 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-swarm: A Decentralized Omnidirectional Visual-Inertial-UWB State Estimation System for Aerial Swarm
Apr 04, 2021
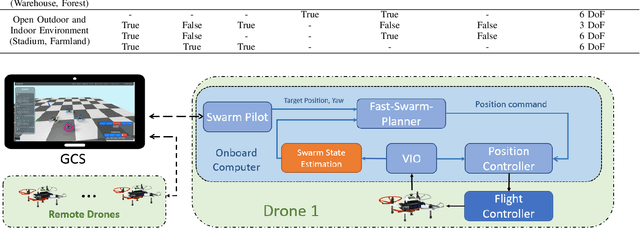
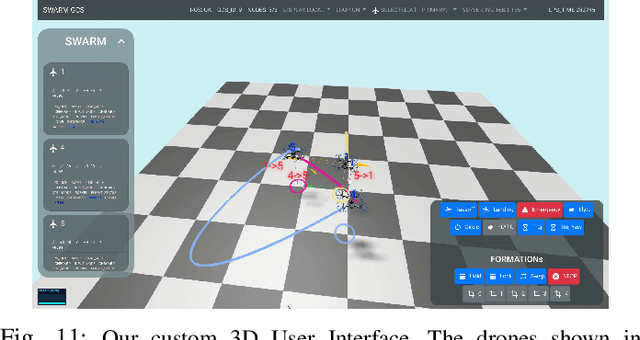
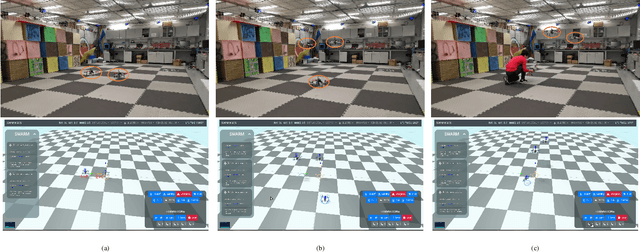
The decentralized state estimation is one of the most fundamental components for autonomous aerial swarm systems in GPS-denied areas, which still remains a highly challenging research topic. To address this research niche, the Omni-swarm, a decentralized omnidirectional visual-inertial-UWB state estimation system for the aerial swarm is proposed in this paper. In order to solve the issues of observability, complicated initialization, insufficient accuracy and lack of global consistency, we introduce an omnidirectional perception system as the front-end of the Omni-swarm, consisting of omnidirectional sensors, which includes stereo fisheye cameras and ultra-wideband (UWB) sensors, and algorithms, which includes fisheye visual inertial odometry (VIO), multi-drone map-based localization and visual object detector. A graph-based optimization and forward propagation working as the back-end of the Omni-swarm to fuse the measurements from the front-end. According to the experiment result, the proposed decentralized state estimation method on the swarm system achieves centimeter-level relative state estimation accuracy while ensuring global consistency. Moreover, supported by the Omni-swarm, inter-drone collision avoidance can be accomplished in a whole decentralized scheme without any external device, demonstrating the potential of Omni-swarm to be the foundation of autonomous aerial swarm flights in different scenarios.
Provably Correct Controller Synthesis of Switched Stochastic Systems with Metric Temporal Logic Specifications: A Case Study on Power Systems
Mar 26, 2021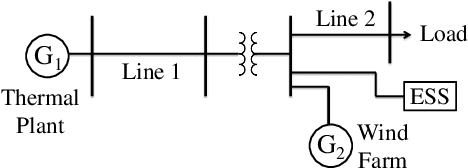
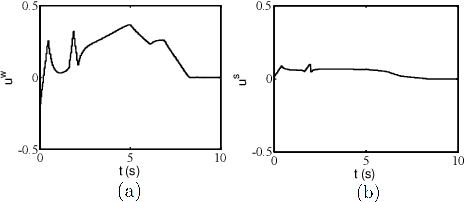
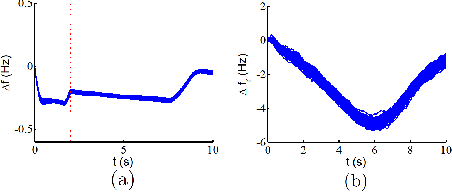
In this paper, we present a provably correct controller synthesis approach for switched stochastic control systems with metric temporal logic (MTL) specifications with provable probabilistic guarantees. We first present the stochastic control bisimulation function for switched stochastic control systems, which bounds the trajectory divergence between the switched stochastic control system and its nominal deterministic control system in a probabilistic fashion. We then develop a method to compute optimal control inputs by solving an optimization problem for the nominal trajectory of the deterministic control system with robustness against initial state variations and stochastic uncertainties. We implement our robust stochastic controller synthesis approach on both a four-bus power system and a nine-bus power system under generation loss disturbances, with MTL specifications expressing requirements for the grid frequency deviations, wind turbine generator rotor speed variations and the power flow constraints at different power lines.
Encoding Frequency Constraints in Preventive Unit Commitment Using Deep Learning with Region-of-Interest Active Sampling
Feb 18, 2021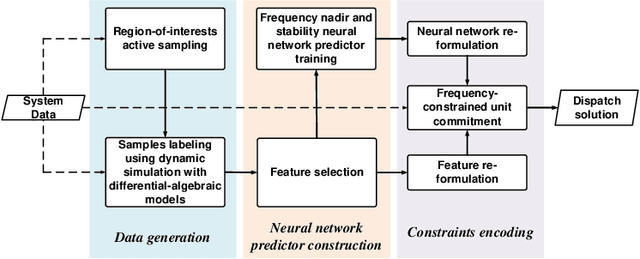
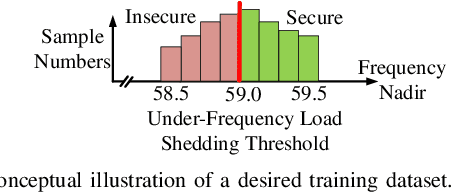
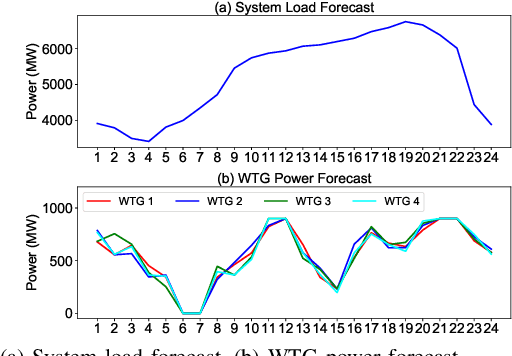
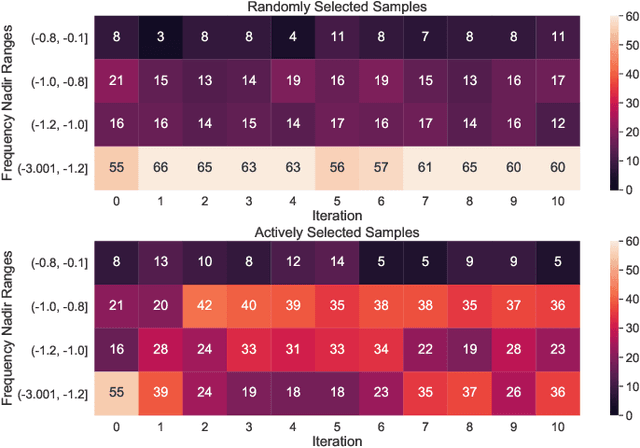
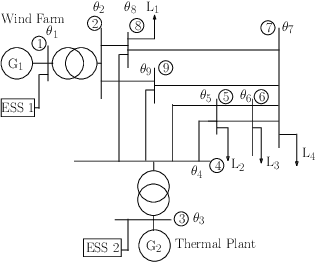
With the increasing penetration of renewable energy, frequency response and its security are of significant concerns for reliable power system operations. Frequency-constrained unit commitment (FCUC) is proposed to address this challenge. Despite existing efforts in modeling frequency characteristics in unit commitment (UC), current strategies can only handle oversimplified low-order frequency response models and do not consider wide-range operating conditions. This paper presents a generic data-driven framework for FCUC under high renewable penetration. Deep neural networks (DNNs) are trained to predict the frequency response using real data or high-fidelity simulation data. Next, the DNN is reformulated as a set of mixed-integer linear constraints to be incorporated into the ordinary UC formulation. In the data generation phase, all possible power injections are considered, and a region-of-interests active sampling is proposed to include power injection samples with frequency nadirs closer to the UFLC threshold, which significantly enhances the accuracy of frequency constraints in FCUC. The proposed FCUC is verified on the the IEEE 39-bus system. Then, a full-order dynamic model simulation using PSS/E verifies the effectiveness of FCUC in frequency-secure generator commitments.
Online Statistical Inference for Gradient-free Stochastic Optimization
Feb 05, 2021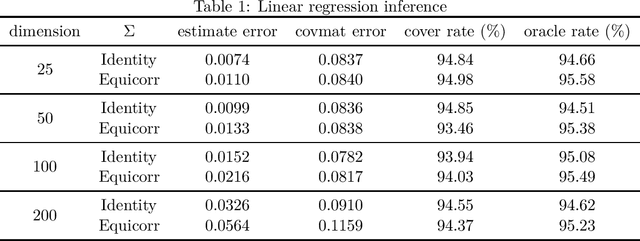
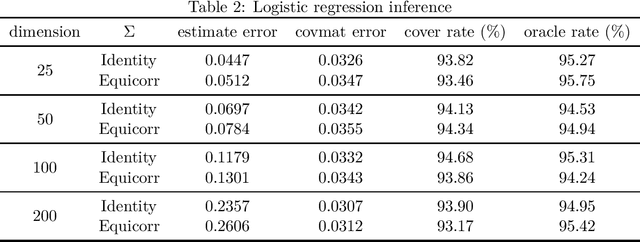
As gradient-free stochastic optimization gains emerging attention for a wide range of applications recently, the demand for uncertainty quantification of parameters obtained from such approaches arises. In this paper, we investigate the problem of statistical inference for model parameters based on gradient-free stochastic optimization methods that use only function values rather than gradients. We first present central limit theorem results for Polyak-Ruppert-averaging type gradient-free estimators. The asymptotic distribution reflects the trade-off between the rate of convergence and function query complexity. We next construct valid confidence intervals for model parameters through the estimation of the covariance matrix in a fully online fashion. We further give a general gradient-free framework for covariance estimation and analyze the role of function query complexity in the convergence rate of the covariance estimator. This provides a one-pass computationally efficient procedure for simultaneously obtaining an estimator of model parameters and conducting statistical inference. Finally, we provide numerical experiments to verify our theoretical results and illustrate some extensions of our method for various machine learning and deep learning applications.
Variance Reduction on Adaptive Stochastic Mirror Descent
Dec 26, 2020
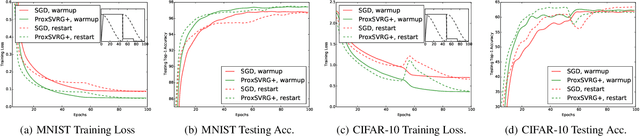
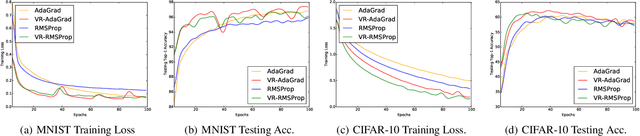
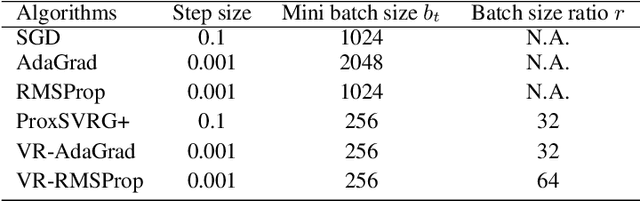
We study the idea of variance reduction applied to adaptive stochastic mirror descent algorithms in nonsmooth nonconvex finite-sum optimization problems. We propose a simple yet generalized adaptive mirror descent algorithm with variance reduction named SVRAMD and provide its convergence analysis in different settings. We prove that variance reduction reduces the gradient complexity of most adaptive mirror descent algorithms and boost their convergence. In particular, our general theory implies variance reduction can be applied to algorithms using time-varying step sizes and self-adaptive algorithms such as AdaGrad and RMSProp. Moreover, our convergence rates recover the best existing rates of non-adaptive algorithms. We check the validity of our claims using experiments in deep learning.
Hybrid Imitation Learning for Real-Time Service Restoration in Resilient Distribution Systems
Dec 04, 2020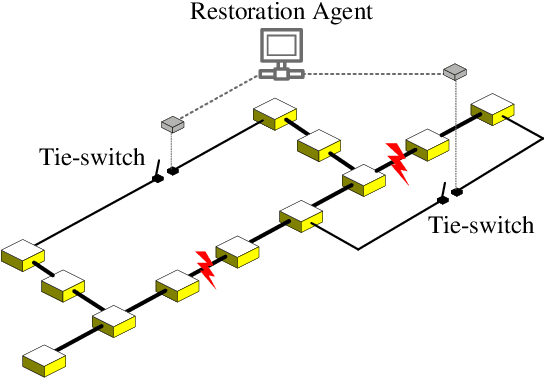
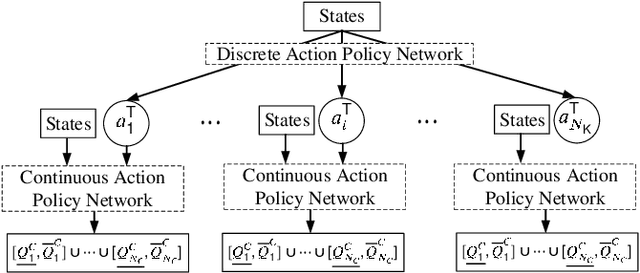
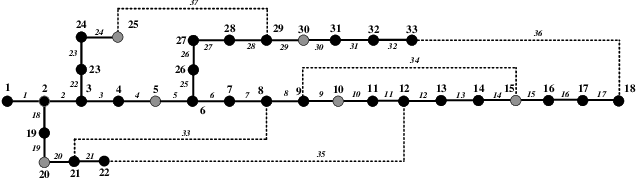
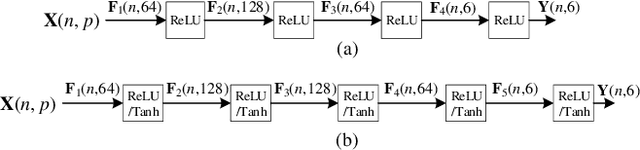
Self-healing capability is one of the most critical factors for a resilient distribution system, which requires intelligent agents to automatically perform restorative actions online, including network reconfiguration and reactive power dispatch. These agents should be equipped with a predesigned decision policy to meet real-time requirements and handle highly complex $N-k$ scenarios. The disturbance randomness hampers the application of exploration-dominant algorithms like traditional reinforcement learning (RL), and the agent training problem under $N-k$ scenarios has not been thoroughly solved. In this paper, we propose the imitation learning (IL) framework to train such policies, where the agent will interact with an expert to learn its optimal policy, and therefore significantly improve the training efficiency compared with the RL methods. To handle tie-line operations and reactive power dispatch simultaneously, we design a hybrid policy network for such a discrete-continuous hybrid action space. We employ the 33-node system under $N-k$ disturbances to verify the proposed framework.
FUEL: Fast UAV Exploration using Incremental Frontier Structure and Hierarchical Planning
Oct 22, 2020


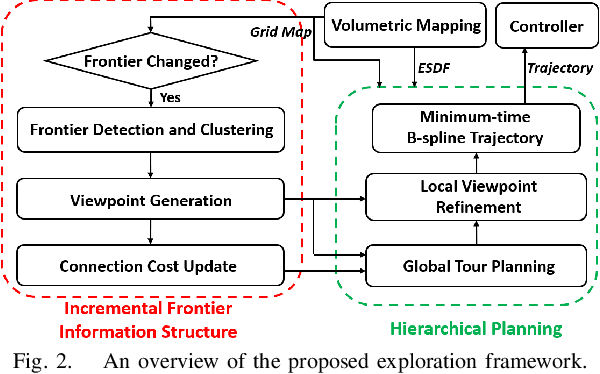
Autonomous exploration is a fundamental problem for various applications of unmanned aerial vehicles. Existing methods, however, were demonstrated to have low efficiency, due to the lack of optimality consideration, conservative motion plans and low decision frequencies. In this paper, we propose FUEL, a hierarchical framework that can support Fast UAV Exploration in complex unknown environments. We maintain crucial information in the entire space required by exploration planning by a frontier information structure (FIS), which can be updated incrementally when the space is explored. Supported by the FIS, a hierarchical planner plan exploration motions in three steps, which find efficient global coverage paths, refine a local set of viewpoints and generate minimum-time trajectories in sequence. We present extensive benchmark and real-world tests, in which our method completes the exploration tasks with unprecedented efficiency (3-8 times faster) compared to state-of-the-art approaches. Our method will be made open source to benefit the community.
Pathological Visual Question Answering
Oct 06, 2020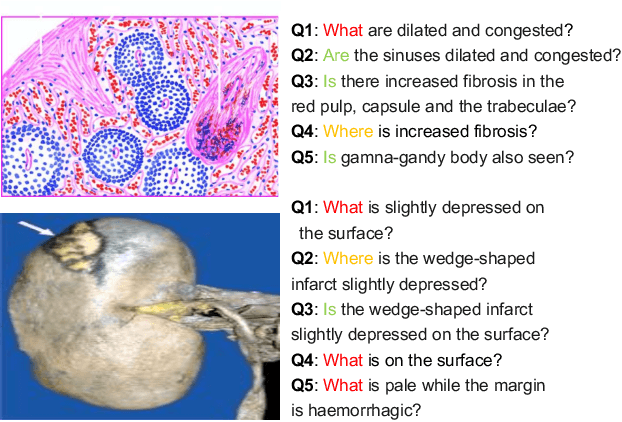
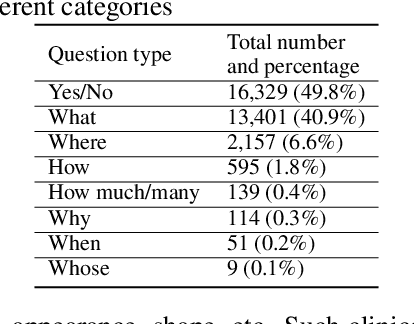
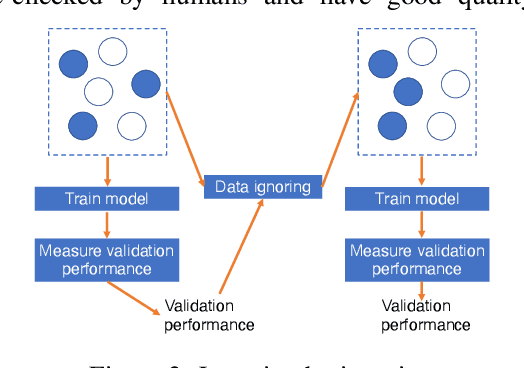
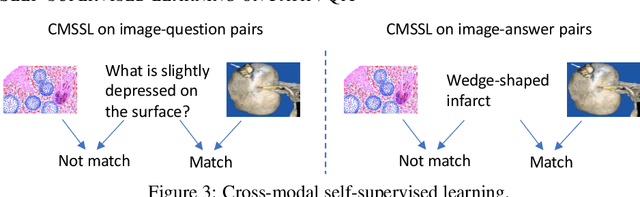
Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology (ABP)? To build such a system, three challenges need to be addressed. First, we need to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Due to privacy concerns, pathology images are usually not publicly available. Besides, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. The second challenge is: since it is difficult to hire highly experienced pathologists to create pathology visual questions and answers, the resulting pathology VQA dataset may contain errors. Training pathology VQA models using these noisy or even erroneous data will lead to problematic models that cannot generalize well on unseen images. The third challenge is: the medical concepts and knowledge covered in pathology question-answer (QA) pairs are very diverse while the number of QA pairs available for modeling training is limited. How to learn effective representations of diverse medical concepts based on limited data is technically demanding. In this paper, we aim to address these three challenges. To our best knowledge, our work represents the first one addressing the pathology VQA problem. To deal with the issue that a publicly available pathology VQA dataset is lacking, we create PathVQA dataset. To address the second challenge, we propose a learning-by-ignoring approach. To address the third challenge, we propose to use cross-modal self-supervised learning. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed learning-by-ignoring method and cross-modal self-supervised learning methods.
Deep Active Learning for Solvability Prediction in Power Systems
Jul 27, 2020
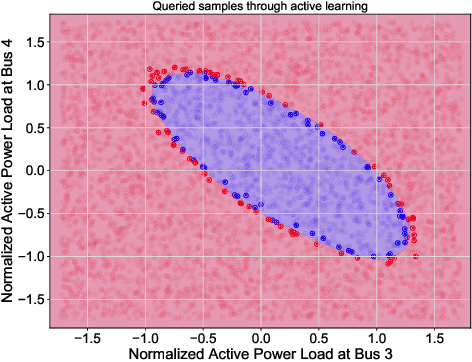
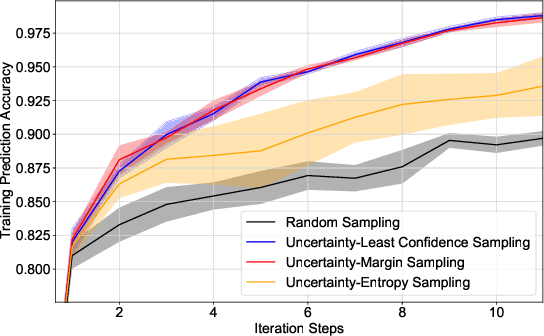
Traditional methods for solvability region analysis can only have inner approximations with inconclusive conservatism. Machine learning methods have been proposed to approach the real region. In this letter, we propose a deep active learning framework for power system solvability prediction. Compared with the passive learning methods where the training is performed after all instances are labeled, the active learning selects most informative instances to be label and therefore significantly reduce the size of labeled dataset for training. In the active learning framework, the acquisition functions, which correspond to different sampling strategies, are defined in terms of the on-the-fly posterior probability from the classifier. The IEEE 39-bus system is employed to validate the proposed framework, where a two-dimensional case is illustrated to visualize the effectiveness of the sampling method followed by the full-dimensional numerical experiments.
COVID-CT-Dataset: A CT Scan Dataset about COVID-19
Mar 30, 2020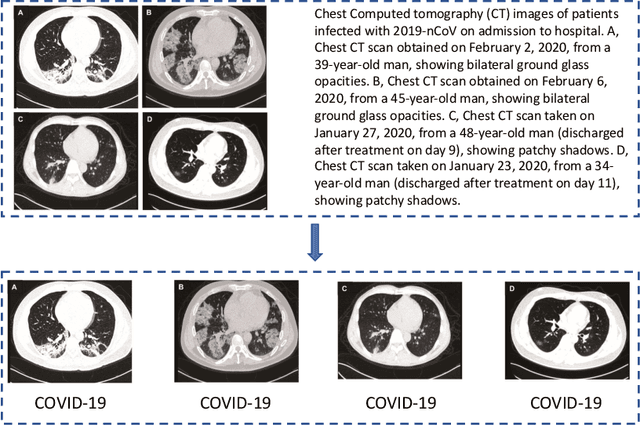
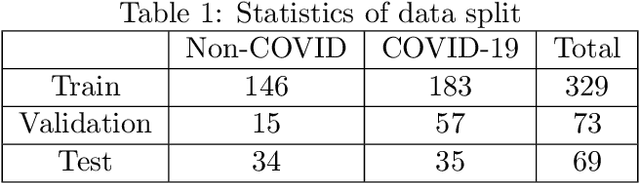
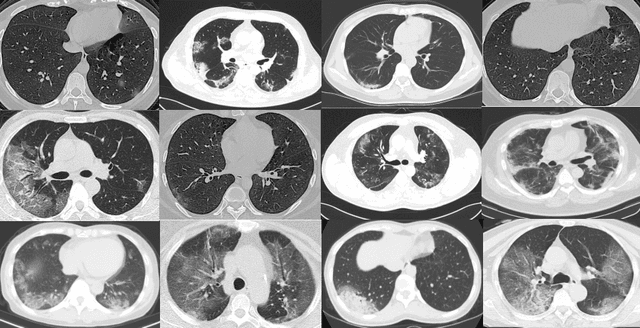
CT scans are promising in providing accurate, fast, and cheap screening and testing of COVID-19. In this paper, we build a publicly available COVID-CT dataset, containing 275 CT scans that are positive for COVID-19, to foster the research and development of deep learning methods which predict whether a person is affected with COVID-19 by analyzing his/her CTs. We train a deep convolutional neural network on this dataset and achieve an F1 of 0.85 which is a promising performance but yet to be further improved. The data and code are available at https://github.com/UCSD-AI4H/COVID-CT