 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Collapse Inspired Federated Learning with Non-iid Data
Mar 31, 2023



One of the challenges in federated learning is the non-independent and identically distributed (non-iid) characteristics between heterogeneous devices, which cause significant differences in local updates and affect the performance of the central server. Although many studies have been proposed to address this challenge, they only focus on local training and aggregation processes to smooth the changes and fail to achieve high performance with deep learning models. Inspired by the phenomenon of neural collapse, we force each client to be optimized toward an optimal global structure for classification. Specifically, we initialize it as a random simplex Equiangular Tight Frame (ETF) and fix it as the unit optimization target of all clients during the local updating. After guaranteeing all clients are learning to converge to the global optimum, we propose to add a global memory vector for each category to remedy the parameter fluctuation caused by the bias of the intra-class condition distribution among clients. Our experimental results show that our method can improve the performance with faster convergence speed on different-size datasets.
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
General Rotation Invariance Learning for Point Clouds via Weight-Feature Alignment
Feb 20, 2023



Compared to 2D images, 3D point clouds are much more sensitive to rotations. We expect the point features describing certain patterns to keep invariant to the rotation transformation. There are many recent SOTA works dedicated to rotation-invariant learning for 3D point clouds. However, current rotation-invariant methods lack generalizability on the point clouds in the open scenes due to the reliance on the global distribution, \ie the global scene and backgrounds. Considering that the output activation is a function of the pattern and its orientation, we need to eliminate the effect of the orientation.In this paper, inspired by the idea that the network weights can be considered a set of points distributed in the same 3D space as the input points, we propose Weight-Feature Alignment (WFA) to construct a local Invariant Reference Frame (IRF) via aligning the features with the principal axes of the network weights. Our WFA algorithm provides a general solution for the point clouds of all scenes. WFA ensures the model achieves the target that the response activity is a necessary and sufficient condition of the pattern matching degree. Practically, we perform experiments on the point clouds of both single objects and open large-range scenes. The results suggest that our method almost bridges the gap between rotation invariance learning and normal methods.
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class Incremental Learning
Feb 06, 2023Few-shot class-incremental learning (FSCIL) has been a challenging problem as only a few training samples are accessible for each novel class in the new sessions. Finetuning the backbone or adjusting the classifier prototypes trained in the prior sessions would inevitably cause a misalignment between the feature and classifier of old classes, which explains the well-known catastrophic forgetting problem. In this paper, we deal with this misalignment dilemma in FSCIL inspired by the recently discovered phenomenon named neural collapse, which reveals that the last-layer features of the same class will collapse into a vertex, and the vertices of all classes are aligned with the classifier prototypes, which are formed as a simplex equiangular tight frame (ETF). It corresponds to an optimal geometric structure for classification due to the maximized Fisher Discriminant Ratio. We propose a neural collapse inspired framework for FSCIL. A group of classifier prototypes are pre-assigned as a simplex ETF for the whole label space, including the base session and all the incremental sessions. During training, the classifier prototypes are not learnable, and we adopt a novel loss function that drives the features into their corresponding prototypes. Theoretical analysis shows that our method holds the neural collapse optimality and does not break the feature-classifier alignment in an incremental fashion. Experiments on the miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our proposed framework outperforms the state-of-the-art performances. Code address: https://github.com/NeuralCollapseApplications/FSCIL
DeMT: Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
Jan 12, 2023Convolution neural networks (CNNs) and Transformers have their own advantages and both have been widely used for dense prediction in multi-task learning (MTL). Most of the current studies on MTL solely rely on CNN or Transformer. In this work, we present a novel MTL model by combining both merits of deformable CNN and query-based Transformer for multi-task learning of dense prediction. Our method, named DeMT, is based on a simple and effective encoder-decoder architecture (i.e., deformable mixer encoder and task-aware transformer decoder). First, the deformable mixer encoder contains two types of operators: the channel-aware mixing operator leveraged to allow communication among different channels ($i.e.,$ efficient channel location mixing), and the spatial-aware deformable operator with deformable convolution applied to efficiently sample more informative spatial locations (i.e., deformed features). Second, the task-aware transformer decoder consists of the task interaction block and task query block. The former is applied to capture task interaction features via self-attention. The latter leverages the deformed features and task-interacted features to generate the corresponding task-specific feature through a query-based Transformer for corresponding task predictions. Extensive experiments on two dense image prediction datasets, NYUD-v2 and PASCAL-Context, demonstrate that our model uses fewer GFLOPs and significantly outperforms current Transformer- and CNN-based competitive models on a variety of metrics. The code are available at https://github.com/yangyangxu0/DeMT .
PanopticPartFormer++: A Unified and Decoupled View for Panoptic Part Segmentation
Jan 03, 2023



Panoptic Part Segmentation (PPS) unifies panoptic segmentation and part segmentation into one task. Previous works utilize separated approaches to handle thing, stuff, and part predictions without shared computation and task association. We aim to unify these tasks at the architectural level, designing the first end-to-end unified framework named Panoptic-PartFormer. Moreover, we find the previous metric PartPQ biases to PQ. To handle both issues, we make the following contributions: Firstly, we design a meta-architecture that decouples part feature and things/stuff feature, respectively. We model things, stuff, and parts as object queries and directly learn to optimize all three forms of prediction as a unified mask prediction and classification problem. We term our model as Panoptic-PartFormer. Secondly, we propose a new metric Part-Whole Quality (PWQ) to better measure such task from both pixel-region and part-whole perspectives. It can also decouple the error for part segmentation and panoptic segmentation. Thirdly, inspired by Mask2Former, based on our meta-architecture, we propose Panoptic-PartFormer++ and design a new part-whole cross attention scheme to further boost part segmentation qualities. We design a new part-whole interaction method using masked cross attention. Finally, the extensive ablation studies and analysis demonstrate the effectiveness of both Panoptic-PartFormer and Panoptic-PartFormer++. Compared with previous Panoptic-PartFormer, our Panoptic-PartFormer++ achieves 2% PartPQ and 3% PWQ improvements on the Cityscapes PPS dataset and 5% PartPQ on the Pascal Context PPS dataset. On both datasets, Panoptic-PartFormer++ achieves new state-of-the-art results with a significant cost drop of 70% on GFlops and 50% on parameters. Our models can serve as a strong baseline and aid future research in PPS. Code will be available.
Understanding Imbalanced Semantic Segmentation Through Neural Collapse
Jan 03, 2023A recent study has shown a phenomenon called neural collapse in that the within-class means of features and the classifier weight vectors converge to the vertices of a simplex equiangular tight frame at the terminal phase of training for classification. In this paper, we explore the corresponding structures of the last-layer feature centers and classifiers in semantic segmentation. Based on our empirical and theoretical analysis, we point out that semantic segmentation naturally brings contextual correlation and imbalanced distribution among classes, which breaks the equiangular and maximally separated structure of neural collapse for both feature centers and classifiers. However, such a symmetric structure is beneficial to discrimination for the minor classes. To preserve these advantages, we introduce a regularizer on feature centers to encourage the network to learn features closer to the appealing structure in imbalanced semantic segmentation. Experimental results show that our method can bring significant improvements on both 2D and 3D semantic segmentation benchmarks. Moreover, our method ranks 1st and sets a new record (+6.8% mIoU) on the ScanNet200 test leaderboard. Code will be available at https://github.com/dvlab-research/Imbalanced-Learning.
Demystify Problem-Dependent Power of Quantum Neural Networks on Multi-Class Classification
Dec 29, 2022



Quantum neural networks (QNNs) have become an important tool for understanding the physical world, but their advantages and limitations are not fully understood. Some QNNs with specific encoding methods can be efficiently simulated by classical surrogates, while others with quantum memory may perform better than classical classifiers. Here we systematically investigate the problem-dependent power of quantum neural classifiers (QCs) on multi-class classification tasks. Through the analysis of expected risk, a measure that weighs the training loss and the generalization error of a classifier jointly, we identify two key findings: first, the training loss dominates the power rather than the generalization ability; second, QCs undergo a U-shaped risk curve, in contrast to the double-descent risk curve of deep neural classifiers. We also reveal the intrinsic connection between optimal QCs and the Helstrom bound and the equiangular tight frame. Using these findings, we propose a method that uses loss dynamics to probe whether a QC may be more effective than a classical classifier on a particular learning task. Numerical results demonstrate the effectiveness of our approach to explain the superiority of QCs over multilayer Perceptron on parity datasets and their limitations over convolutional neural networks on image datasets. Our work sheds light on the problem-dependent power of QNNs and offers a practical tool for evaluating their potential merit.
Towards Theoretically Inspired Neural Initialization Optimization
Oct 12, 2022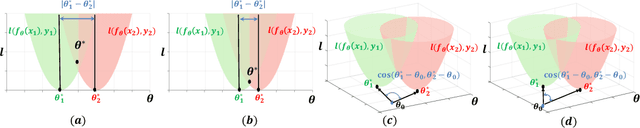
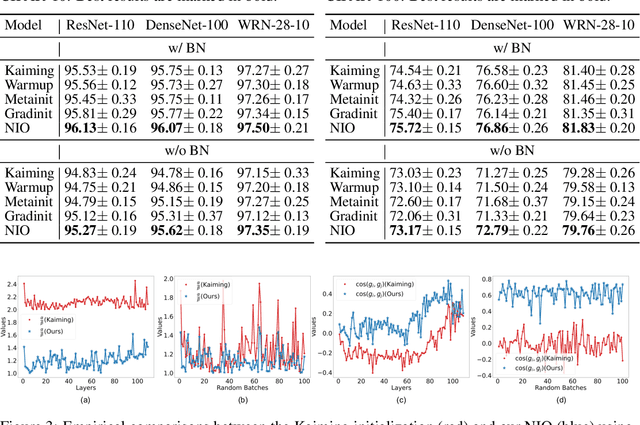


Automated machine learning has been widely explored to reduce human efforts in designing neural architectures and looking for proper hyperparameters. In the domain of neural initialization, however, similar automated techniques have rarely been studied. Most existing initialization methods are handcrafted and highly dependent on specific architectures. In this paper, we propose a differentiable quantity, named GradCosine, with theoretical insights to evaluate the initial state of a neural network. Specifically, GradCosine is the cosine similarity of sample-wise gradients with respect to the initialized parameters. By analyzing the sample-wise optimization landscape, we show that both the training and test performance of a network can be improved by maximizing GradCosine under gradient norm constraint. Based on this observation, we further propose the neural initialization optimization (NIO) algorithm. Generalized from the sample-wise analysis into the real batch setting, NIO is able to automatically look for a better initialization with negligible cost compared with the training time. With NIO, we improve the classification performance of a variety of neural architectures on CIFAR-10, CIFAR-100, and ImageNet. Moreover, we find that our method can even help to train large vision Transformer architecture without warmup.
Eliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 20, 2022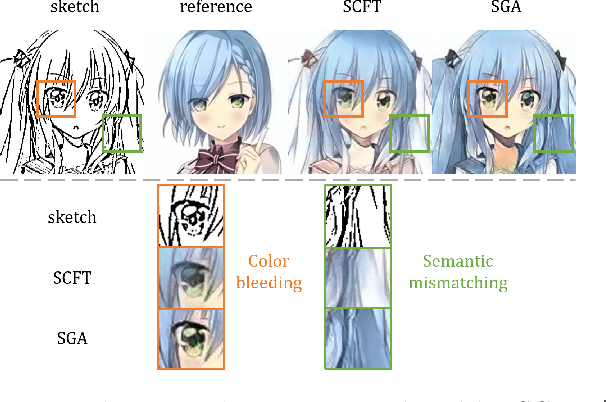
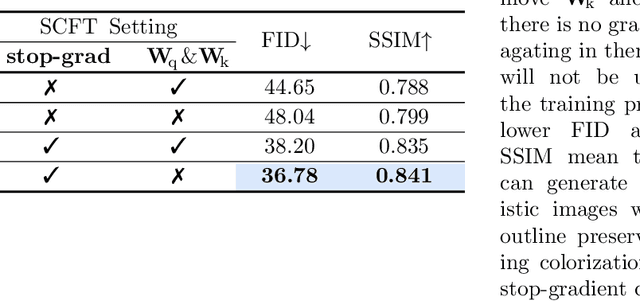
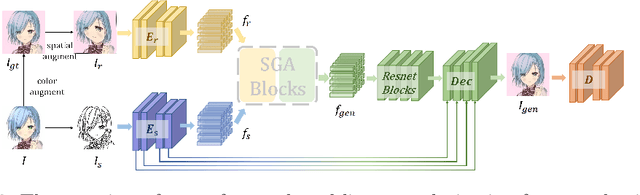
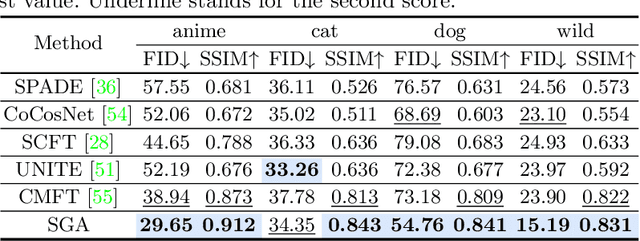
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .