 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroth Order Non-convex optimization with Dueling-Choice Bandits
Nov 03, 2019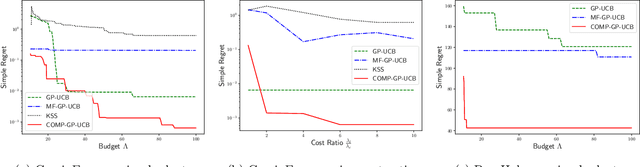
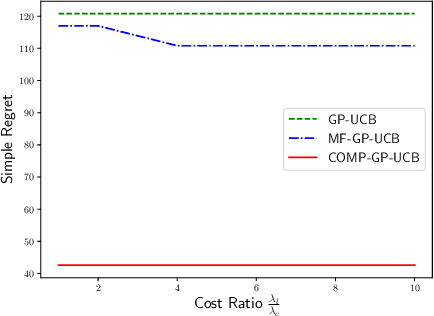
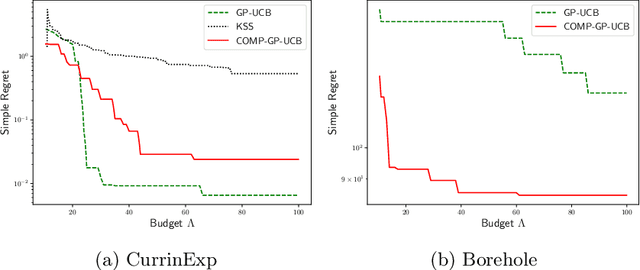
We consider a novel setting of zeroth order non-convex optimization, where in addition to querying the function value at a given point, we can also duel two points and get the point with the larger function value. We refer to this setting as optimization with dueling-choice bandits since both direct queries and duels are available for optimization. We give the COMP-GP-UCB algorithm based on GP-UCB (Srinivas et al., 2009), where instead of directly querying the point with the maximum Upper Confidence Bound (UCB), we perform a constrained optimization and use comparisons to filter out suboptimal points. COMP-GP-UCB comes with theoretical guarantee of $O(\frac{\Phi}{\sqrt{T}})$ on simple regret where $T$ is the number of direct queries and $\Phi$ is an improved information gain corresponding to a comparison based constraint set that restricts the search space for the optimum. In contrast, in the direct query only setting, $\Phi$ depends on the entire domain. Finally, we present experimental results to show the efficacy of our algorithm.
Active Learning for Graph Neural Networks via Node Feature Propagation
Oct 16, 2019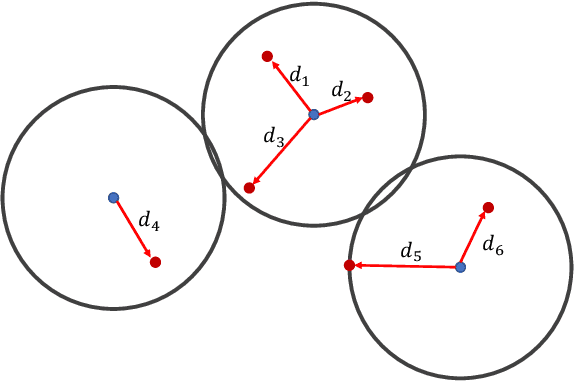
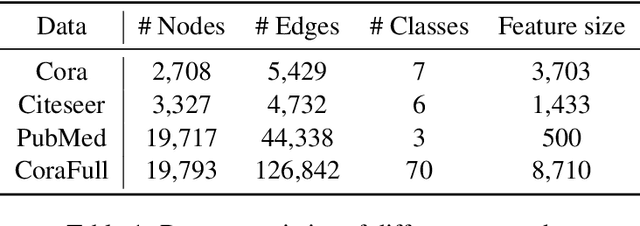
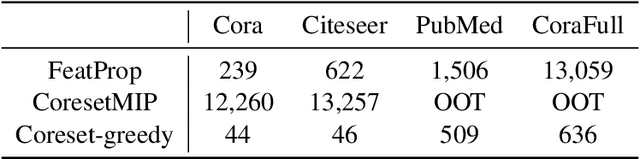
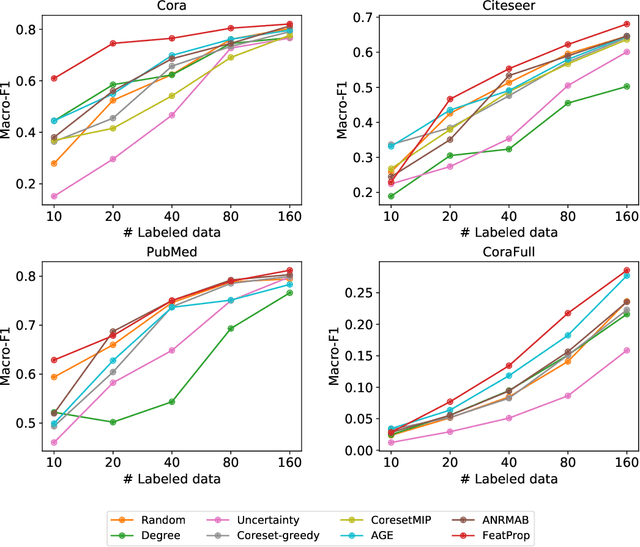
Graph Neural Networks (GNNs) for prediction tasks like node classification or edge prediction have received increasing attention in recent machine learning from graphically structured data. However, a large quantity of labeled graphs is difficult to obtain, which significantly limits the true success of GNNs. Although active learning has been widely studied for addressing label-sparse issues with other data types like text, images, etc., how to make it effective over graphs is an open question for research. In this paper, we present an investigation on active learning with GNNs for node classification tasks. Specifically, we propose a new method, which uses node feature propagation followed by K-Medoids clustering of the nodes for instance selection in active learning. With a theoretical bound analysis we justify the design choice of our approach. In our experiments on four benchmark datasets, the proposed method outperforms other representative baseline methods consistently and significantly.
Thresholding Bandit Problem with Both Duels and Pulls
Oct 14, 2019
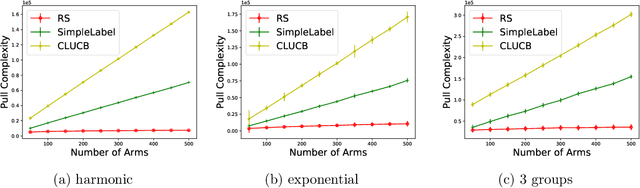

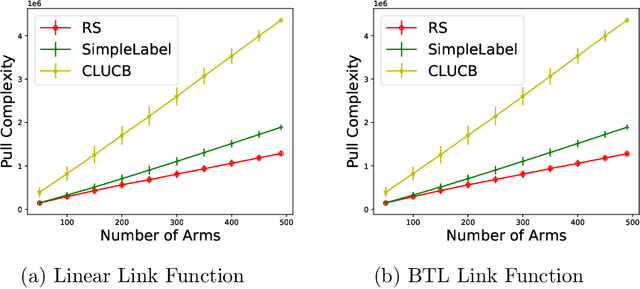
The Thresholding Bandit Problem (TBP) aims to find the set of arms with mean rewards greater than a given threshold. We consider a new setting of TBP, where in addition to pulling arms, one can also duel two arms and get the arm with a greater mean. In our motivating application from crowdsourcing, dueling two arms can be more cost and time efficient than direct pulls. We refer to this problem as TBP with Dueling Choices (TBP-DC). This paper provides an algorithm called Rank-Search (RS) for solving TBP-DC by alternating between ranking and binary search. We prove theoretical guarantees for RS, and also give lower bounds to show the optimality of it. Experiments show that RS outperforms previous baseline algorithms that only use pulls or duels.
DoubleTransfer at MEDIQA 2019: Multi-Source Transfer Learning for Natural Language Understanding in the Medical Domain
Jun 11, 2019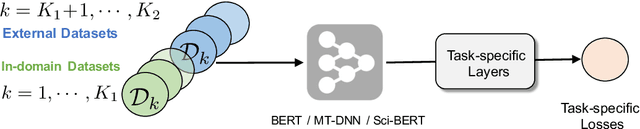
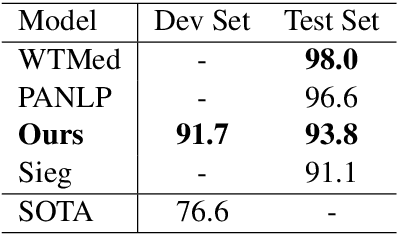
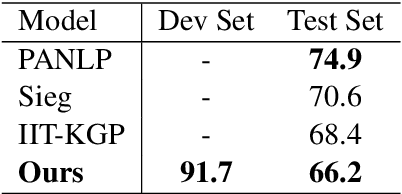
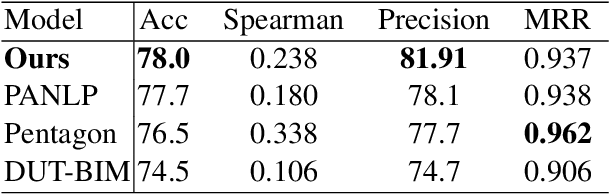
This paper describes our competing system to enter the MEDIQA-2019 competition. We use a multi-source transfer learning approach to transfer the knowledge from MT-DNN and SciBERT to natural language understanding tasks in the medical domain. For transfer learning fine-tuning, we use multi-task learning on NLI, RQE and QA tasks on general and medical domains to improve performance. The proposed methods are proved effective for natural language understanding in the medical domain, and we rank the first place on the QA task.
Multi-Task Learning for Machine Reading Comprehension
Sep 18, 2018
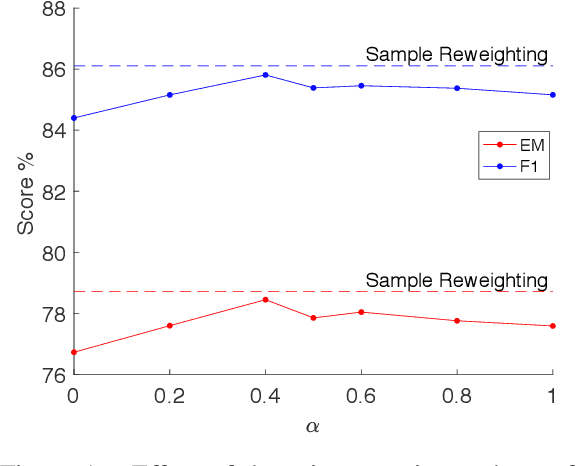
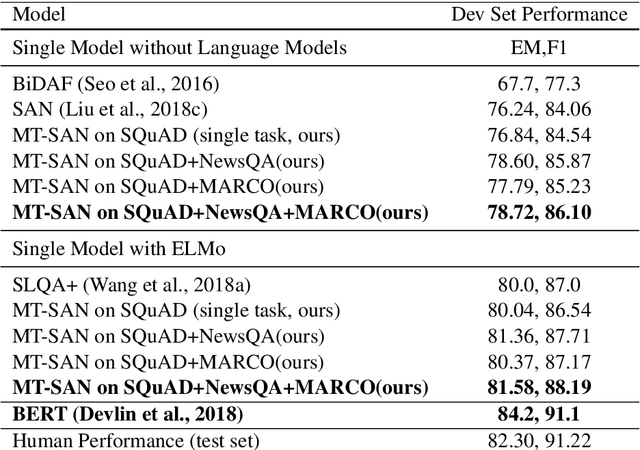
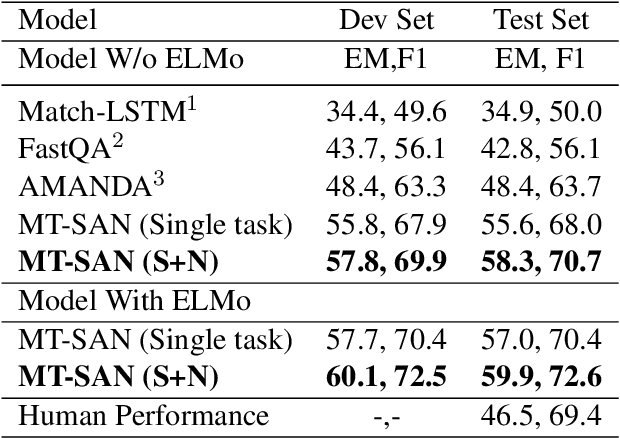
We propose a multi-task learning framework to jointly train a Machine Reading Comprehension (MRC) model on multiple datasets across different domains. Key to the proposed method is to learn robust and general contextual representations with the help of out-domain data in a multi-task framework. Empirical study shows that the proposed approach is orthogonal to the existing pre-trained representation models, such as word embedding and language models. Experiments on the Stanford Question Answering Dataset (SQuAD), the Microsoft MAchine Reading COmprehension Dataset (MS MARCO), NewsQA and other datasets show that our multi-task learning approach achieves significant improvement over state-of-the-art models in most MRC tasks.
On Strategyproof Conference Peer Review
Jun 16, 2018
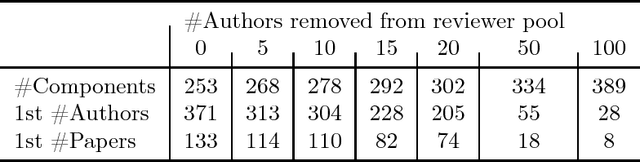

We consider peer review in a conference setting where there is typically an overlap between the set of reviewers and the set of authors. This overlap can incentivize strategic reviews to influence the final ranking of one's own papers. In this work, we address this problem through the lens of social choice, and present a theoretical framework for strategyproof and efficient peer review. We first present and analyze an algorithm for reviewer-assignment and aggregation that guarantees strategyproofness and a natural efficiency property called unanimity, when the authorship graph satisfies a simple property. Our algorithm is based on the so-called partitioning method, and can be thought as a generalization of this method to conference peer review settings. We then empirically show that the requisite property on the authorship graph is indeed satisfied in the ICLR-17 submission data, and further demonstrate a simple trick to make the partitioning method more practically appealing for conference peer review. Finally, we complement our positive results with negative theoretical results where we prove that under various ways of strengthening the requirements, it is impossible for any algorithm to be strategyproof and efficient.
Nonparametric Regression with Comparisons: Escaping the Curse of Dimensionality with Ordinal Information
Jun 08, 2018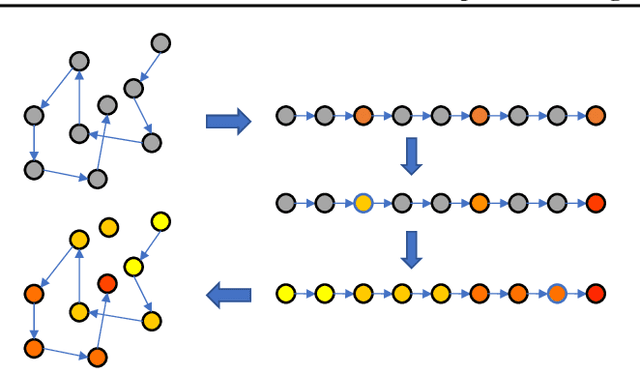
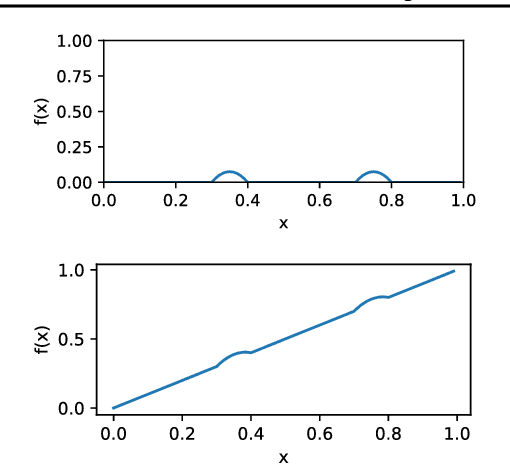
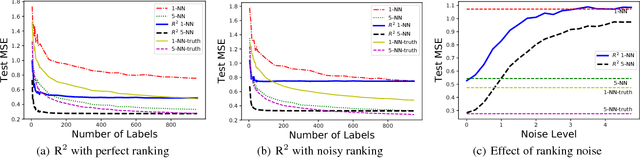
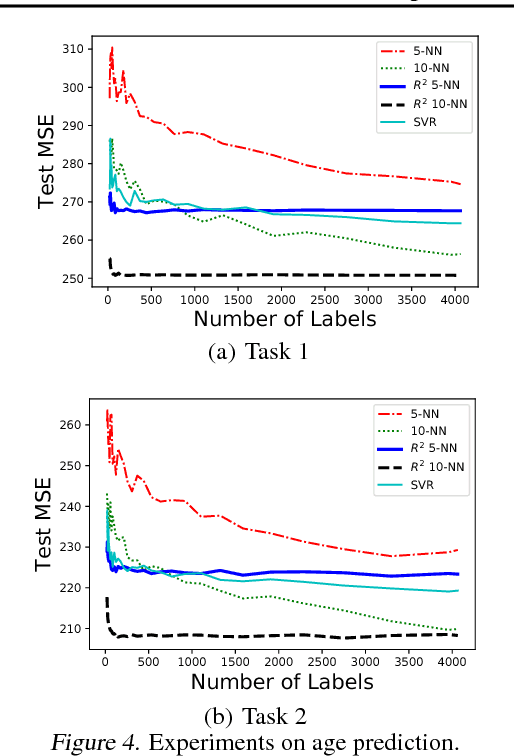
In supervised learning, we leverage a labeled dataset to design methods for function estimation. In many practical situations, we are able to obtain alternative feedback, possibly at a low cost. A broad goal is to understand the usefulness of, and to design algorithms to exploit, this alternative feedback. We focus on a semi-supervised setting where we obtain additional ordinal (or comparison) information for potentially unlabeled samples. We consider ordinal feedback of varying qualities where we have either a perfect ordering of the samples, a noisy ordering of the samples or noisy pairwise comparisons between the samples. We provide a precise quantification of the usefulness of these types of ordinal feedback in non-parametric regression, showing that in many cases it is possible to accurately estimate an underlying function with a very small labeled set, effectively escaping the curse of dimensionality. We develop an algorithm called Ranking-Regression (RR) and analyze its accuracy as a function of size of the labeled and unlabeled datasets and various noise parameters. We also present lower bounds, that establish fundamental limits for the task and show that RR is optimal in a variety of settings. Finally, we present experiments that show the efficacy of RR and investigate its robustness to various sources of noise and model-misspecification.
Dynamic Fusion Networks for Machine Reading Comprehension
Feb 26, 2018
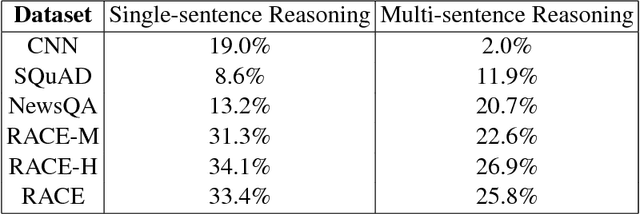

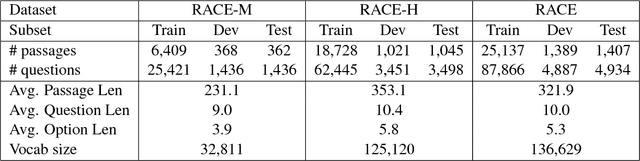
This paper presents a novel neural model - Dynamic Fusion Network (DFN), for machine reading comprehension (MRC). DFNs differ from most state-of-the-art models in their use of a dynamic multi-strategy attention process, in which passages, questions and answer candidates are jointly fused into attention vectors, along with a dynamic multi-step reasoning module for generating answers. With the use of reinforcement learning, for each input sample that consists of a question, a passage and a list of candidate answers, an instance of DFN with a sample-specific network architecture can be dynamically constructed by determining what attention strategy to apply and how many reasoning steps to take. Experiments show that DFNs achieve the best result reported on RACE, a challenging MRC dataset that contains real human reading questions in a wide variety of types. A detailed empirical analysis also demonstrates that DFNs can produce attention vectors that summarize information from questions, passages and answer candidates more effectively than other popular MRC models.
Noise-Tolerant Interactive Learning from Pairwise Comparisons
May 19, 2017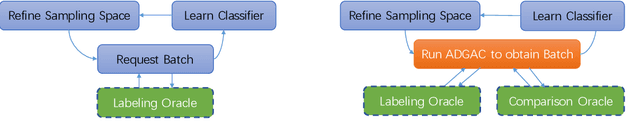


We study the problem of interactively learning a binary classifier using noisy labeling and pairwise comparison oracles, where the comparison oracle answers which one in the given two instances is more likely to be positive. Learning from such oracles has multiple applications where obtaining direct labels is harder but pairwise comparisons are easier, and the algorithm can leverage both types of oracles. In this paper, we attempt to characterize how the access to an easier comparison oracle helps in improving the label and total query complexity. We show that the comparison oracle reduces the learning problem to that of learning a threshold function. We then present an algorithm that interactively queries the label and comparison oracles and we characterize its query complexity under Tsybakov and adversarial noise conditions for the comparison and labeling oracles. Our lower bounds show that our label and total query complexity is almost optimal.
The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification
Nov 24, 2014
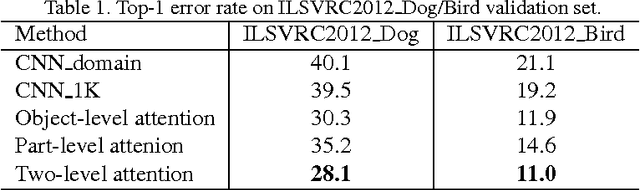
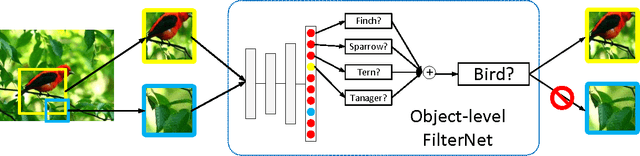
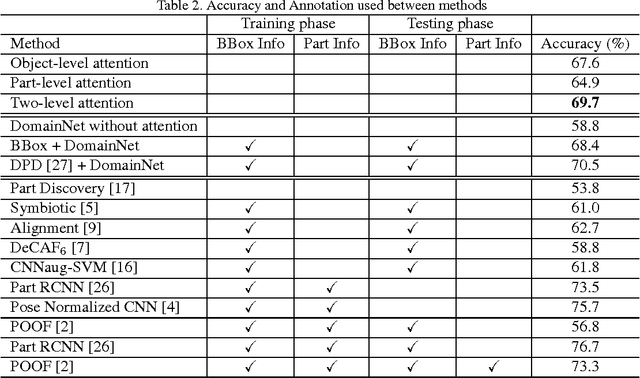
Fine-grained classification is challenging because categories can only be discriminated by subtle and local differences. Variances in the pose, scale or rotation usually make the problem more difficult. Most fine-grained classification systems follow the pipeline of finding foreground object or object parts (where) to extract discriminative features (what). In this paper, we propose to apply visual attention to fine-grained classification task using deep neural network. Our pipeline integrates three types of attention: the bottom-up attention that propose candidate patches, the object-level top-down attention that selects relevant patches to a certain object, and the part-level top-down attention that localizes discriminative parts. We combine these attentions to train domain-specific deep nets, then use it to improve both the what and where aspects. Importantly, we avoid using expensive annotations like bounding box or part information from end-to-end. The weak supervision constraint makes our work easier to generalize. We have verified the effectiveness of the method on the subsets of ILSVRC2012 dataset and CUB200_2011 dataset. Our pipeline delivered significant improvements and achieved the best accuracy under the weakest supervision condition. The performance is competitive against other methods that rely on additional annotations.