing training paradigms for multimodal large language models heavily rely on high-quality image-text pairs. As models and data scales grow exponentially, the availability of such meticulously curated data has become increasingly scarce and saturated, thereby severely limiting further advancements in this domain. This study investigates scalable caption generation techniques for vision-language model pre-training and demonstrates that large-scale low-hallucination synthetic captions can serve dual purposes: 1) acting as a viable alternative to real-world data for pre-training paradigms and 2) achieving superior performance enhancement when integrated into vision-language models through empirical validation. This paper presents three key contributions: 1) a novel pipeline for generating high-quality, low-hallucination, and knowledge-rich synthetic captions. Our continuous DPO methodology yields remarkable results in reducing hallucinations. Specifically, the non-hallucination caption rate on a held-out test set increases from 48.2% to 77.9% for a 7B-size model. 2) Comprehensive empirical validation reveals that our synthetic captions confer superior pre-training advantages over their counterparts. Across 35 vision language tasks, the model trained with our data achieves a significant performance gain of at least 6.2% compared to alt-text pairs and other previous work. Meanwhile, it also offers considerable support in the text-to-image domain. With our dataset, the FID score is reduced by 17.1 on a real-world validation benchmark and 13.3 on the MSCOCO validation benchmark. 3) We will release Hunyuan-Recap100M, a low-hallucination and knowledge-intensive synthetic caption dataset.
Variational Bayesian Adaptive Learning of Deep Latent Variables for Acoustic Knowledge Transfer
Jan 26, 2025
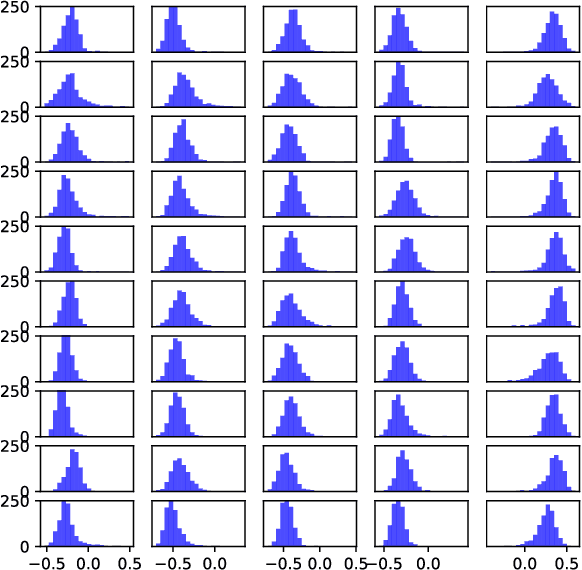
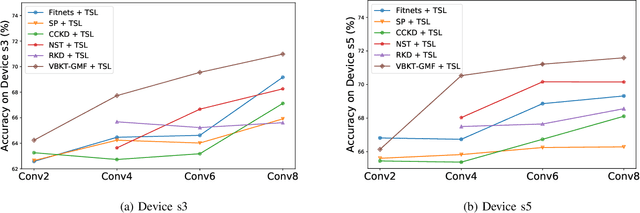

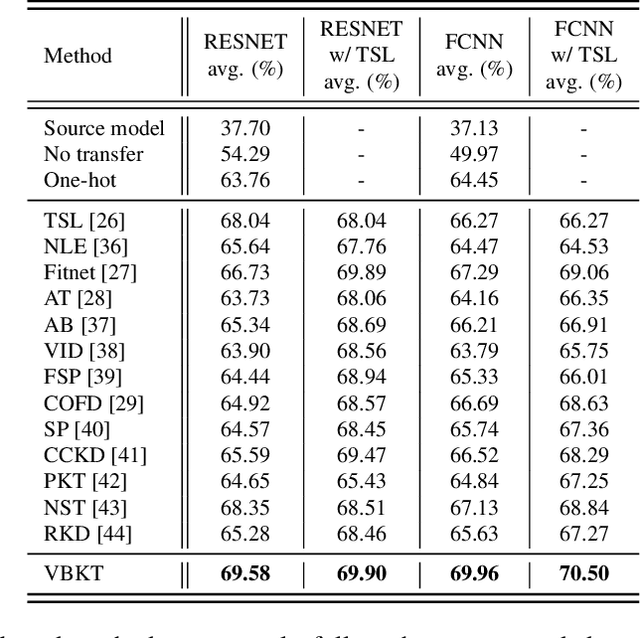
In this work, we propose a novel variational Bayesian adaptive learning approach for cross-domain knowledge transfer to address acoustic mismatches between training and testing conditions, such as recording devices and environmental noise. Different from the traditional Bayesian approaches that impose uncertainties on model parameters risking the curse of dimensionality due to the huge number of parameters, we focus on estimating a manageable number of latent variables in deep neural models. Knowledge learned from a source domain is thus encoded in prior distributions of deep latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Two different strategies are proposed and investigated to estimate the posterior distributions: Gaussian mean-field variational inference, and empirical Bayes. These strategies address the presence or absence of parallel data in the source and target domains. Furthermore, structural relationship modeling is investigated to enhance the approximation. We evaluated our proposed approaches on two acoustic adaptation tasks: 1) device adaptation for acoustic scene classification, and 2) noise adaptation for spoken command recognition. Experimental results show that the proposed variational Bayesian adaptive learning approach can obtain good improvements on target domain data, and consistently outperforms state-of-the-art knowledge transfer methods.
Bayesian adaptive learning to latent variables via Variational Bayes and Maximum a Posteriori
Jan 24, 2024In this work, we aim to establish a Bayesian adaptive learning framework by focusing on estimating latent variables in deep neural network (DNN) models. Latent variables indeed encode both transferable distributional information and structural relationships. Thus the distributions of the source latent variables (prior) can be combined with the knowledge learned from the target data (likelihood) to yield the distributions of the target latent variables (posterior) with the goal of addressing acoustic mismatches between training and testing conditions. The prior knowledge transfer is accomplished through Variational Bayes (VB). In addition, we also investigate Maximum a Posteriori (MAP) based Bayesian adaptation. Experimental results on device adaptation in acoustic scene classification show that our proposed approaches can obtain good improvements on target devices, and consistently outperforms other cut-edging algorithms.
TeachCLIP: Multi-Grained Teaching for Efficient Text-to-Video Retrieval
Aug 02, 2023For text-to-video retrieval (T2VR), which aims to retrieve unlabeled videos by ad-hoc textual queries, CLIP-based methods are dominating. Compared to CLIP4Clip which is efficient and compact, the state-of-the-art models tend to compute video-text similarity by fine-grained cross-modal feature interaction and matching, putting their scalability for large-scale T2VR into doubt. For efficient T2VR, we propose TeachCLIP with multi-grained teaching to let a CLIP4Clip based student network learn from more advanced yet computationally heavy models such as X-CLIP, TS2-Net and X-Pool . To improve the student's learning capability, we add an Attentional frame-Feature Aggregation (AFA) block, which by design adds no extra storage/computation overhead at the retrieval stage. While attentive weights produced by AFA are commonly used for combining frame-level features, we propose a novel use of the weights to let them imitate frame-text relevance estimated by the teacher network. As such, AFA provides a fine-grained learning (teaching) channel for the student (teacher). Extensive experiments on multiple public datasets justify the viability of the proposed method.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022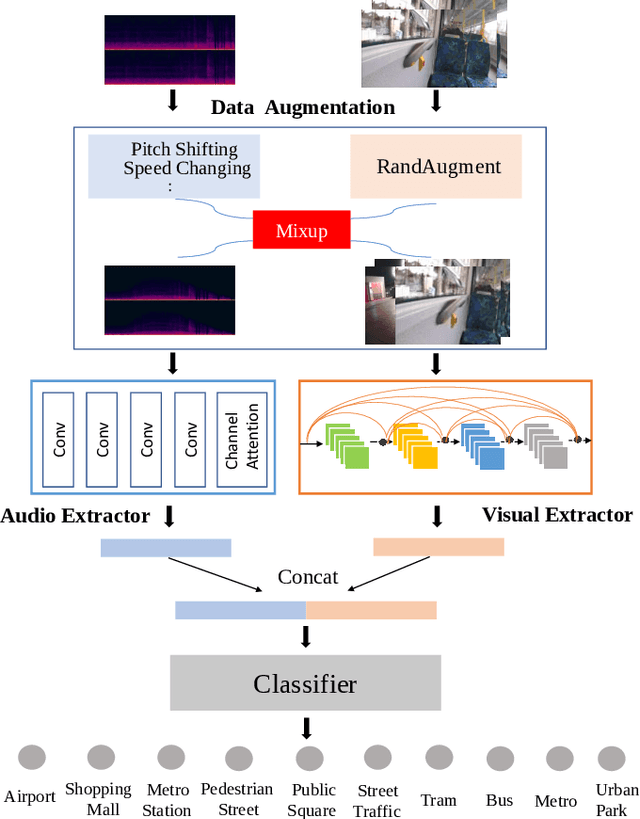
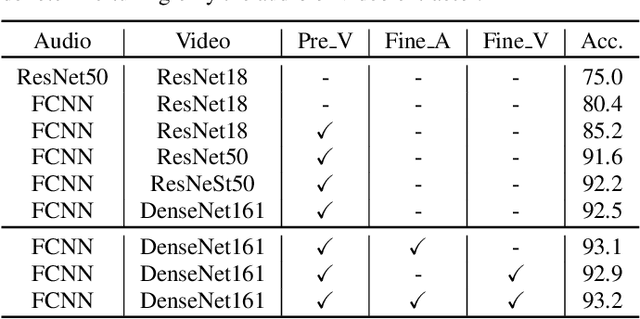
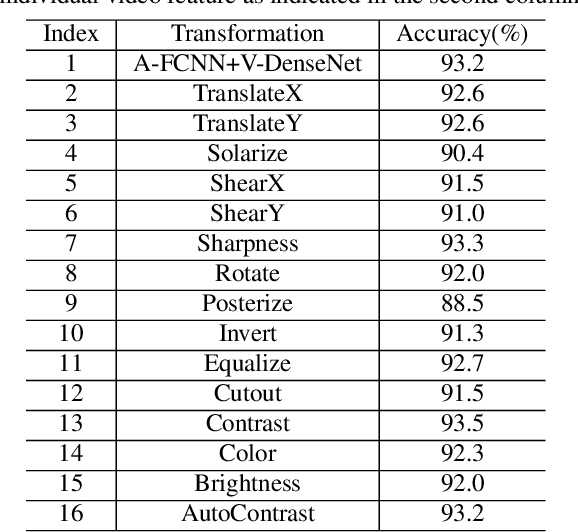
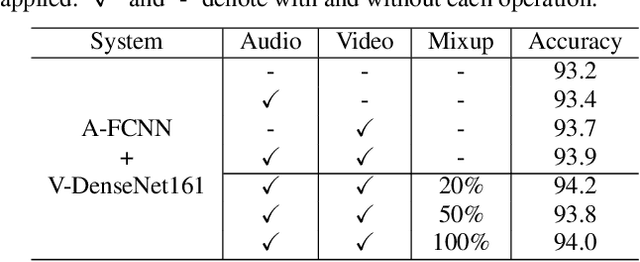
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
A Variational Bayesian Approach to Learning Latent Variables for Acoustic Knowledge Transfer
Oct 16, 2021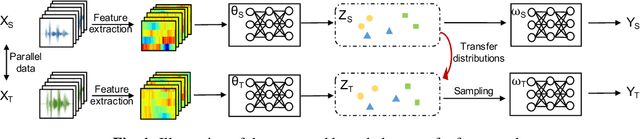
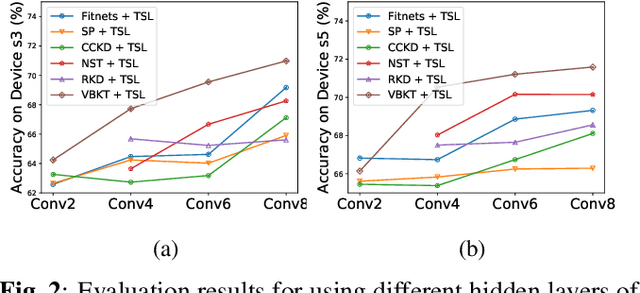
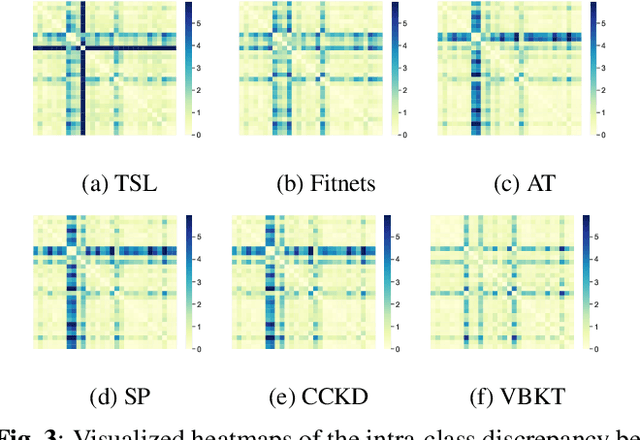
We propose a variational Bayesian (VB) approach to learning distributions of latent variables in deep neural network (DNN) models for cross-domain knowledge transfer, to address acoustic mismatches between training and testing conditions. Instead of carrying out point estimation in conventional maximum a posteriori estimation with a risk of having a curse of dimensionality in estimating a huge number of model parameters, we focus our attention on estimating a manageable number of latent variables of DNNs via a VB inference framework. To accomplish model transfer, knowledge learnt from a source domain is encoded in prior distributions of latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Experimental results on device adaptation in acoustic scene classification show that our proposed VB approach can obtain good improvements on target devices, and consistently outperforms 13 state-of-the-art knowledge transfer algorithms.
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021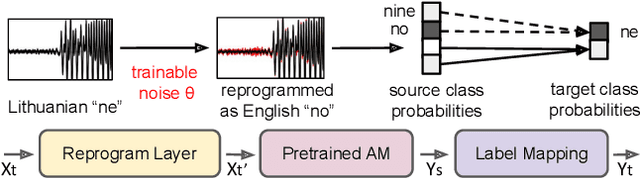
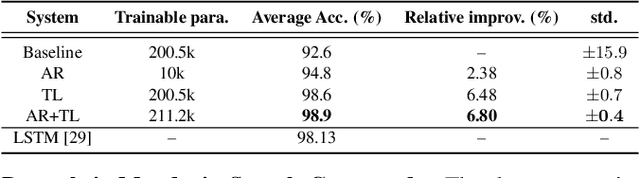
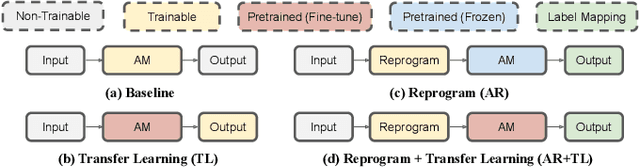
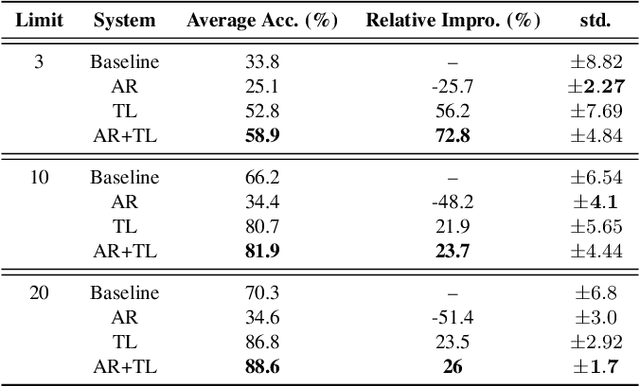
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.
A Lottery Ticket Hypothesis Framework for Low-Complexity Device-Robust Neural Acoustic Scene Classification
Jul 03, 2021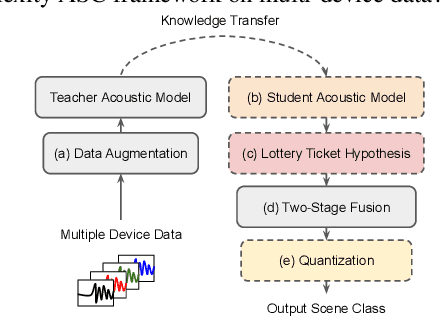
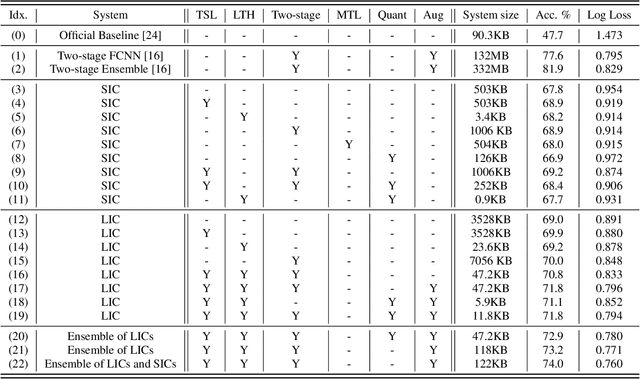
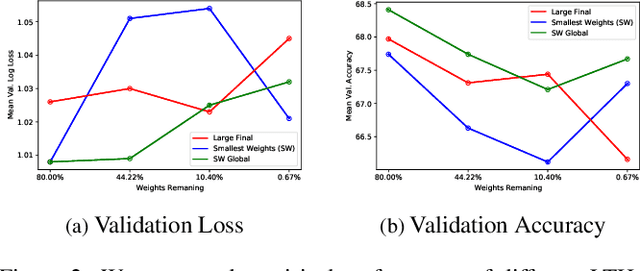

We propose a novel neural model compression strategy combining data augmentation, knowledge transfer, pruning, and quantization for device-robust acoustic scene classification (ASC). Specifically, we tackle the ASC task in a low-resource environment leveraging a recently proposed advanced neural network pruning mechanism, namely Lottery Ticket Hypothesis (LTH), to find a sub-network neural model associated with a small amount non-zero model parameters. The effectiveness of LTH for low-complexity acoustic modeling is assessed by investigating various data augmentation and compression schemes, and we report an efficient joint framework for low-complexity multi-device ASC, called Acoustic Lottery. Acoustic Lottery could compress an ASC model over $1/10^{4}$ and attain a superior performance (validation accuracy of 74.01% and Log loss of 0.76) compared to its not compressed seed model. All results reported in this work are based on a joint effort of four groups, namely GT-USTC-UKE-Tencent, aiming to address the "Low-Complexity Acoustic Scene Classification (ASC) with Multiple Devices" in the DCASE 2021 Challenge Task 1a.
* 5 figures. DCASE 2021. The project started in November 2020
REDAT: Accent-Invariant Representation for End-to-End ASR by Domain Adversarial Training with Relabeling
Dec 14, 2020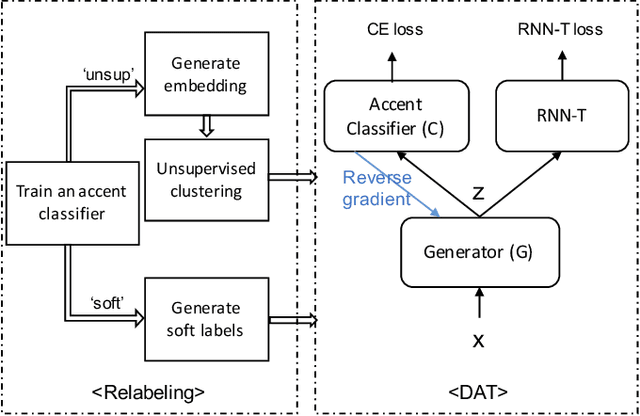
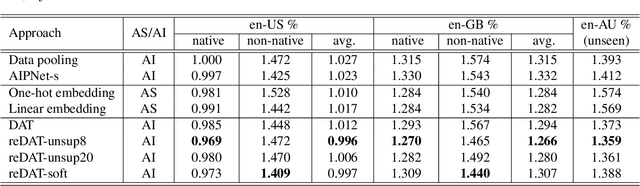
Accents mismatching is a critical problem for end-to-end ASR. This paper aims to address this problem by building an accent-robust RNN-T system with domain adversarial training (DAT). We unveil the magic behind DAT and provide, for the first time, a theoretical guarantee that DAT learns accent-invariant representations. We also prove that performing the gradient reversal in DAT is equivalent to minimizing the Jensen-Shannon divergence between domain output distributions. Motivated by the proof of equivalence, we introduce reDAT, a novel technique based on DAT, which relabels data using either unsupervised clustering or soft labels. Experiments on 23K hours of multi-accent data show that DAT achieves competitive results over accent-specific baselines on both native and non-native English accents but up to 13% relative WER reduction on unseen accents; our reDAT yields further improvements over DAT by 3% and 8% relatively on non-native accents of American and British English.
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020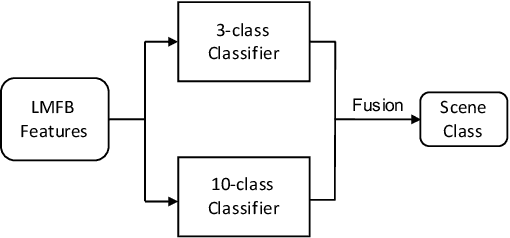

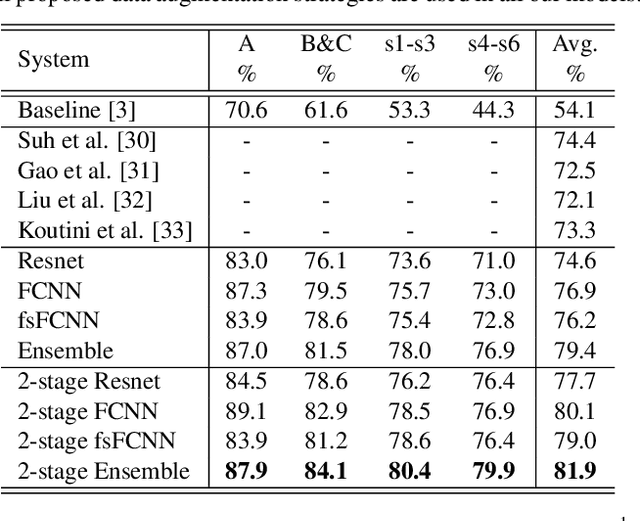
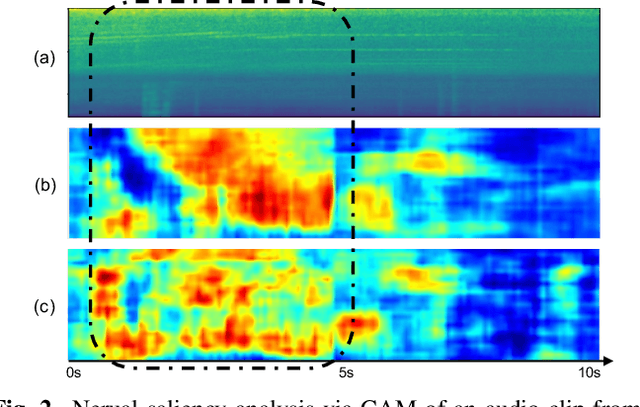
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.